Release 5.2.0
Copyright © 2019 DF/Net Research, Inc.
All rights reserved. No part of this publication may be re-transmitted in any form or by any means, electronic, mechanical, photocopying, recording, or otherwise, without the prior written permission of DF/Net Research, Inc.. Permission is granted for internal re-distribution of this publication by the license holder and their employees for internal use only, provided that the copyright notices and this permission notice appear in all copies.
The information in this document is furnished for informational use only and is subject to change without notice. DF/Net Research, Inc. assumes no responsibility or liability for any errors or inaccuracies in this document or for any omissions from it.
All products or services mentioned in this document are covered by the trademarks, service marks, or product names as designated by the companies who market those products.
Google Play and the Google Play logo are trademarks of Google LLC. Android is a trademark of Google LLC.
App Store is a trademark of Apple Inc.
Nov 01, 2019
Abstract
This guide describes the DFexplore application.
The instructions are intended to describe, in general terms, how data management tasks are performed using DFexplore. The guidance provided here is not meant to replace more specific instructions which may be provided by the sponsor, principal investigator or coordinating site for a particular trial.
Table of Contents
- Preface
- 1. Introduction
- 1.1. What is DFexplore?
- 1.2. What type of computer do I need?
- 1.3. What type of web browser do I need?
- 1.4. Is data transmission over the internet secure?
- 1.5. What kind of response time can I expect?
- 1.6. How complicated is this going to be?
- 1.7. Is any subject data stored on my local hard drive?
- 1.8. Can anyone impersonate me within DFexplore?
- 1.9. What if I forget my password?
- 1.10. How hard is it to navigate among the various study forms for each subject?
- 1.11. Can I use DFexplore for more than one study at a time?
- 1.12. If I don't like this, or don't have time for it, can I switch to another method of data collection / entry?
- 1.13. How do I get started?
- 1.14. After I connect to a study how do I enter subject data?
- 1.15. What do I do when I'm finished entering subject data?
- 2. A Guided Tour
- 3. Using DFexplore
- 3.1. How do I select the correct subject binder for a new subject?
- 3.2. Can I print a copy of a subject binder?
- 3.3. How do I confirm that I am the only person making changes?
- 3.4. How can I make sure that I am completing the data forms correctly?
- 3.5. Can I enter a reason to explain an unusual value or a value that I have changed?
- 3.6. Can I use standard missing value codes?
- 3.7. What are queries and where do they come from?
- 3.8. How do I find all outstanding queries?
- 3.9. How do I respond to queries?
- 3.10. Can I respond to a query by adding a reason for the data value?
- 3.11. How should I respond to a query if the data field is correct as is?
- 3.12. Can I indicate that a subject visit is unavailable?
- 3.13. Can I indicate that a page is unavailable?
- 3.14. Do I need to save the changes I have made?
- 3.15. Can I undo all changes I just made to a page?
- 3.16. What is the best way to find all outstanding problems?
- 3.17. Why did my DFexplore session Auto Logout?
- 3.18. How do I exit from DFexplore?
- 3.19. What should I do if I have questions?
- 4. Dashboard View
- 5. Data View
- 5.1. Subject Binders
- 5.2. Metadata: Queries, Reasons and Missing Values
- 5.3. Data Field Colors
- 5.4. Entering Data and Metadata
- 5.5. Saving Data and Metadata
- 5.6. Correcting Key Fields
- 5.7. Images of CRFs and other documents
- 5.8. Image Option Buttons
- 5.9. High Definition (HD) Images Setting
- 5.10. Working with Tasks
- 5.11. Ad hoc Record Selection
- 5.12. Using Lookup Tables
- 5.13. Query Management
- 5.14. Review/Approve Queries and Reasons
- 5.15. Transmitting Scanned CRFs
- 5.16. Importing Subject CRFs
- 5.17. Creating Subject Packages
- 5.18. Data View Menus
- 6. Queries View
- 7. Reasons View
- 8. Image View
- 9. List View
- 9.1. Introduction
- 9.2. User Preferences
- 9.3. Navigation
- 9.4. Working on a Task
- 9.5. Selecting Data Fields
- 9.6. Searching Data Records
- 9.7. Functions
- 9.8. Saving Defined Views
- 9.9. Exporting Data Records
- 9.10. Exporting a Data Retrieval File
- 9.11. Exporting SAS Data Sets
- 9.12. Importing Data Records
- 9.13. Metadata - Queries, Reasons, Query Reports and Missed Records
- 9.14. List View Menus
- 10. Reports View
- 11. Schedule View
- 12. Status View
- 13. Batch Edits View
- 14. Image Router
- 15. User Settings
- A. Terminology, Shortcuts, Acknowledgements and Copyrights
- A.1. Terminology
- A.2. DFexplore Keyboard Shortcuts
- A.3. Common Error and Warning Messages
- A.4. Programs
- A.5. Selecting Subjects based on Criteria
- A.6. CDISC ODM Export
- A.7. External Software Copyrights
- A.7.1. DCMTK software package
- A.7.2. Jansson License
- A.7.3. Mimencode
- A.7.4. RSA Data Security, Inc., MD5 message-digest algorithm
- A.7.5. mpack/munpack
- A.7.6. TIFF
- A.7.7. PostgreSQL
- A.7.8. OpenSSL License
- A.7.9. Original SSLeay License
- A.7.10. gawk
- A.7.11. Ghostscript
- A.7.12. MariaDB and FreeTDS
- A.7.13. QtAV
- A.7.14. FFmpeg
- A.7.15. c3.js
- A.7.16. d3.js
Images in this document are of DFexplore in a Windows 10 environment. Functionality is identical on all operating systems, and images are identical, except for window decorations.
A number of conventions have been used throughout this document:
Text on user interface labels or menus is shown as: Printer name, while buttons in user interfaces are shown as .
Menus and menu items are shown as: > .
Emphasized words are shown as follows: emphasized words.
Filenames appear in the text like so:
dummy.c.Code, constants, and literals in the text appear like so:
main.Variable names appear in the text like so:
nBytes.
Table of Contents
- 1.1. What is DFexplore?
- 1.2. What type of computer do I need?
- 1.3. What type of web browser do I need?
- 1.4. Is data transmission over the internet secure?
- 1.5. What kind of response time can I expect?
- 1.6. How complicated is this going to be?
- 1.7. Is any subject data stored on my local hard drive?
- 1.8. Can anyone impersonate me within DFexplore?
- 1.9. What if I forget my password?
- 1.10. How hard is it to navigate among the various study forms for each subject?
- 1.11. Can I use DFexplore for more than one study at a time?
- 1.12. If I don't like this, or don't have time for it, can I switch to another method of data collection / entry?
- 1.13. How do I get started?
- 1.14. After I connect to a study how do I enter subject data?
- 1.15. What do I do when I'm finished entering subject data?
DFexplore is a computer application used to enter, review and modify subject data, and to submit it over the internet to a DFdiscover server at the study coordinating site. This type of data entry is commonly referred to as Electronic Data Capture or EDC. DFexplore is part of the DFdiscover clinical trial management system, which also supports data collection by paper, scanned document and fax. All methods can be used in the same study. EDC has been described as having the advantage of providing immediate help to data collection users, resulting in more complete and accurate data entry, and fewer queries from the study coordinating site.
To help realize these benefits and facilitate the transition from paper forms to EDC, DFexplore has been designed with:
intuitive navigation, using a subject binder analogy,
data entry screens that can match the equivalent paper forms,
help in the form of status icons, color coding, messages and interactive edit checks,
a Query window used to read and respond to queries from the study coordinating site,
a Reason window used to explain unusual data values (and thus avoid queries), and
a Missing Value window used to mark fields with standard missing value codes
Versions of DFexplore are available for: Windows 10, macOS v10.13 or later, and Linux. If you plan to use DFexplore on more than one computer you will need to install the appropriate version on each computer.
Your trial coordinating site may have more detailed instructions regarding computer needs.
DFexplore is a standalone application. It does not rely on a specific web browser. It is downloaded and run on your local computer.
DFexplore can also be deployed through an application server hosted by the study sponsor. This deployment, known as DFnavigator, works in current versions of the Edge, Chrome, Firefox and Safari browsers, and possibly others.
DFexplore communicates with the DFdiscover server via encrypted communication on port 443. This port must be open on any firewalls between the local computer and the study server.
The security of the communication is based upon 3 industry standard technologies:
Communication protocols, namely TLS 1.2 or 1.3,
Strong encryption ciphers, and
Independent certification and confirmation of the server.
This is industry-standard technology that encrypts the bi-directional communication using a 'certificate of trust' provided by the server. It is the same technology used by banks and the majority of secure, global web services.
You can visually confirm that the communication is secure by examining the details of the communication protocol and encryption cipher. Click the green lock icon next to the DFdiscover Server during login.
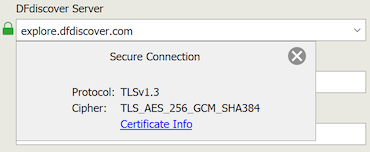
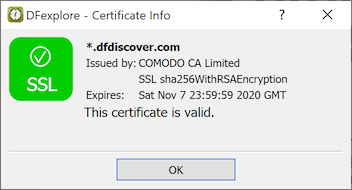
You can also examine the certificate of trust. After login, select > and look for the green checkmark.
As with all internet applications, response time and speed depends primarily on the speed of and traffic on your internet connection, and to a lesser extent on the distance between you and the study DFdiscover server (the distance itself is not the factor, but is generally impacted by the number of intermediate connections between the endpoints, and that can be a factor).
If you have a cable internet connection, you can expect login times in the range of 5 to 20 seconds and then 1 to 4 seconds to display each new page in the data entry window. Fibre connections are much quicker. Once a page is on the screen, moving between data fields is very fast, with essentially no delay.
With a little practice, you should find that completing data collection pages in DFexplore is as easy as completing a printed version of the same page. In addition, the guidance provided by color coding (e.g. illegal values appear red) and the messages displayed by data consistency checks help you identify problems that can be corrected immediately or explained by entering a reason for unusual values. This advantage over paper forms helps you avoid queries and requests for corrections from the study coordinating site, thus saving you time in the long run.
No; all subject data is sent to and retrieved from the DFdiscover server. As a result, you can access the study from any computer on which DFexplore has been installed. Different users can access their studies from shared computer(s), as each user is uniquely identified by a username and password combination.
Your username plus a password constitute your unique electronic signature. By protecting your electronic signature, and making sure you logout of DFexplore before leaving a computer, you can ensure that no one can impersonate you and perform data entry that is attributed to you.
Permission to read, write and modify subject data is defined by the study coordinating site for each username. These permissions determine which study, sites, subjects, visits and individual data pages each user can create, view and modify. It would not be uncommon for more than one person to have permission to enter data for the same subject at a given clinical site; however, all data entry is recorded with your username, date and time. Thus a complete history is maintained of all database transactions.
You can independently reset your password provided that:
you have a current email address registered on the server you are trying to access, and
the sponsor has enabled resetting of passwords from the login dialog on that server.
If these conditions are satisfied, to reset your password:
Enter the value for DFdiscover Server in the login dialog.
Click Reset Password near the top of the login screen.
In the Reset Password dialog, enter your email address; [1] this must match the email address previously defined for you on this server.
Click .
A temporary single-use password is emailed to the email address. Please allow several minutes for that email to arrive.
Use the single-use password to complete the login. Thereafter you will need to specify, and confirm, a new permanent password.
If
you do not have a current email address registered on the sponsor's server, or
the sponsor has not enabled resetting of passwords from the login dialog on that server,
please directly contact the sponsor's DFdiscover administrator for assistance in resetting your password.
A subject binder, complete with printed forms organized by study visits from beginning to end, with tabs identifying each visit, is quite easy to use.
DFexplore follows this subject binder analogy in Data View. When you open a clinical site (like walking into your office) you see a list of subject icons (like subject binders on a shelf). Double-clicking a subject icon opens the binder to reveal the list of visits that comprise all subject visits from beginning to end of the study.
Double-clicking a visit opens that section of the binder to show the data collection pages for that visit. When you are finished reviewing or entering data, double-clicking an open visit or subject binder closes it.
Each visit, and page within a visit, has a text label describing what it is, and colored icons that identify whether it is required or optional, blank or containing data, and, if data is present, whether it is complete or incomplete.
In addition to the Data View, there is a Queries View that lets you review data queries from the central office and jump to each relevant data field, where you can enter a reply, explain or correct the data value.
This familiar organization, along with the use of icons and color, makes navigating the study forms as easy as using a printed subject binder - perhaps even easier.
Yes. The login screen asks you to specify the unique name of the DFdiscover server at the study coordinating site. Once you connect to the desired server you see a list of all studies you are permitted to access.
It is possible to participate in one or more studies with a single coordinating site and also possible to participate in studies at more than one coordinating site. In all cases the software behaves the same; only the study data entry forms differ.
DFdiscover is capable of supporting EDC and paper data collection forms (faxed, scanned, emailed) within the same study, with no additional study setup work. Further, the design of the paper forms and data screens are identical and are completed in the same step; thus switching a clinical site from DFexplore to completing and scanning paper forms is certainly possible, and provides a fall-back position for sites that are unable to perform EDC. Of course, it is also possible to move in the other direction, switching from paper and scanning to EDC.
First you need to download and install DFexplore following the instructions provided by the study coordinating site.
After installation, on starting DFexplore and in the login dialog, enter the name of the DFdiscover server, your username, and your password; all of these values are provided by the study coordinating site.
After successful login you are presented a list of the studies in which you are participating, each with a status indicating whether the study is currently available or off-line for maintenance. If a study is available, double-clicking the study entry connects to the study database.
If you are not already in the Data View, select > . The clinical sites for which you have permission are listed on the left side of the screen. Double-clicking a site opens it to reveal the list of subject binders. Double-clicking a subject binder opens it to reveal the study visit tabs, and double-clicking a tab opens the visit to reveal the data entry pages for that visit. You can then enter data, add reasons to explain unusual values, and reply to outstanding queries.
When you are finished with a page, to save your work in the study database at the coordinating site, click one of 3 save buttons at the bottom of the data entry window: (to indicate that data entry is complete), (to indicate that some fields are incomplete or some queries remain to be answered), or (to indicate that you have not yet finished your work with the page and want to finish it before it is reviewed by the study coordinating site).
You can close a visit by double-clicking the open visit tab, and close a subject by double-clicking the subject icon. Only one subject binder can be open at a time; opening a new one automatically closes the open one (if any). When you are finished entering data for all subjects, logout by selecting > .
[1] There is an inactivity timer on the Reset Password dialog. Please enter your email address within 60 seconds; otherwise, the dialog is dismissed and no request is sent.
Table of Contents
This chapter provides a brief introduction to DFexplore. It begins with a description of how to login to a DFdiscover study server, and then describes each of the major components in the application.
To work in a study database you must first start DFexplore and login to the DFdiscover server where the study data and configuration information are stored. This requires an internet connection. The study coordinating site will have provided you with:
-
the DFexplore application (Windows 10, macOS v10.13 or later and Linux versions are available),
-
the name of the DFdiscover server,
-
your username,
-
your initial password, and
-
the name of the study (or studies) for which you have permission to access on the DFdiscover server.
The login process involves authenticating to the DFdiscover server and then selecting the study with which to work.
The initial login dialog has the following appearance. The left-side panel shows 3 input fields for DFdiscover Server, your Username and your Password. The right-side panel shows the software logo and version. The contents of this panel can also be customized by the system administrator. A ribbon of clickable options stretches across the top of both panels.

In the left-side panel, enter the value for the DFdiscover Server. If the system administrator has defined a customized login screen, the contents of the right-side panel refresh to show this screen. A green lock icon also appears next to the DFdiscover Server field. The icon is confirmation that a secure connection with the server has been established. Optionally, click the icon and review the details of the connection.
Enter your Username and Password.

Notice that your password is obscured as you type it.
This is a standard security practice to ensure that anyone
else looking at your screen cannot see the entered password.
If Caps Lock is enabled on the keyboard,
the message Caps Lock is On appears as a
tooltip as the password is typed. It does not appear
for any other field in the application.
If your IT department has installed a proxy server
(to filter requests sent to other servers on the internet),
click the proxy server configuration button
(  ) to access the
Configure Proxy Server dialog.
You will need the specific configuration values from your IT
department.
) to access the
Configure Proxy Server dialog.
You will need the specific configuration values from your IT
department.
Click .
DFexplore remembers the most recent servers (and proxy servers) you have specified, so you will only need to enter this information once, but your username and password need to be entered each time you login.
The first time you connect to a DFdiscover server you are prompted to change your password. All data entered and modified is recorded under each user's username. Be vigilant to protect your username and password.
If you forget your password, you can reset it to a single-use temporary password from the login dialog. The new password is emailed to you provided that: this service is allowed on the server, and there is a matching email address registered on the server.
DFexplore includes password aging, an FDA regulatory requirement. After the expiry period has elapsed, you are prompted to reset your password the next time you login.
If login is successful the study selection dialog is presented, with a list of studies you have permission to access on the DFdiscover server. Each study is identified by a unique number, name and current status (available or offline).
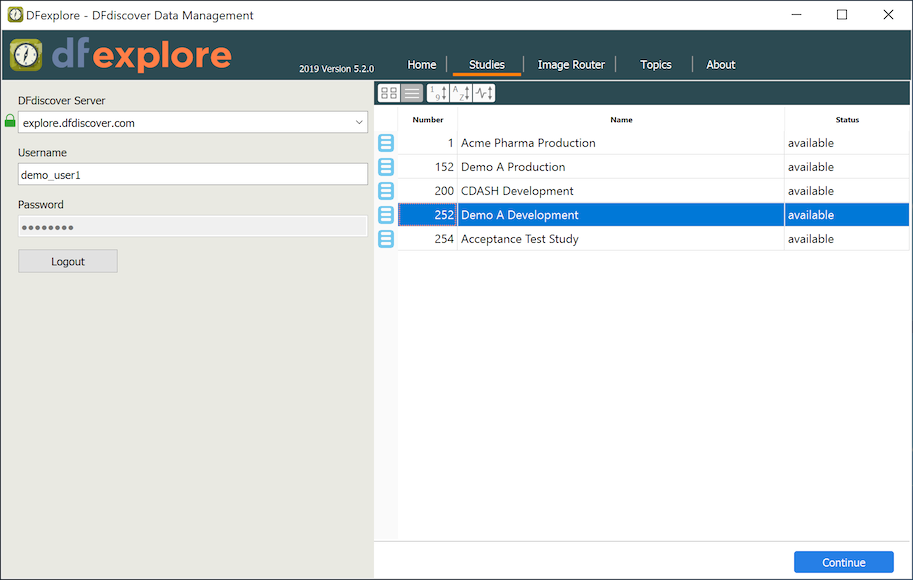
To work on a study, double-click the study name, or highlight it and click .
![[Note]](../../imagedata/note.png) | Note |
|---|---|
Your permissions may be such that you have access to exactly one study and
you do not have access to
|

The user guide is available after successful login: click
 in the study selection dialog,
or select > from the application menu after selecting a
study.
in the study selection dialog,
or select > from the application menu after selecting a
study.
After login and study selection, the main window of DFexplore is presented. You have access to only those subject records and application features that the study administrators have granted you permission to use.
Typically each participating clinical site has access to their own subjects, a subset of the available reports, possibly restrictions on which study forms can be seen, modified, printed and exported, and on which views are available.
The DFexplore views include:
Dashboard - show basic study metrics graphically as well as a menu of operations for commonly performed tasks
Image - enter data from new CRF images received by email, fax or from DFsend
Data - enter, modify and review available subject data
Queries - review and respond to questions from the study coordinating site
Reasons - review reasons that were entered to explain particular data values
Reports - run and review study reports
Status - review data, query and reason status by workflow levels
List - review and export data records in tabular and SAS® formats
Schedule - review visit schedule compliance and schedule requirements
Batch Edits - create, modify and run batch edit checks
An overview of the DFexplore views makes up the rest of this tour. For more details see the chapter devoted to each view.
The Dashboard View provides shortcut access for common DFexplore views and a snapshot summary of the current database status. It can also be customized to show other study report information.

-
View Shortcuts. In the left-hand column, shortcuts are provided for commonly accessed functionality and menu items.
-
Status Summary. Presented in tabular and chart forms, the status summary is an overview of the records and metadata in the current database. The table cells and chart legends are interactive and clickable.
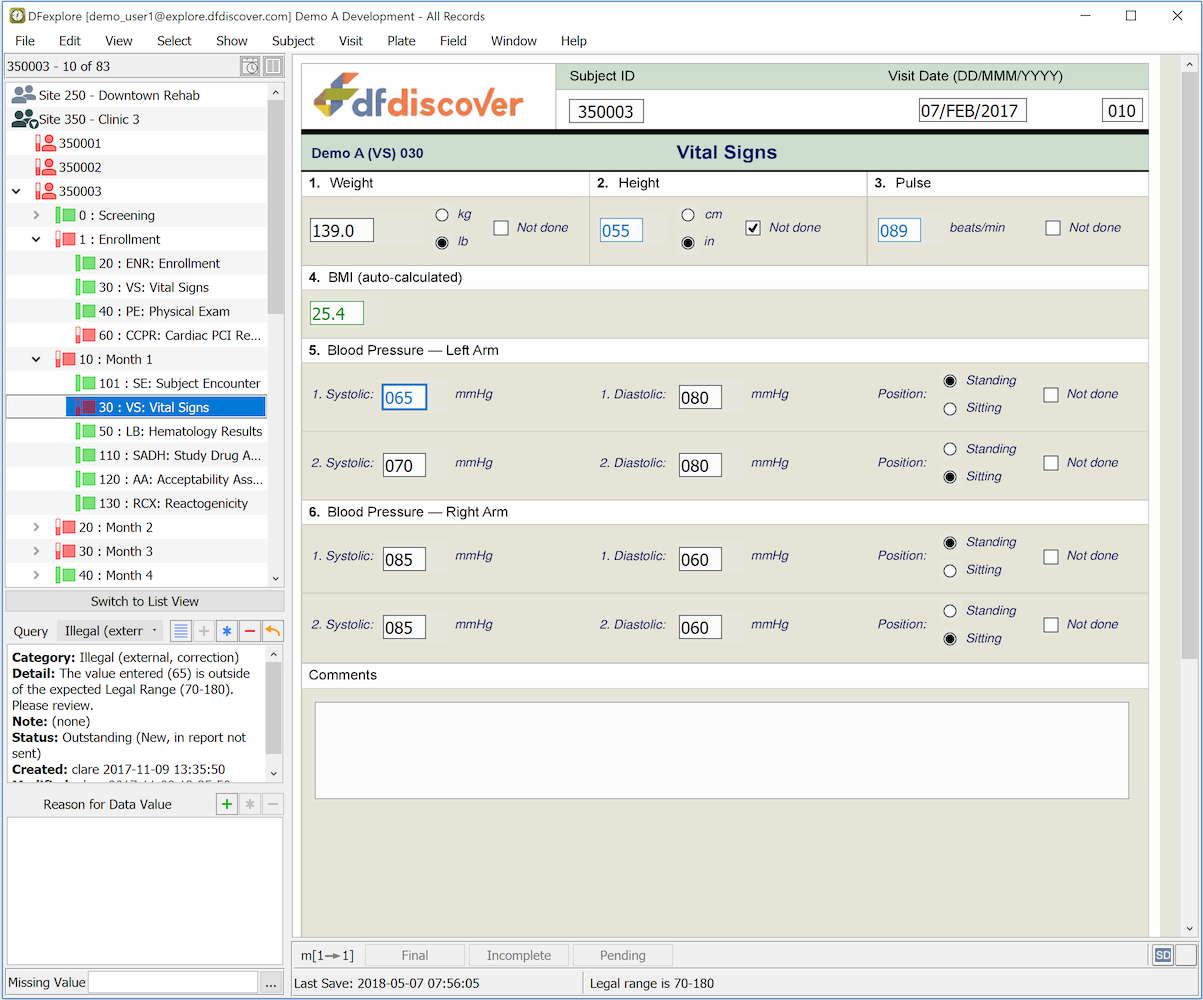
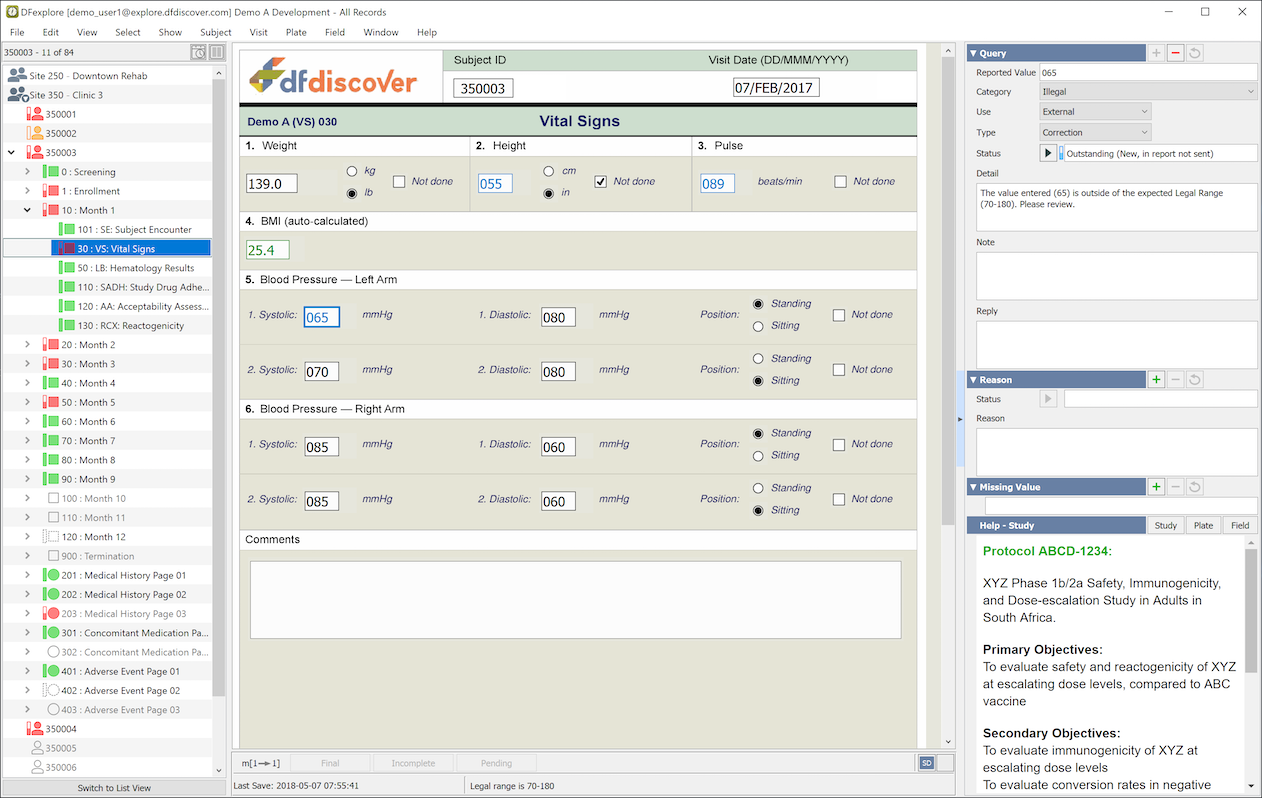
The components of the Data View window include the following:
-
Subject Binders. To enter or review subject data, start by selecting a subject binder from the record list panel on the left side of the main window. Binders are organized and grouped by site and then by subject within site. Each subject binder contains the data forms (CRFs) for an individual subject organized in subsections by study visit. Each subject binder has an icon, followed by a subject ID. In the example above the binder is open for subject ID 350003. You can open only one binder at a time. This locks the subject records giving you exclusive access to the binder until you close it. Subjects, visits and individual pages are color coded as follows:
green - no problems
red - some data problems exist
orange - data entry remains to be completed
-
Data Window. The data window is where you enter data values, filling out the form using a keyboard and mouse instead of pen and paper. Data fields are color coded as follows:
white - legal values
red - illegal, or required but missing, values
blue - outstanding queries, rejected reasons
orange - query replies and reasons pending review
green - query replies and reasons that have been approved
-
Queries. Data queries can be attached to any data field, either manually or by a programmed edit check. Blue fields have one or more outstanding (unresolved) queries. Queries for the current field appear in the Query panel and the Metadata panel.
In both the Query panel and the Metadata panel it is possible to open a text window where you can answer the query. This turns the data field orange, indicating that the query has been answered and is pending review by the study coordinating site. If the reply is approved, the field is green. If the coordinating site has new questions they will revise the query and the field is again blue.
-
Reasons. You may be able to avoid queries by entering a reason to explain an unusual data value. To add a reason to a data field, select the field in the data window and click the add button (
 )
in the Reason for Data Value panel.
Fields with new reasons are orange to indicate they are pending
review by the study coordinating site. If a reason is approved the field
is green. If the coordinating site has questions they add a
new query to the field and it appears in blue.
)
in the Reason for Data Value panel.
Fields with new reasons are orange to indicate they are pending
review by the study coordinating site. If a reason is approved the field
is green. If the coordinating site has questions they add a
new query to the field and it appears in blue.
-
Missing Values. Some studies use standard missing values, e.g. NA - not available, ND - not done, etc. which can be applied to data fields when a data value can not be entered. Each missing value has a code and a label. If standard missing values have been defined a code can be selected for the current data field by clicking in the Missing Value panel and choosing one. Fields with missing value codes are green and the label is displayed in the Missing Value panel when the data field becomes current. You are not able to add missing value codes to any field that has been defined as essential by the study coordinating site.
-
Saving Your Work. After making changes to data fields, queries or reasons, you must click one of the Save buttons at the bottom of the data window to commit your changes to the central database. If you are interrupted during data entry and do not want to lose your work, you can save a partially completed page using . If you have completed the page and there are no illegal or missing required values (red), or outstanding queries (blue) you can save your work using . Otherwise you need to choose . When there are unsaved changes, one of the Save buttons is colored as a reminder of the most likely appropriate status.

Data is never stored on your personal computer, and will be lost if you do not commit it using one of the Save buttons. You are warned if there are unsaved changes and you try to move off the current page.
-
Last Save. Each time that the data for a page is saved, a modification timestamp for that data is updated. The timestamp is stored centrally, always using the timezone where the DFdiscover server is located. As a convenience, and only in Data View, the timestamp is converted to and displayed in the local timezone. [2] Before using DFexplore, it is extremely important that the system clock on your local computer be accurate for clock time and time zone. Data changes are always recorded using the clock and timezone of the server but your interpretation may be incorrect if the local computer clock is wrong.
-
Message Panel. The message panel is located below the Save buttons and to the right of the Last Save timestamp. The panel displays field level help messages.
-
Images. DFexplore can store images and other supporting documents as well as data. This might include a faxed or scanned copy of a paper CRF or a medical record, DICOM video or test result. If images have been attached to the current page, the image icon (
 )
appears in the bottom-right corner of the screen
(the number and HD setting might vary according to
different settings on different servers).
Depending on your user preference settings (User Settings)
you may need to click the image icon to toggle between data and
image views.
If multiple images exist, the number of images appears in a
neighboring icon.
Clicking this icon launches a separate window where you can
review all of the images.
)
appears in the bottom-right corner of the screen
(the number and HD setting might vary according to
different settings on different servers).
Depending on your user preference settings (User Settings)
you may need to click the image icon to toggle between data and
image views.
If multiple images exist, the number of images appears in a
neighboring icon.
Clicking this icon launches a separate window where you can
review all of the images.
-
Metadata Panel. The metadata panel is an alternative presentation of queries, reasons, missing value and help content for the current data field. It uses the entire vertical height of the main window, potentially allowing more content to be displayed. User interaction with the metadata panel is the same as it is for the individual panels. Use of one panel over the other is purely a user preference.
-
Menubar. The menus, and menu items, in the menubar differ by view and are described in the chapter devoted to each view.
-
User Preferences. You can customize some aspects of DFexplore's behavior using the Preferences dialog. Once set, preferences are preserved across login sessions for the same username on the same computer.
-
Auto Logout. To meet regulatory and subject confidentiality requirements, DFexplore was designed with an auto logout feature that closes the study connection for the current username, after a specified period of inactivity. Inactivity is measured by elapsed time during which there is no keyboard or mouse input. If this occurs when you have unsaved changes in the current data window, the unsaved changes are lost, and you will be warned that this occurred the next time you login to the study. In that event you are asked if you would like to return to the page you were on when the auto logout occurred. This simplifies the task of returning to the page but any unsaved changes cannot be recovered and will require re-entry.
Any keyboard input or mouse movement inside the DFexplore window resets the timer and auto logout. A default and maximum time have been configured by the study coordinating site. In the preferences dialog, you can set a different auto logout interval, but it cannot be a value exceeding the configured maximum time.
The Queries View lists data queries.
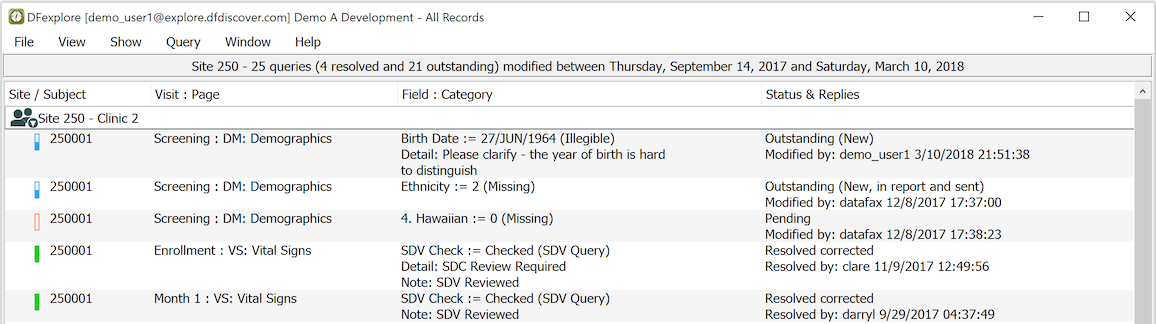
You can filter the list of queries in various ways to find the ones you are interested in. For example by selecting > you can list just those queries that need to be answered. Double-clicking a query opens the Data View to the relevant page and puts input focus on the data field with the query.
The Reasons View lists any reasons that have been entered to explain particular data fields.
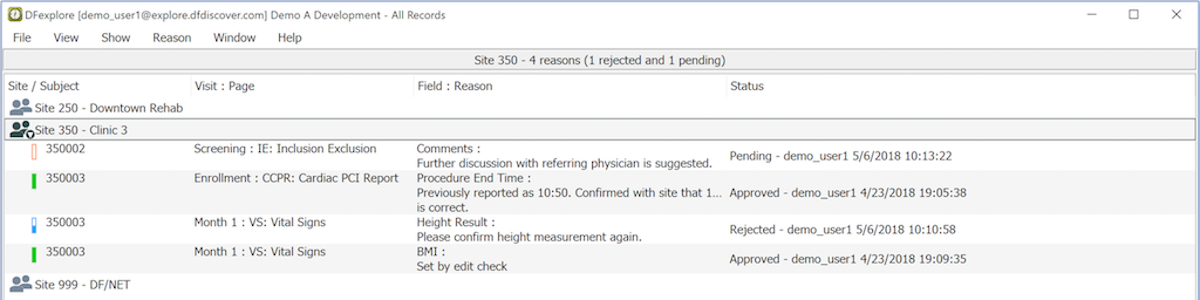
You can filter the list of reasons by status: outstanding, approved and rejected, and search for reasons with specified text strings. Double-clicking a reason opens the data view to the relevant page and puts focus on the data field with the reason.
The Image View is used to enter new data records from paper case report forms (CRFs) that have been faxed or emailed to the DFdiscover study server.
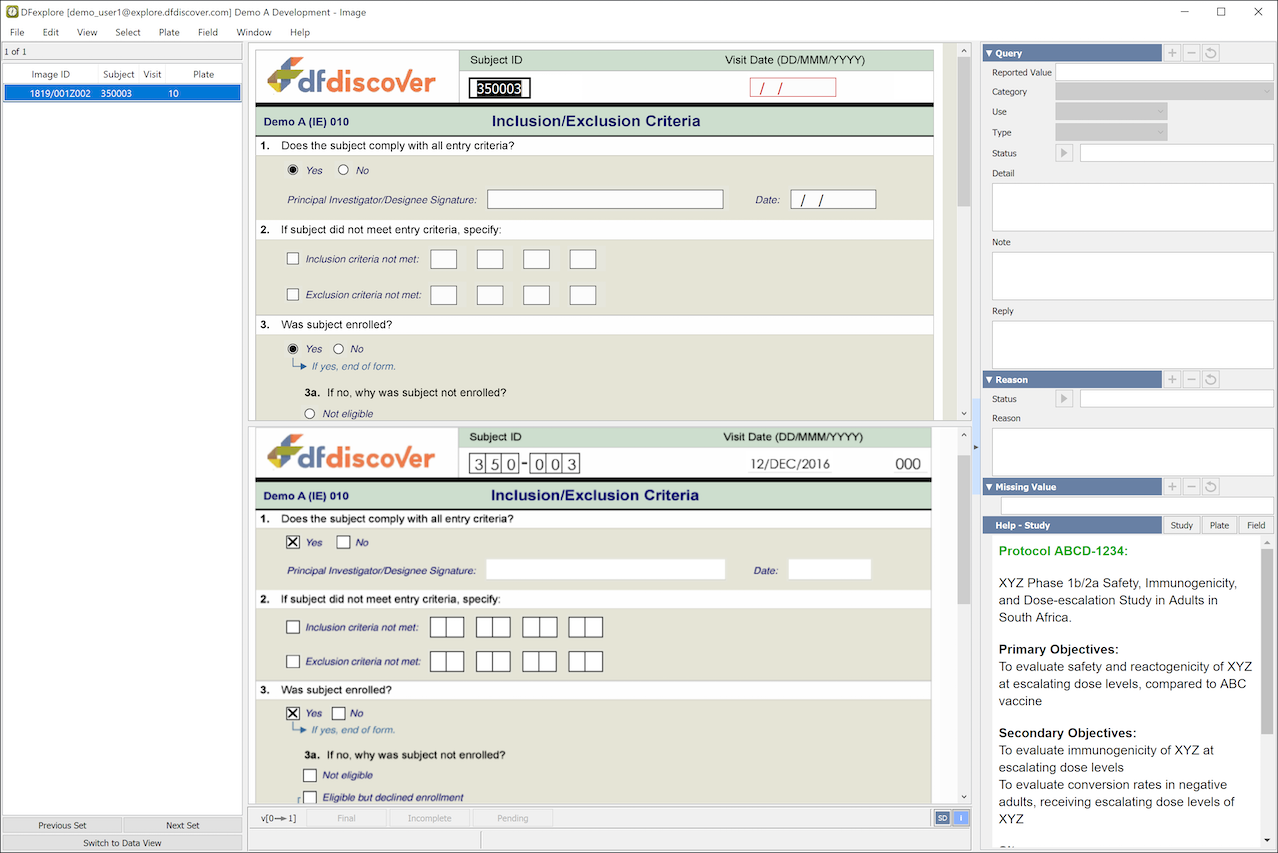
Image View is identical to the Data view except that the list of subject binders is replaced by a list of received pages that need to be entered. Image View features include:
-
Record Selection Options. Typically users chose to enter one document at a time and request the oldest ones first, but it is possible to request only certain CRF forms and to work backwards from newest to oldest arrivals. These options are specified by selecting Manual Retrieval... and completing the dialog.
-
Intelligent Character Recognition. When a CRF page arrives it is immediately scanned and read by the ICR software, preparing an inital data record for review. The task of the person using Image View is to correct any ICR errors or omissions, enter string/textual data and to add any missing value codes, reasons or queries that may be required.
-
Get of New Records. When you are finished with the current set of records, click to release the current set of records and fetch the next set, using the selection method and criteria as previously specified.
-
. Clicking opens the current subject binder in Data View while keeping the focus on the current page to show where it belongs in the binder. You can check other data records as needed before switching back to Image View to complete data entry for the new page.
The Reports View is used to run DFdiscover standard and study specific reports.
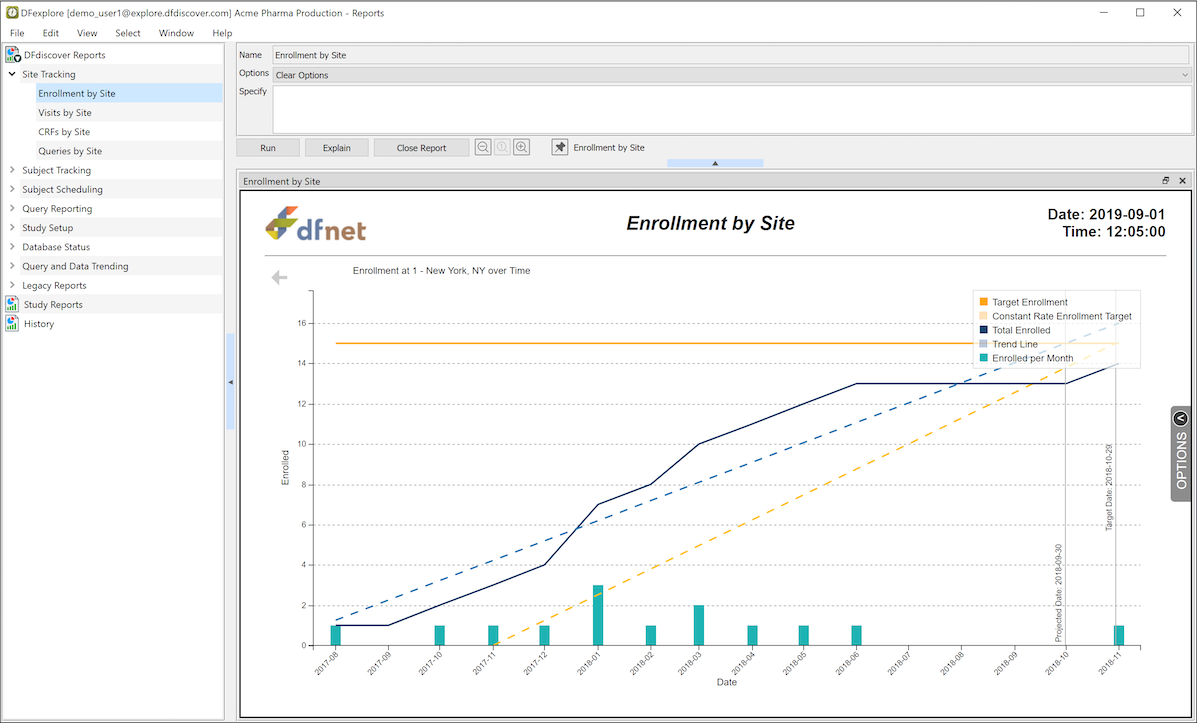
-
DFdiscover Reports. DFdiscover includes a number of standard reports that can be used in any study. The list of reports (which you have permission to run) appear under the DFdiscover Reports tab in the reports list.
-
Study Reports. Any study specific reports created by the study coordinating site are listed under the Study Reports tab.
-
History. Reports that you have already run during the current login session are saved and are listed under the History tab. Selecting a report from the history list displays the previous output for that report.
-
Options. Most reports have a number of options that can be selected and are applied at the time the report is run.
-
Explain. All of the DFdiscover Reports, and most Study Reports, come with a description of what they do and how to use the options. This documentation can be reviewed by selecting a report from the report list, and clicking .
-
Run. To run a report, select it from the report list and click . The output is displayed and added to the history list.
Schedule View uses several tables to display available information regarding the progress of subjects through the study visitmap.
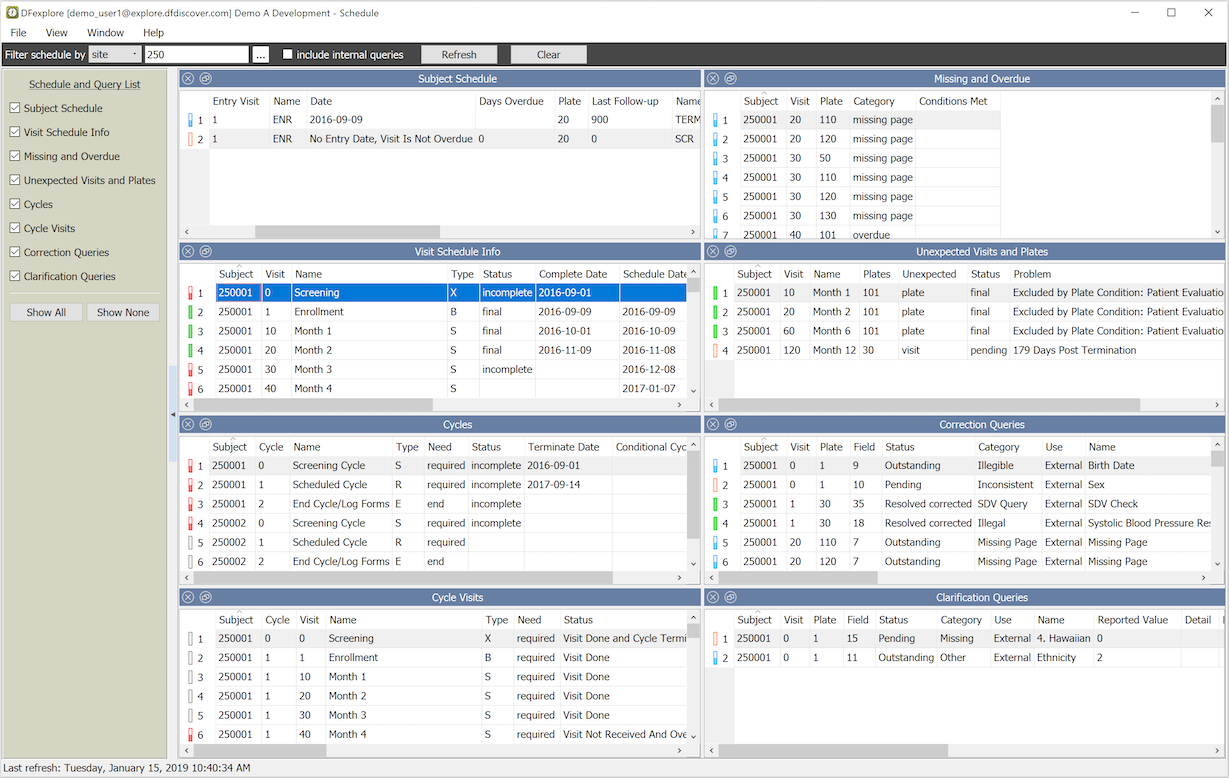
The information displayed in Schedule View depends on user permissions.
Schedule View can be used as a substitute for DF_QCupdate and DF_QCreports, providing information about missing pages, overdue visits and all unresolved, outstanding queries. Double-clicking a row in any table switches to Data View, selecting the matching record in the subject binder.
The Status View uses tables and graphs to show the number of data records, queries and reasons in the study database, categorized by workflow level and record status.
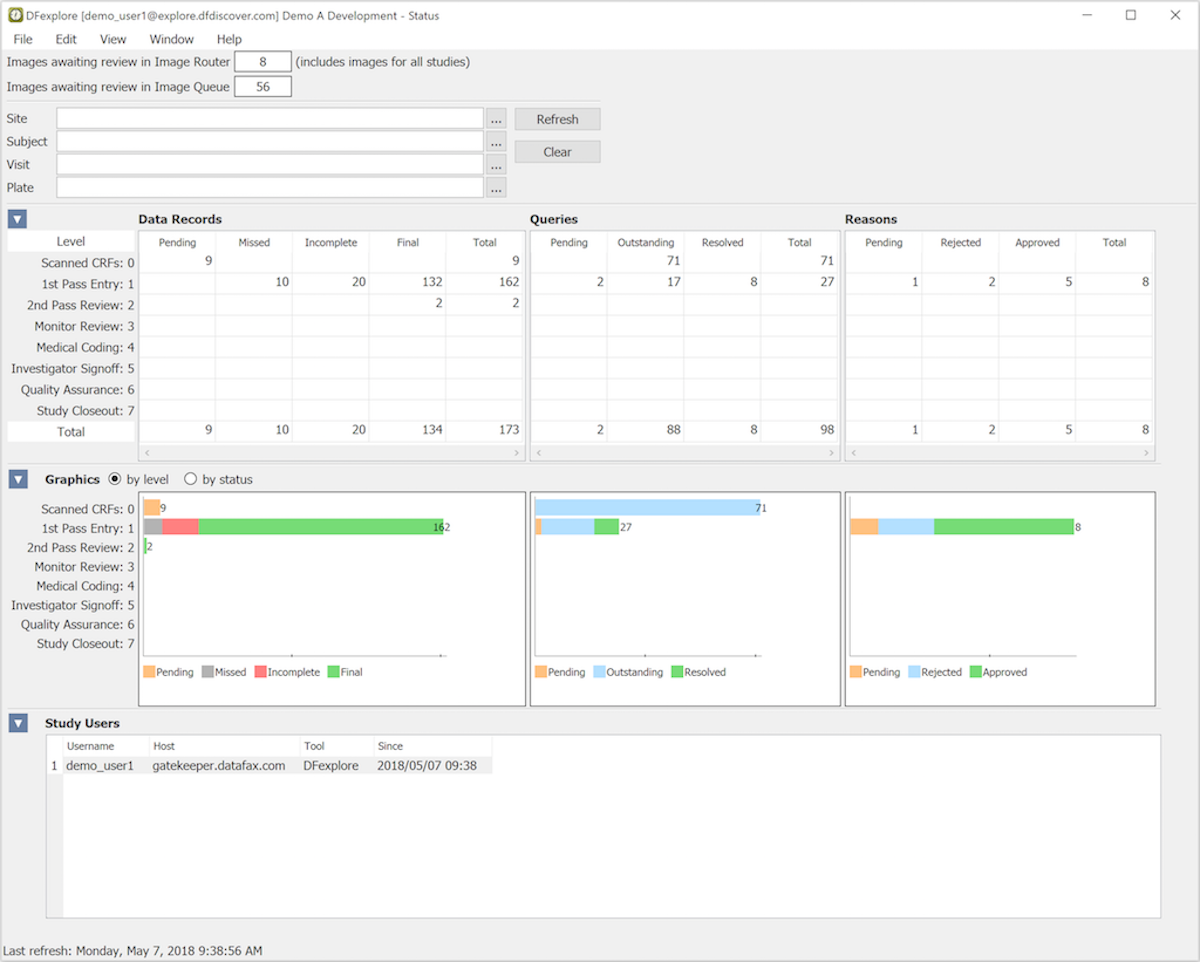
-
Permissions. The information displayed in Status View depends on user permissions. Counts include only records that you have permission to see.
-
Filters. The record counts can be displayed for specified sites, subjects, visits and CRF pages by entering the desired values in the filter fields and clicking .
-
Links. You can jump to the data, query or reason records for any cell in the tables by double-clicking the cell.
The List View is used to review all data records for a specified CRF plate in a table, where each column is a data field and each row is a data record.

-
Permissions. A plate or module is selected from the list of study plates in the left panel. Only records that you have permission to view are included, and when a record is selected, only those records which you have permission to view are shown as rows in the table, and columns are hidden for any data fields you are not allowed to see.
-
Selecting Data Fields. Data fields (columns) can be selected and reordered using the > dialog.
-
Selecting Data Records. You can search for data records with specific attributes (e.g. illegal values, outstanding queries, pending reasons, etc.) using the > dialog.
-
Selecting Predefined Views. Some users may have permission to define views, consisting of selected data records and data fields, for others to use. Views are created using > and accessed using 'Select-By View'.
-
Making Changes to Data, Queries and Reasons. You can not modify data values, queries or reasons directly in List view. However double-clicking a data field takes you to that field in Data View where changes can be made (if your permissions allow it). To return to List View from Data View, click .
-
User Preferences. The > dialog includes options for customizing List View including: field color coding, displaying codes vs labels, date formats and column titles.
The Batch Edits View provides a way for DFexplore users with permission to create, run and review the output from batch edit checks. This view provides a GUI to the DFbatch facility described in Programmer Guide, Batch Edit checks. Batch programs can be run on the server or locally (on the client's PC), with batch control files and output stored on the server or locally. In both cases, the batch view or the DFbatch application communicate with the DFdiscover server to do their work.
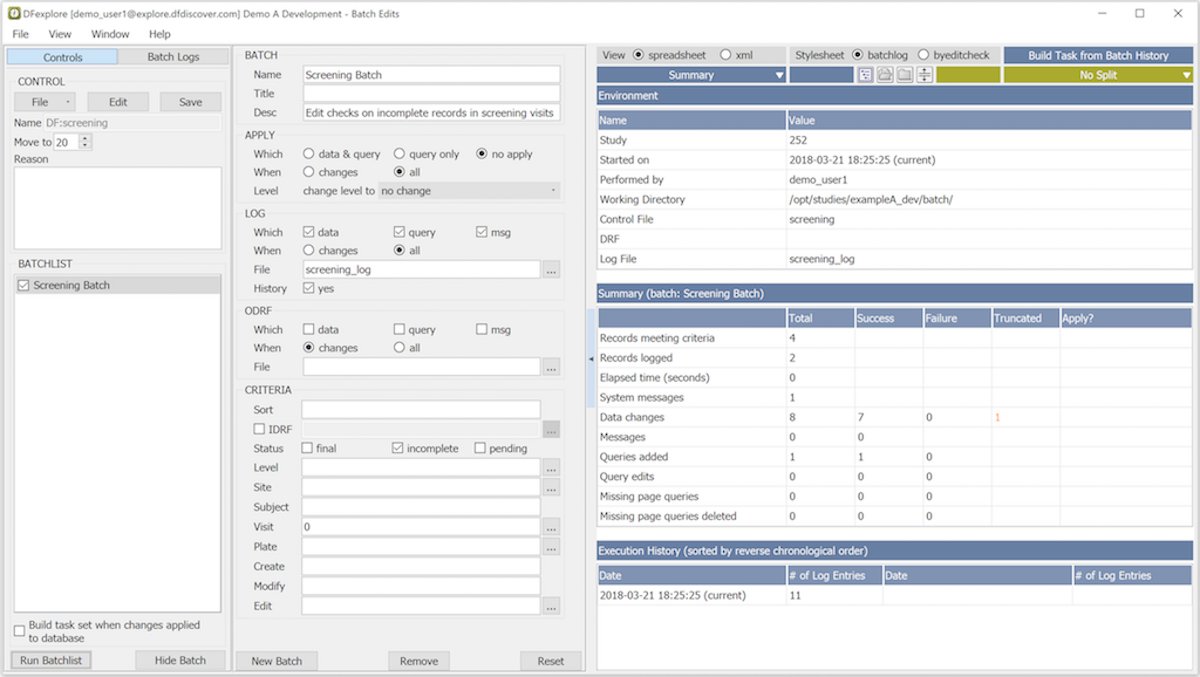
-
Control. Control files can be selected from your local computer or the study server.
-
Batch. The Batch pane is a graphical representation of a selected batch control file. Specification or editing control files in this way follows the same rules as DFbatch control files. This will be familiar to users that use the DFbatch application.
-
Output. Batch output appears in the rightmost panel in Batch Edits View. The output is presented in HTML or XML, the same as the default behavior of the DFbatch application.
[2] This is the only place where an attempt is made to use the local timezone. List View, audit trail reports, SAS® exports, etc. all present server time.
Table of Contents
- 3.1. How do I select the correct subject binder for a new subject?
- 3.2. Can I print a copy of a subject binder?
- 3.3. How do I confirm that I am the only person making changes?
- 3.4. How can I make sure that I am completing the data forms correctly?
- 3.5. Can I enter a reason to explain an unusual value or a value that I have changed?
- 3.6. Can I use standard missing value codes?
- 3.7. What are queries and where do they come from?
- 3.8. How do I find all outstanding queries?
- 3.9. How do I respond to queries?
- 3.10. Can I respond to a query by adding a reason for the data value?
- 3.11. How should I respond to a query if the data field is correct as is?
- 3.12. Can I indicate that a subject visit is unavailable?
- 3.13. Can I indicate that a page is unavailable?
- 3.14. Do I need to save the changes I have made?
- 3.15. Can I undo all changes I just made to a page?
- 3.16. What is the best way to find all outstanding problems?
- 3.17. Why did my DFexplore session Auto Logout?
- 3.18. How do I exit from DFexplore?
- 3.19. What should I do if I have questions?
This chapter explains how to perform a number of common data management tasks. It describes what is possible in DFexplore, but how these features are applied may differ from one study to another. You may receive more specific instructions from the coordinating site for your particular study.
In many studies subjects are numbered sequentially as they enter the trial, but in some studies subject IDs are random and assigned on study enrollment or randomization. In either case, subject IDs must be registered in the DFdiscover study setup at the coordinating site before they are available in DFexplore.
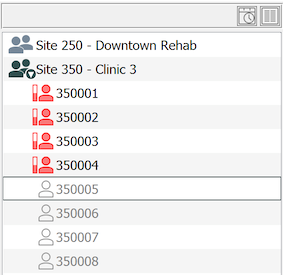
To see the subject binders available for a site, select > . If you work at more than one study site you must double-click a site to open it. Within an open site, a list of subject binders, identified by icons and subject IDs, and sorted in ascending numeric order, is presented on the left side of the screen.
Binders that are in use are represented by an active icon. Unused binders appear muted with an empty icon. In most cases, the first unused binder in the list is the correct binder for the next subject. Double-clicking the binder opens it.
If the subject ID you need is not in the subject binder list, select > , and enter the subject ID number.
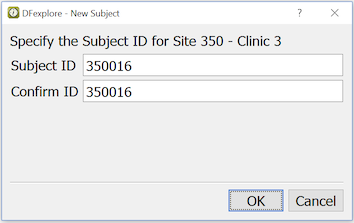
Enter the subject ID, and re-enter the same ID to confirm. Click to create the new subject binder. The new subject binder is added to the binder list, and this binder opens automatically.
If instead of a new subject ID, you enter one that already exists in the subject binder list, that binder opens after clicking .
Yes. You may need blank copies of the data forms to use as worksheets before entering the data in DFexplore, or you might complete and submit certain pages so that staff at the study coordinating site can enter the data for you. Or, you might want to print a completed visit so it can be added to the subject's medical records.
You have 2 options, with very similar dialogs, > and > .
To print subject CRFs:
-
Select > to open Data View.
-
Open a site and then a subject binder.
-
To print only selected pages, open the corresponding visits.
-
Select > .
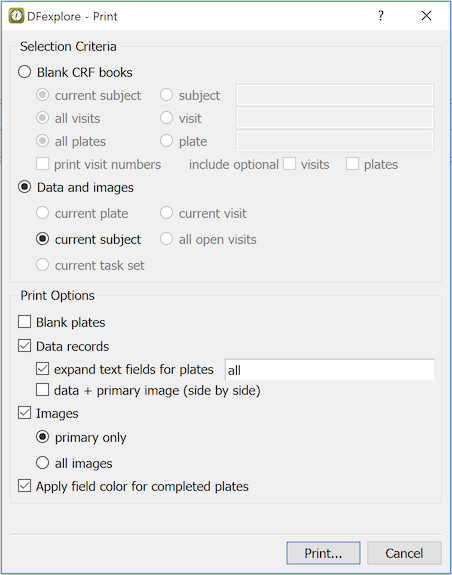
-
Complete the Selection Criteria to include:
Blank CRF books - CRF pages which do not yet contain data, or
Data and images - completed CRF pages and their corresponding images
-
Select one or more Print Options:
-
Blank plates - CRF pages which do not yet contain data
-
Data records - CRF pages containing data values
-
expand text fields - to avoid truncating long text entries
-
data + primary image - to see both the data and the supporting CRF
-
Images - document images that exist for primary records only, or all records
Mark Apply field color for completed plates to color the data fields as shown in DFexplore
-
-
Click and complete the system print dialog.
-
In this example, the current subject is selected. Data records and Images are checked. This creates one copy of each entered page for the current subject, with data values included on pages where data has been entered. If a fax or scanned image exists for any of the entered pages, the primary image is also included. The subject ID and visit number are printed on every page, even on blank plates. Confirm that the correct subject binder(s) is selected before printing.
DFexplore uses subject binder locking, which ensures that only one user can work in a subject binder at a time. The binder is locked when you open it and released when you close it. It is also be released if your DFexplore session times out.
Do not lock a subject binder unless you are working on subject data or metadata. Even if you are the only person with permission to enter data into subject binders at your site, remember that someone at the study coordinating site will have permission to review, and approve or reject, new reasons for data values and replies to queries that you have entered. This too locks a subject binder until the review is completed.
If you try to open a subject binder which is locked by another user, a dialog appears asking if you want to open it in view only mode.
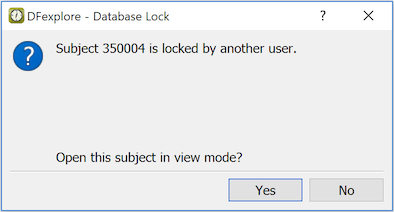
While in view only mode, the Save buttons are inactive and a message indicating that the subject is locked by another user is displayed at the bottom of the data window.

These are the recommended steps:
-
Double-click a subject binder to open it.
-
Double-click all of the visits that require entry/review.
-
Click the page to start on. It appears in the data window.
You can go to any page at any time by selecting it in the subject binder list. The up and down arrow keys can be used to move through the pages of the all the visits that are open.
-
Press Tab or click anywhere in the background of the data window. This places the focus on the first data field and the field is highlighted.
-
Complete the first data field using the keyboard, entering text and numbers, or the mouse to select a choice option or move a visual analog slider. Choice options can also be selected using the number keys: 1=1st option, 2=2nd option, etc., and visual analog fields can also be completed by using the right and left arrow keys to move the slider along the scale.
-
As you enter values notice the field color. Required but blank fields, or fields containing illegal values, appear red and change to white when a legal value has been entered. The help message may display the legal values expected for each field.
-
After completing the field value, press Return or Tab to move to the next field. Continue in this way to complete all fields on the page. This ensures that all fields are traversed in the order planned by the form's designer. Some fields may have edit checks that are triggered as the field is entered or exited. Moving through all fields ensures that all of the edit checks are triggered, and thus that notifications of any problems are displayed.
-
Carefully review all warning and error messages displayed by edit checks. Take any necessary action to correct or explain unexpected values.
-
If necessary, move backward through fields using Shift+Tab or Shift+Return.
-
When all of the fields on the page have been completed, save your work by clicking one of the three Save buttons at the bottom of the screen:
- all fields have been completed and there are no red or blue problem fields,
- a field is incomplete, or there are unresolved queries or illegal values,
- a field is incomplete and you want to complete the page later, before it is reviewed by the study coordinating site.
Pending cannot be used after a page has reached Final or Incomplete status, and Final can not be used if the page still has problem fields.
-
Some edit checks may also be triggered when clicking , or to save changes.
-
If there are problems fields that you are not able to locate, select > . A listing of all the problems that are preventing you from saving the page with status Final is displayed.
Resolve the problems and click . If some problems cannot be resolved, click .
-
After a page is saved, the next page that is open in the subject binder list (if any) is opened in the data window, again with the focus on the first field at the top of the page.
-
Continue in this way to complete all pages in the opened visits. Those visits and pages with a square icon are required, while those with a circle icon are optional (i.e. not required for all subjects). However, an optional page may become required if some specified condition is met, thus you may find a missing page query on what would normally be an optional page.
-
Examine the icons for each completed page to confirm that each record has been saved with the correct status. Icon shape and color confirms each record status: green indicates Final status, red indicates Incomplete status, orange indicates Pending status, while any page with an outline icon has been marked Pending.
-
Double-click the subject icon to close the open subject binder. The open subject binder also automatically closes when a new subject binder is selected / opened. Remember that only one subject binder can be open at a time, and while you have it open, no one else is able to use it (except in view only mode).
-
When you are finished entering study data, or if you need to pause for more than a few minutes, exit DFexplore.
Do not leave your computer unattended while you are logged in to the study database.
Yes. This is a good way to avoid queries from the study coordinating site. Add a new reason, or modify an existing reason, for any problem field (red or blue), to create a pending reason (orange) that resolves the problem, pending review by the study coordinating site. Dealing with all problem fields this way allows you to indicate that you are finished with the page by selecting when you save your modifications.
If there are outstanding queries on the data value, the addition of a new reason to that data value may automatically resolve one or more queries. This behavior is controlled by the "auto-resolve" attribute of each query and is defined by the coordinating site.
When a data field has the focus, all metadata (queries, reasons and missing values) for that field are shown in the metadata panels below the subject binder list.
If a field already has a reason, it is displayed in the Reason for Data Value metadata panel;, otherwise this window is empty.
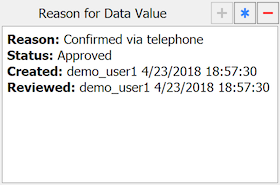
The following properties are displayed:
Reason. the user-specified reason for the current value in the data field
Status. when a reason is created or revised its status is set to Pending. On review by central staff, status may be changed to Approved or Rejected.
Created. who created or most recently revised the reason and when
Reviewed. who most recently set the reason status to Approved or Rejected and when
To add a new reason,
click
or select
> .
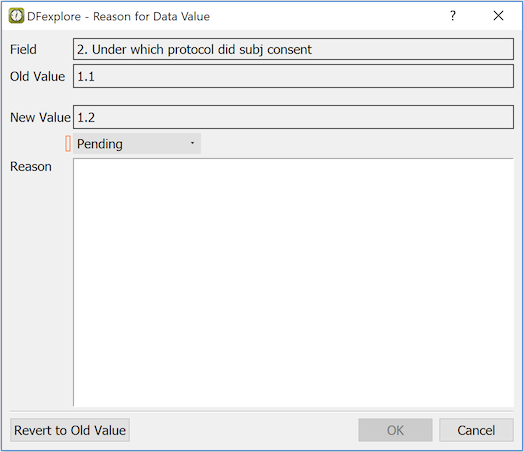
The Reason for Data Value dialog displays:
Field. The description of the current field
Old Value. The value the field had when the page was opened
New Value. The current value in the data field
Status. The status of the reason - new reasons are created with status Pending, unless you have permission to approve reasons
Reason. Enter a reason for the new value
Some fields may require a reason when they are changed. In such cases the dialog appears automatically when the field is exited. You can enter a reason or click to undo the change. Once a reason has been entered, is used to apply it. The new reason appears in the Reason for Data Value metadata panel.
When a reason is created by a user who has permission to approve reasons, the status is automatically set to Approved, and is active so that the status can be changed if needed.
Remember that no reason changes are saved until the entire record is saved. This applies to all reason, query, missing value and data changes on the current record.
Yes. DFdiscover supports missing value codes. They may be predefined for each study to provide standard accepted reasons for missing data. If missing value codes have been predefined for your study, you can assign one of them to the current data field by selecting it from the list displayed when you click the button on the Missing Value metadata panel, or using > .

When a missing value code is selected, the data field turns green (provided the field does not have some other problem) to indicate that the field has an approved metadata value. The missing value is not displayed in the data field; it appears in the Missing Value metadata panel when the field has the focus in the data window.
After applying a missing value code, the keyboard shortcut Control+M (Command+M on macOS) can be used to repeatedly apply the same missing value code to other data fields.
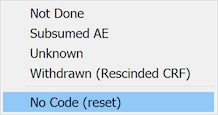
To remove a missing value code so that a data value can be entered, choose No Code (reset) from the drop-down list of missing values.
Queries are questions about data values. They are always attached to a data field, manually by someone at the study coordinating site, or automatically by edit checks and other programs that check for problems.
There are 4 types of queries:
Data Correction Queries. Request a correction to a data value or a blank field
Data Clarification Queries. Ask for a reply to a question
Overdue Visit Queries. Identify visits which should have been performed by now
Missing Page Queries. Identify required pages that have not been completed
Data Correction and Data Clarification queries have several attributes - the most important is a categorical type. There are several standard categories that are always available in DFdiscover. They are:
Missing. The field's value is blank but is required
Illegal. The value is outside of the field's legal range property
Inconsistent. The field's value is inconsistent with the value in another field
Illegible. The source document has handwriting which is unclear
Fax noise. The faxed page had transmission errors which make the page unreadable
Other. An uncategorized problem described in the query details
Additionally, each individual study may define further categories for specific queries.
In some cases, such as when the category is Missing or Illegal, no further information may be needed to communicate the problem. When necessary, the query can include further details describing the problem.
If a query is attached to a data field, it is displayed in the Query metadata panel when the focus moves to that field. If the query is not yet resolved, the field is blue and the query status is Outstanding. If the query has been resolved, the field is green (unless there is another problem, like a rejected reason, or an outstanding or pending query) and the query status is Resolved.
-
Select > to open Queries View.
-
Select > .
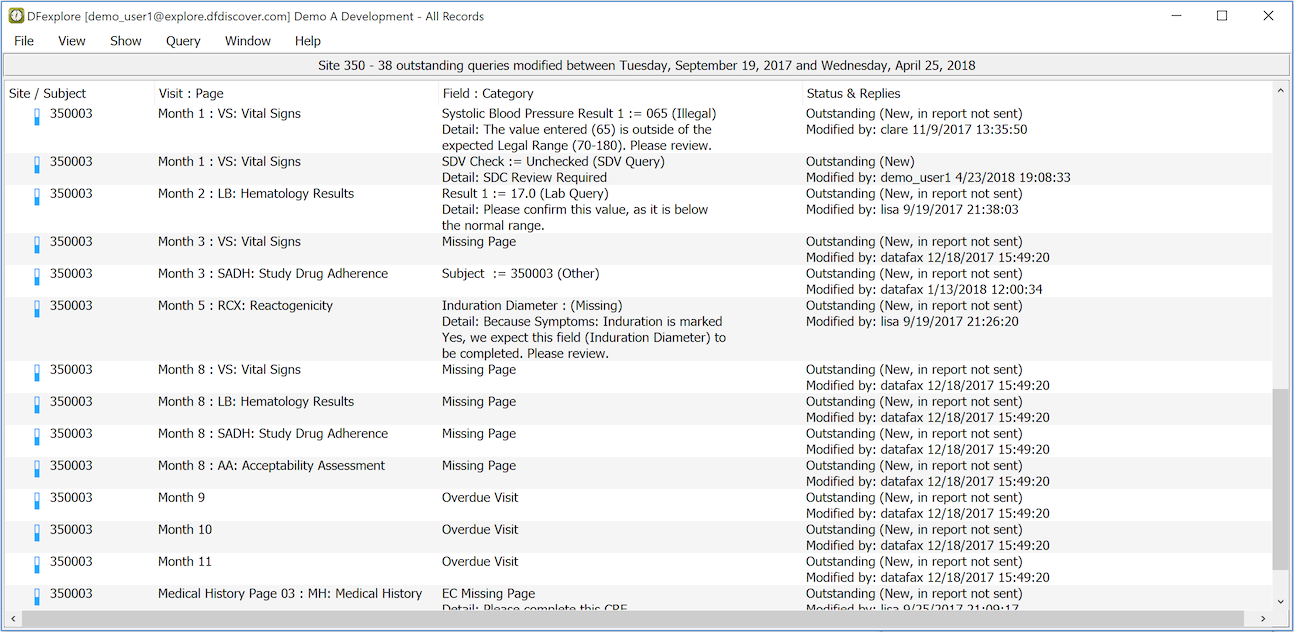
All outstanding queries are displayed. If none are displayed you have no outstanding queries - congratulations!
To review and respond to a query, double-click the query in the list. The main window switches to Data View, with the field focus on the data field with that query. Edit/resolve the query as required.
After you resolve a query, it is removed from the list when you return to Queries View.
When the focus moves to a data field that has a query, the query is displayed in the Query metadata panel.
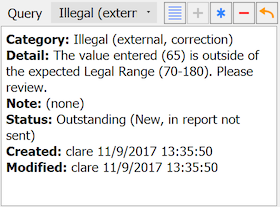
The Query metadata window contains:
Category. Categorical value for the query type
Detail. Text description of the problem (optional)
Note. Optional text description to accompany a resolved query
Status. Current status of the query
Created. User that created the query and when
Modified. User that modified the query and when
Resolved. If query is resolved, user that resolved the query and when
Some queries can be resolved by correcting the data field. For example, a missing or illegal value query can be resolved by entering a legal value. In such cases the field changes from blue to green and no further action is required.
Other queries ask a question to which a reply is expected. When a reply is entered, the field turns orange (provided there are no other outstanding queries on the field) and query status changes to Pending, to indicate that the reply is ready for central review.
You can reply to an outstanding query, or modify the reply to Pending status, but you cannot change the reply once a query has been resolved.
To reply to a query,
click  ,
or select > .
,
or select > .
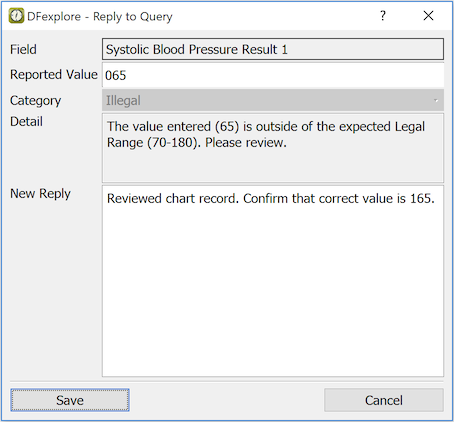
The Reply to Query dialog includes:
Field. Description of the current field
Category. From one of the system types: Missing, Illegal, Inconsistent, Illegible, Fax noise, Other, or a study-defined type
Detail. Optional description of the problem
Old Reply. Previous reply to this query (if any)
New Reply. Enter the (new) reply here
Yes, and often this will be the best response. Unless a query indicates that a reply is required, adding a reason to explain the data value is the better solution, because the reasons you enter are not changed by the study coordinating site and are thus always be visible in the Reason for Data Value metadata panel, whereas the current query, once resolved, may be replaced by a new query to address a new problem.
As a general rule, use reasons to explain why data fields have the values that they do, and only reply directly to queries when it is necessary to refer to other data fields, or explain something not contained in the reason.
If a query asks you to correct a data value that is already correct, respond using one or more of the 3 metadata options:
If the field is blank and an appropriate missing value code is available, choose one using the button on the Missing Value metadata panel. If the field is defined as 'essential', this is not possible.
To explain why the value is correct as is, add a reason in the Reason for Data Value metadata panel.
To reply to the query directly, click
in the Query metadata panel.
When all queries on the field have been responded to in one of these ways, the data field changes from blue to green if the response resolves the problem, or orange if the response needs to be reviewed by the study coordinating site.
Yes. A subject visit might be unavailable for a variety of reasons. The subject might have missed a clinic visit or refused a particular lab test. In such cases you can indicate that the visit is missed.
To mark a visit missed:
Select > to open Data View.
Double-click the subject binder to open it and display the visits.
Click the visit in the subject binder list.
Select > .
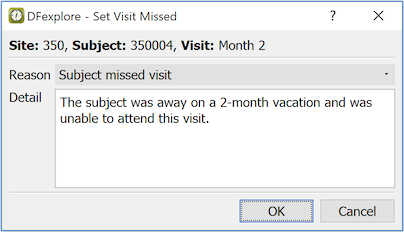
In the dialog, select a reason from the drop-down list. Optionally, enter additional explanation in the Detail field.
Click to save this change to the database and set the visit as missed. If an overdue visit query exists it is removed.
Once a visit has been marked missed, data entry is blocked for all pages in the visit.
Whenever a record in the missed visit is selected the reason specified when the visit was set missed appears in the Reason for Data Value metadata panel.
If you discover that it was a mistake to mark a visit missed, select the visit in the subject binder list and select > . In the confirmation dialog, a reason is required for the change. This removes the missed flag and enables data entry for all pages in the visit.
It is also possible to remove the missed attribute from individual pages by making the page current and selecting > . Again, in the confirmation, a reason is required for the change.
Yes. A single page within a visit might be unavailable while other pages can be completed. This might arise because the visit is made up of different exams and some are not relevant for some reason, or because the subject refused to complete the entire exam. Whatever the reason, individual pages can be marked missed.
To mark a page missed:
Select > to open the data view.
Double-click the subject binder to display the study visits. Double-click the visit to open it.
Select the page to set missed. It appears in the data window.
Select > . In the confirmation dialog, choose a reason category and enter details describing the circumstances.
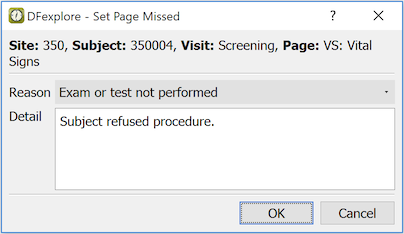
Click to save this change to the database and set the page as missed. If a missing page query exists it is removed.
Once a page has been marked missed, data entry is blocked for that page. Whenever the page is selected, the reason specified when the page was set missed appears in the Reason for Data Value metadata panel.
If you discover that it was a mistake to mark a page missed, select the page in the subject binder list and select > . In the confirmation dialog, a reason is required for the change. This removes the missed flag and enables data entry for the page.
Yes. None of the changes you make to data fields or metadata (queries, reasons and missing values) are saved until you select one of the save buttons at the bottom of the data window. The same green (Final), red (Incomplete) and orange (Pending) color coding is applied to the save buttons. Only those buttons which are valid for the current data are available.
The save buttons are:
Click if all fields have been completed or explained with reasons, all queries have been answered, and you know of no other changes that are needed to complete data entry.
Click if any field is still incomplete or any query is still outstanding.
Click if you are not finished with the page and would like to return to it later before it is reviewed by the study coordinating site.

There are two restrictions:
-
is not available once a page has reached Final or Incomplete status if your permissions only allow Pending to be used during new data entry. If this is the case, is inactive to prevent a mistake.
-
can not be used if there are any red or blue fields on the page, i.e. any problem fields which have not been corrected or addressed using a resolved query, a new reason or a missing value code). If this is the case, is inactive.
If you try to close the current page or open a different page without saving changes, a dialog appears asking if you want to save or discard your changes before opening the new page.
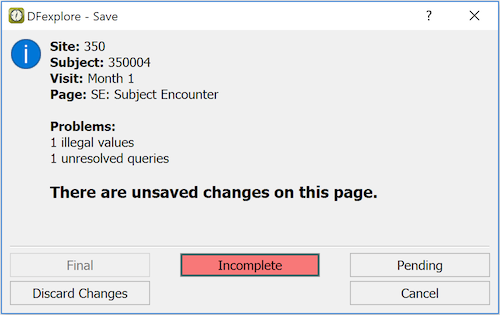
Click the appropriate button to continue and save your changes, discard your changes or return to the data record for further review.
Yes, but only if you have not yet selected one of the save buttons. Select > , and click in the confirmation dialog, to undo all changes to data fields and metadata (queries, reasons and missing values). The page is returned to the state it was in when you first opened it.
This is the only undo level available. Once you have selected one of the Save buttons (Final, Incomplete or Pending), you can not revert to a previous state.
Start by reducing the subject binder list to just those subjects that have Incomplete and/or Pending pages. Select > .
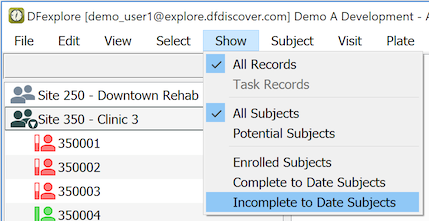
If no subject binders appear in the list, congratulations - there are no outstanding problems.
Otherwise, for each subject binder proceed as follows:
Open the subject binder and scan the list of visits for those which are Incomplete (red, for example
 ) or Pending (orange, for example
) or Pending (orange, for example  )
)
When you open one of these visits, the Incomplete and Pending pages are identified with the same red and orange icons.
Select one of these pages and look for red and blue fields. The blue fields have metadata, either an unresolved query or a rejected reason. The red fields contain illegal values or are required but currently blank.
It is possible to save a page with Incomplete status even though it has no red or blue fields. This might be done when there are optional fields that still need to be completed. Users may have flagged these fields with reasons, thus it is also be a good idea to review any orange fields.
If you are able to resolve all problems on the page, save your changes using status Final, turning the icon color to green.
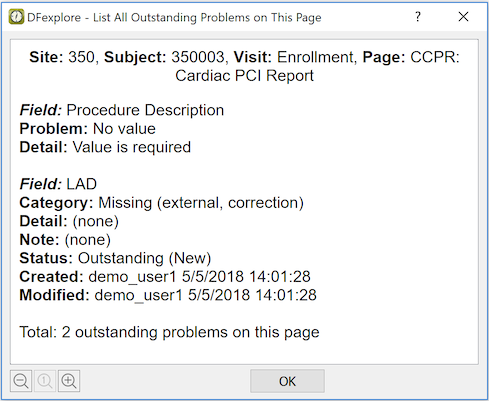
In addition to looking for red and blue fields, it is possible to get a list of all outstanding problems on the current page. To list all problems on the current page select > .
For regulatory reasons related to confidentiality of subject data and the requirement that data entry must be attributable to an authorized individual user, you must always exit DFexplore when your current work is done, or when you need to leave the computer unattended for any reason.
Should an unexpected event or emergency prevent you from logging out, a built-in timer will automatically log you out after a specified period of inactivity, determined by the study coordinating site.
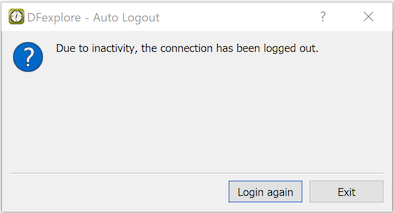
If this occurs, any unsaved changes to the last page you were working on are not saved, and the subject binder is released so that other authorized users can access it.
If you were auto logged out from your last DFexplore session, you will see the Resume Previous Session dialog the next time you login to the same study.
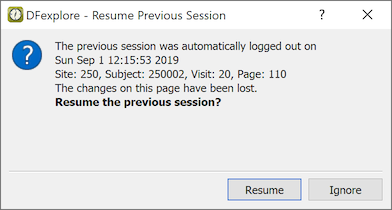
The default action, returns you to the same Data, Query or Reason view that was on-screen before the Auto Logout occurred. Click to return to your preferred view.
If there were unsaved changes to a page, the page is identified by subject ID, visit, and page number, and you are able to return to it by clicking .
If you return to a page after some time has passed, and other users are authorized to modify the page, some data fields may have been changed since you last saw it. You can tell if this has occurred by comparing the time shown in the Resume Previous Session dialog with the Last Save time displayed in the data window when you return to the page.
You can change the Auto Logout timer, within limits specified by the study coordinating site, by selecting > .
Confirm that you have saved any changes to the page you are currently working on. If you forget you are warned when you try to exit.
When you are finished working in a study, you can close the study or exit the entire DFexplore session.
-
To close the study connection but remain connected to the DFdiscover server, select > . This takes you back to the study selection dialog. This is a useful shortcut if you are working with DFexplore and multiple studies.
-
To end your current DFexplore session, select > (Windows), or > (macOS). This disconnects you from the DFdiscover server and exits the application.
Table of Contents
The Dashboard View provides quick, convenient access to many commonly used functions. The Dashboard View can be a launching point for other views in DFexplore. It can further be customized to include commonly used reports, tabular and graphical summaries of the database status, and study help.
The contents of the Dashboard View are easily customized by clicking the customize button.

In the customize dialog, select the contents to be included in the Dashboard View. The default dashboard contents appear at the top of the dialog - de-selecting any item removes it from the Dashboard View. Any permitted DFdiscover or study report is also displayed and may be selected for inclusion in the Dashboard View. Reports which are not permitted, or require additional user input before running, are automatically excluded from the displayed list.
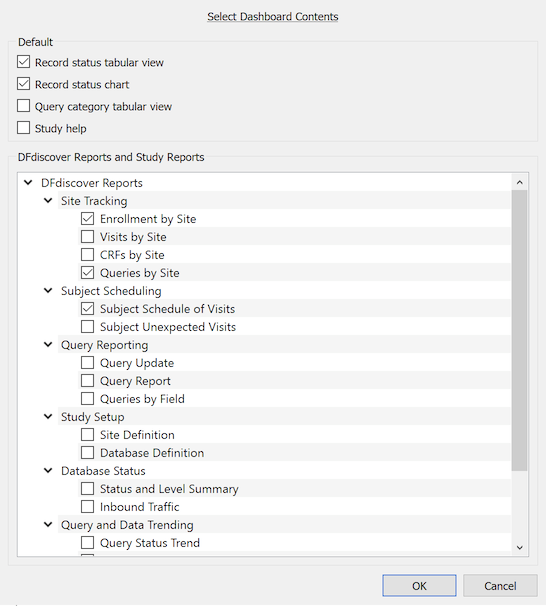
Any report can also be added by "pinning" it from Reports View, Adding Reports to the Dashboard.
Any customizations to the dashboard contents are saved to the local user settings so that they are reflected in subsequent logins.
A vertical column of shortcuts for commonly used menu items is presented on the left side of Dashboard View. The specific shortcuts that appear are filtered by your database permissions - your shortcuts may not match those of other users.
The shortcut for Data View Tasks is a pull-right menu of menu items. The included menu items are the same as the tasks that are presented when you are in Data View and access > .
The main Dashboard View contains sub-windows, where each sub-window displays
the output of a specific report. For optimal performance, Dashboard View
limits the maximum number of sub-windows to 25 (just as Reports View does).
[3]
The arrangement and ordering of the sub-windows is controlled by settings in the presentation ribbon.

Specifically the sub-windows can be presented in
 Grid view: Sub-windows
are organized in 2 columns (if there are at least 2 sub-windows) and as many
rows as needed.
Grid view: Sub-windows
are organized in 2 columns (if there are at least 2 sub-windows) and as many
rows as needed.
 List view: Sub-windows
are organized in 1 column with as many rows as needed.
List view: Sub-windows
are organized in 1 column with as many rows as needed.
 Single view: Sub-windows
are stacked so that one sub-window is visible at any time, occupying all of
the available window space. A convenient
thumbnail index and previous/next buttons are included, making it easy to
navigate between single views.
Single view: Sub-windows
are stacked so that one sub-window is visible at any time, occupying all of
the available window space. A convenient
thumbnail index and previous/next buttons are included, making it easy to
navigate between single views.
To update, with current study data,
the contents of all sub-windows, click the Refresh All button
(  ).
Depending upon the complexity and volume of the data request, refreshing
all sub-windows may take several seconds.
).
Depending upon the complexity and volume of the data request, refreshing
all sub-windows may take several seconds.
Each sub-window is a rectangular area with a body and a header. The body contains the report output. The header includes the report title of the window contents, and 3 action buttons. The action buttons, of any sub-window, from left-to-right are: close, undock and refresh the contents.

The header may also be grabbed and dragged to "undock" the window from the Dashboard View. This is similar to undocking windows in Reports View. The undocked window can be moved and positioned independent of Dashboard View. Additionally the undocked window can be "dropped" elsewhere in the sub-windows; this adjusts the layout to fill the space created by the undocked window and also creates a space to insert the undocked window in the new location.
By default, the dashboard includes several special status tables and graphs. These tables and graphs are special because the table cells and chart legends are clickable. Double-clicking any item builds a task to retrieve those filtered data records and presents them in Data View. Task options can be modified in the confirmation dialog before switching to Data View. If the table cell or chart legend item is related to a query, the Queries View is presented; if it is related to a reason, the Reasons View is presented.
In the table of query categories and statuses, rows are categories and statuses are columns. By default, categories (and hence rows) that have counts greater than 0 are displayed. To display all table rows, check All in the table header for the Query Category column.
To select queries for a specific category and status, double-click the matching cell in the table. To select queries for a specific category and all statuses, double-click the category label in the first column of the matching row. In the task confirmation dialog, choose if the task records are displayed in Data View or Queries View.
[3] When there are already 25 sub-windows defined in Dashboard
View attempting to add or pin an additional report will warn the user that
an existing sub-window must be closed first.
Table of Contents
- 5.1. Subject Binders
- 5.2. Metadata: Queries, Reasons and Missing Values
- 5.3. Data Field Colors
- 5.4. Entering Data and Metadata
- 5.5. Saving Data and Metadata
- 5.6. Correcting Key Fields
- 5.7. Images of CRFs and other documents
- 5.8. Image Option Buttons
- 5.9. High Definition (HD) Images Setting
- 5.10. Working with Tasks
- 5.11. Ad hoc Record Selection
- 5.12. Using Lookup Tables
- 5.13. Query Management
- 5.14. Review/Approve Queries and Reasons
- 5.15. Transmitting Scanned CRFs
- 5.16. Importing Subject CRFs
- 5.17. Creating Subject Packages
- 5.18. Data View Menus
The Data View is the most commonly used DFexplore window. It provides access to all subject binders for data entry and review. Several of the other views provide quick access links to Data View.
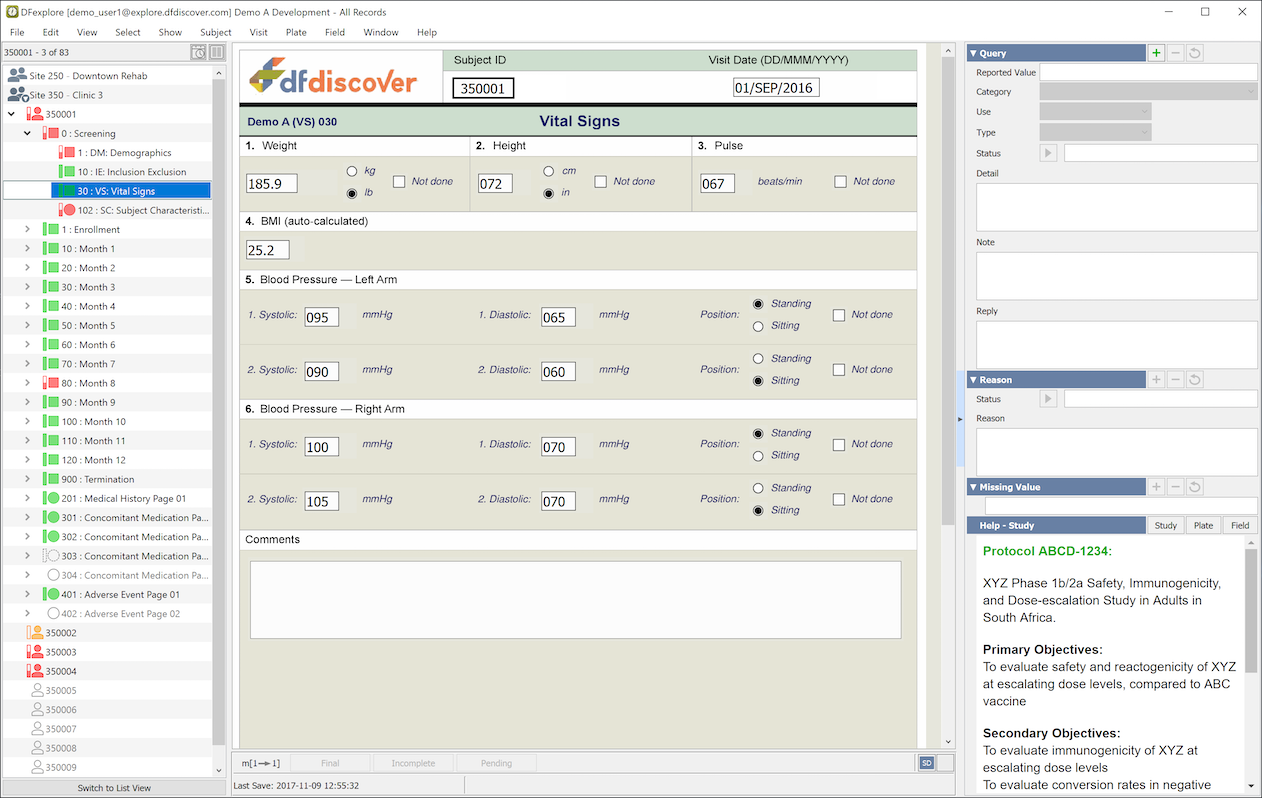
The Data View is organized as a list of subject binders. Subject binders are nested under clinical sites, and displayed in a list on the left side of the window. Only sites and subject binders for which you have been granted permissions are visible.
Double-clicking a site opens it, revealing the subject binders; double-clicking a binder opens it, revealing the subject visits. Visits are opened by clicking the arrow or double-clicking the visit label. This reveals the pages belonging to each visit. Only one subject binder can be open at a time, but multiple visits within the binder can be open simultaneously. Double-clicking the label for an open visit, subject or site closes it. Opening a new binder, or a new site, automatically closes the current one.
Clicking the square button
(  )
at the top of the record list panel toggles
between subject binder and list navigation.
In list navigation, the binders are replaced by columns showing:
status icon, site, subject, visit, plate and workflow level
for all records in the current subject binder, without needing to open each visit.
It can also be used when working on a task set, in which case only task records are shown.
)
at the top of the record list panel toggles
between subject binder and list navigation.
In list navigation, the binders are replaced by columns showing:
status icon, site, subject, visit, plate and workflow level
for all records in the current subject binder, without needing to open each visit.
It can also be used when working on a task set, in which case only task records are shown.
Visits and the pages within each visit are shown in visit map order, regardless of which navigation method is used.
Different icons and colors indicate the status of subjects, visits and pages. Subject icons have two visual indicators, a vertical scale (rectangle) and a subject outline. The possible combinations are:
-
 Subject outline, no scale - a new subject binder, not yet started
Subject outline, no scale - a new subject binder, not yet started -
 Green, filled scale - no problems, all pages entered so far
have status final
Green, filled scale - no problems, all pages entered so far
have status final
-
 Red, half filled scale - one or more pages entered so far has
status incomplete
Red, half filled scale - one or more pages entered so far has
status incomplete
-
 Orange, outline scale - one or more pages entered so far has
status pending and no pages are incomplete
Orange, outline scale - one or more pages entered so far has
status pending and no pages are incomplete
-
 Grey, dashed outline scale - all pages completed so far have
been marked missed (i.e. unavailable)
Grey, dashed outline scale - all pages completed so far have
been marked missed (i.e. unavailable)
Visit and page icons use the same colors and additional scale, with the same meaning, but they come in different shapes to indicate if they are required.
-
 Square - a required visit or page
Square - a required visit or page
-
 Circle - an optional visit or page which may not be
relevant for all subjects
Circle - an optional visit or page which may not be
relevant for all subjects
-
 Diamond - an unexpected visit or page
Diamond - an unexpected visit or page
In addition to a data value, each field may have other information; data about the data, often referred to as metadata.
Metadata is displayed in one of two styles: bottom-left (positioned below the subject binder list) or in the metadata editor panel (right of the data window). The style used is determined by the setting for the Display metadata editor panel preference.
If the current field in the data window has metadata, the metadata is displayed in 3 sub-panels:
-
Query - queries are requests for corrections or additional information from the study coordinating site. A query can be up to 500 characters long and has a status of:
outstanding - the query still needs to be addressed
pending - the query has been addressed but the solution has not yet been reviewed by the study coordinating site
resolved - the query has been addressed and the solution has been accepted by the study coordinating site
You can reply to a query by clicking the button (
),
entering a reply in the Reply field,
or selecting
> .
After a reply is entered, the Query status
changes to Pending.There may be multiple queries on a field; if so, this will be evident from the query count on the upper-left corner of the field widget when the queried field has the focus. Use the arrow keys in the Query panel to navigate between queries and, if required, reply to each one individually.
Some queries do not require a reply and can be resolved simply by correcting the data field. A blank field with query category 'missing', or an illegal field with query category 'illegal', is resolved by entering a legal value.
If a query requests a data correction which cannot be made because the current value is correct, you can respond either by replying to the query or adding a reason to explain the current value.
-
Reason - reasons are entered to explain unusual data values by clicking the add button (
),
in the Reason panel.
A dialog appears where you can type a reason (500 characters maximum)
or select one of the standard reasons defined for the study.
For example, if a field turns red because the value you have entered
is considered illegal, you could add a reason to explain the value -
this might be sufficient to avoid receiving a query from the study
coordinating site.When you add a new reason, or change an existing one, the field turns orange with status pending to signal that it should be reviewed by the study coordinating site.
If you change a field that already has a reason you are required to provide a new reason explaining why the value has been changed. This ensures that the reason displayed is always related to the current value.
-
Missing Value - if the study has been configured to use one or more predefined reasons explaining why a field has no value, you can select one of these reasons using on the Missing Value window, and keyboard shortcut Control+M (Command+M on macOS) can be used to apply the most recently used missing value code to a new field. However, a missing value cannot be assigned to fields defined in the database as essential.
Colors indicate the status of data fields and whether they have associated metadata (queries, reasons and/or missing values).
The colors used for fields without metadata are:
-
White - legal values
-
Red - illegal values or blank, required fields
The colors used for fields with metadata are:
-
Blue - fields with outstanding metadata: an unresolved query or a rejected reason
-
Orange - fields with pending metadata (and no outstanding metadata): a reason or query reply that has not yet been reviewed by the coordinating site
-
Green - fields with approved metadata (and no outstanding or pending metadata): a resolved query, an accepted reason, or a predefined missing value code
If more than one color might apply, descending priority order is: blue, orange, and then green.
Entering data is very similar to completing paper forms, with a computer mouse and keyboard replacing pen and ink. You can go to any field by selecting it with the mouse, move to the next field using Tab or Return, or move back to the previous field using Shift+Tab or Shift+Return.
The current field is highlighted in the data window. If legal values or other help text has been defined for the current field it appears in the bottom-right corner of the DFexplore window.
All entry of data values and metadata (query replies, reasons and missing values) apply to the current field. Be certain that the correct field is highlighted in the Data window before entering data and metadata. If multiple queries are present on a field, be certain that the correct query is selected by using the arrow buttons in the upper-left corner of the Query window before replying to the query.
Choice fields, which allow you to select one choice from the listed response options, are displayed with a small circle beside each option; a 'filled-in' circle denotes the currently selected option. You can select a response option by clicking the circle with the mouse, or by using the number keys - 1 for the first option, 2 for the next, etc. The current option can be removed, returning the field to blank, by pressing Delete (or Backspace).
String fields support UNICODE characters from the en_US.UTF-8 locale.
During data entry, DFexplore blocks use of the |
character - this character is reserved internally and used as the
field delimiter in data and metadata records.
Changes made to each page need to be saved before moving to another page. If you click a different page before saving changes, a dialog asks for confirmation to save or discard any changes before proceeding.
You can save changes to data and metadata and move the record to the save level by selecting one of the available Save buttons at the bottom of the data window.
-
- data entry is complete; there are no outstanding problems (no red or blue fields)
-
- additional work is needed to complete this page
-
- use this option during new data entry to indicate that you have not finished your first pass through the page and want to complete it before it is reviewed by the study coordinating site
-
- this button is only available on records that have been marked 'Missed'. Use it to indicate that you have completed a task, to move the record to the save level, or to save a query that may have been added to the subject ID field.
is the only button available if the page has been marked 'Missed'.
is unavailable if the page has any problem fields.
is available even if the page has no obvious problem fields. This allows you to flag a record as needing subsequent review, regardless of the reason.
is unavailable if the page has advanced beyond new data entry to Incomplete or Final status. Note that pending is available if your permissions include 'Data View - with select'. This permission is typically restricted to study coordinating personnel who may demote problem records to Pending status to exclude them from statistical analyses until the problem is resolved.
Each data record has 4 numeric key fields: Study, Page, Visit and Subject. Together they uniquely identify each data record in the study database. It is critical that these keys are correct. In most instances they are automatically set to the correct values.
If you discover an error in one or more keys, it can be corrected by selecting > and correcting the values in the dialog.
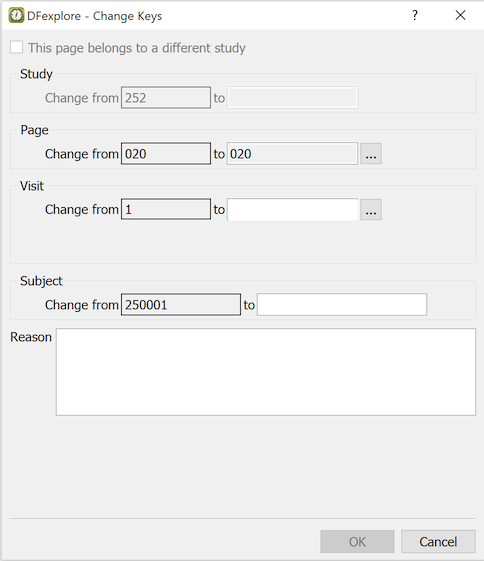
The study number can only be changed if the data record has an image. When the study number is changed all images are sent to the router and the data record is deleted from the current study. It is not possible to move a data record directly to another study even if you have the necessary permissions.
Changing any or all of the other 3 keys (page, visit and subject) moves the data record to another location in the current subject binder, or to another subject binder. All queries, reasons and images move with the data record.
A reason may be specified to explain the change. This is recommended, but is optional.
Click to confirm the change. Checks are conducted to confirm that the new plate is compatible with the old one. An additional check is performed to determine if a data record with the new keys already exists in the database. Depending on the result of these two checks, one of the following confirmation dialogs is presented:
No existing record but pages are not compatible.
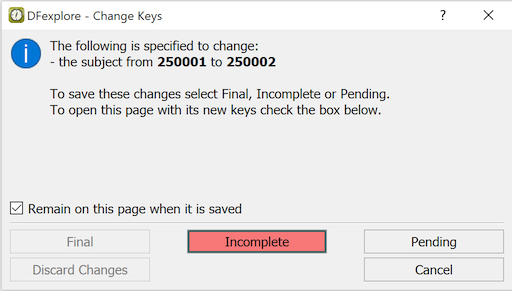
If the new page has different data fields from the old one, the existing data, queries and reasons can not be transferred and must be discarded. In this case a warning message is displayed. Click if you do not wish to continue, or choose a save option to proceed with the key change. If you check , the page opens in it's new binder location. This is recommended.
No existing record and pages are compatible.
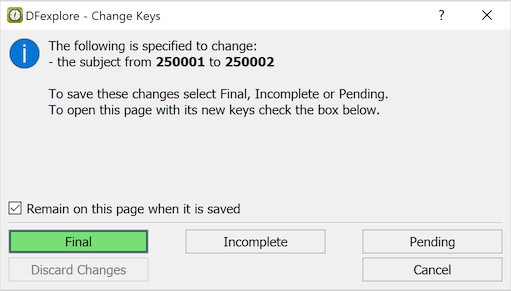
In this example, only the subject ID is being changed. Since the pages are the same they have the same data fields and thus it is possible to transfer the data record to the new keys. Click if you do not wish to continue, or one of the Save options: , or to proceed with the key change.
New keys already exist and pages are compatible.
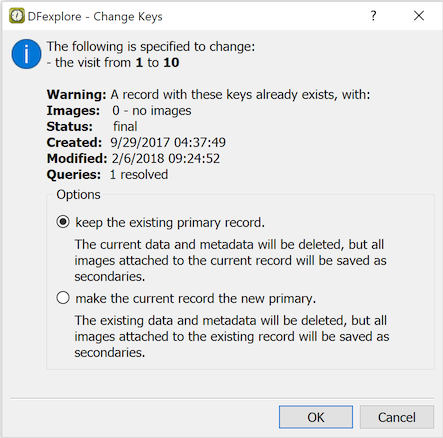
If a data record already exists with the new keys you can either cancel the key change or continue by selecting one of the two conflict resolution options. If you chose to keep the existing primary record it is not changed in any way, and the current data record with all of it's queries and reasons is deleted. The only thing that moves to the new keys is any images from the current page. If you chose to make the current record primary, it is moved with all of it's queries, reasons and images to the new keys, and the existing data record with all of it's queries and reasons is deleted. Images only are preserved from the existing record and they become secondary.
New keys already exist but pages are not compatible.
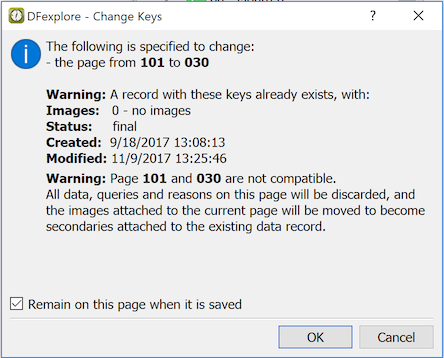
If a data record already exists with the new keys, and the data fields on the current page differ from those on the existing page, you can either cancel the key change or continue. If you chose to continue, the existing data record is not changed in any way. The data on the current page cannot be moved because the data fields are different on the new page, thus all data, queries and reasons on the current page are discarded. The only thing that moves to the new keys is any images from the current page; and if the existing page already has images, all moved images become secondary.
DFdiscover can receive scanned, faxed or otherwise generated images and link them to data records. An image can be a faxed copy of the original paper case report form, a supporting source document from medical records (i.e. DICOM), or other audio-visual files generated by medical imaging devices. The image or supporting document can be in landscape or portrait orientation.
Each image or supporting document must be linked to one and only one data record. Images such as video files or multi-page documents are displayed with controls that permit playing the file or navigating the document.
Multiple images or documents may be linked to the same data record
(e.g. all faxed copies of the original CRF page as corrected over time).
One image must be designated as the 'primary' copy.
This is the image or document that appears along with the data
record when the screen is split in data and list views. All other
images are designated as 'secondary'.
They are reviewed by selecting
> or
clicking the image counter
( )in Data View.
)in Data View.
If one or more images have been linked to the current data record,
two additional buttons appear with the image counter,
 .
Clicking the image button (
.
Clicking the image button (  )
toggles visibility of the primary image.
The behavior varies depending upon the setting for
Image Window : Display method in the
> dialog.
)
toggles visibility of the primary image.
The behavior varies depending upon the setting for
Image Window : Display method in the
> dialog.
The first (left-most) button reports the number of images linked to the current data record. Click this button, or select > , to access the Review Images dialog.
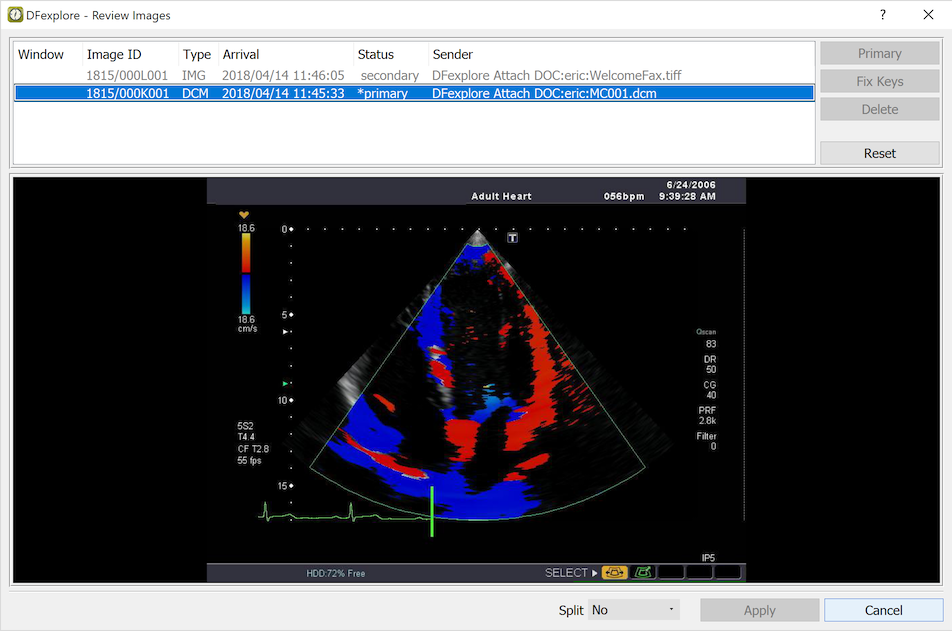
This dialog shows all images linked to the current data record. It shows each Image ID, image Type, Arrival (when the image was received), Status (whether it is the primary or a secondary image), and the Sender (identification of the sender). This dialog is used to:
Review Images. Select any image from the image list to display that image.
Split. The drop-down has 3 choices: No, Top-Bottom and Left-Right. When the window is split, click any 2 images in the image list to display them together. Double-clicking one of the images in the image list switches them between the two display windows.
Specify the Primary Image. When the dialog opens the primary image is tagged with an asterisk ( * ) in the image list. Selecting a secondary image and clicking changes that image to primary and demotes the original primary image to secondary. The asterisk however remains on the original primary image as a reminder of which image was primary when the dialog was opened. Changes in image status do not take effect until is clicked.
Delete Images. Select an image and then click to change Status to 'deleted' (this does not take effect until is clicked). Status can be changed from 'deleted' back to 'primary' or 'secondary' by clicking . Once is clicked this is no longer possible. If there is more than one image, the primary cannot be deleted until all secondary images have been deleted.
Fix Keys. If an image has been linked to the wrong data record you can re-link it to the correct record by clicking and entering the correct subject ID, visit and/or plate numbers. The image is unlinked from the current data record and linked as a secondary image to the data record of the new keys. If necessary, the new record can subsequently be opened to change the image status from secondary to primary.
For documents that are transmitted and received with quality settings higher than black-and-white fax quality (grayscale and color PDFs for example), it is possible to also locally view such documents using HD mode in DFexplore.
The default is to view images at standard definition (SD), which is equivalent to historical black-and-white, 100 dpi fax quality. The central data management office can enable HD images (300 dpi) to be received for a study via DFadmin. Individual users can determine if they wish to view the HD images in DFexplore, if it is available.
To enable the HD setting in DFexplore, toggle the
SD button
 at the the lower-right corner of the the screen in Data View,
which changes to:
at the the lower-right corner of the the screen in Data View,
which changes to:
 .
If there is an HD version of the image available, the screen refreshes with
the HD image. If HD is not enabled at the study level or an HD image was not
transmitted, the SD/HD toggle changes to
.
If there is an HD version of the image available, the screen refreshes with
the HD image. If HD is not enabled at the study level or an HD image was not
transmitted, the SD/HD toggle changes to
 to indicate that
there is no HD version of the image available:
the HD setting is enabled but the SD image is displayed.
to indicate that
there is no HD version of the image available:
the HD setting is enabled but the SD image is displayed.
Like other screen settings, the HD setting is stored locally in your device-specific settings. For example, this allows you to easily work over a slower laptop connection with HD mode disabled. HD mode can be enabled on another device (an office computer perhaps) which has a fast internet connection.
Tasks, which are user instructions and record retrieval specifications, can be defined and assigned to individual users or study roles. Any user with access to Data View can perform tasks. However, 'Data with Select' permission is required to define tasks.
It is also possible to export and import tasks, even from other studies. The export dialog is a standard dialog that simply prompts for a file name using either .dat or .txt file name extensions. The import dialog is an extension of the task definition dialog that allows selection and import of a previously exported task definition as a starting point for the new task definition.
To perform a task, select > . Alternatively, use the Data View Tasks pull-right from Dashboard View.
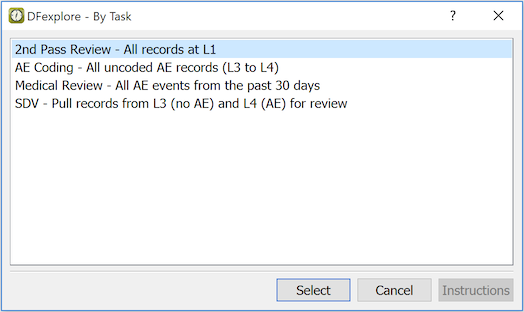
Only tasks assigned to your login or study role are listed in this dialog.
If available, task instructions can be viewed before starting the task by clicking .
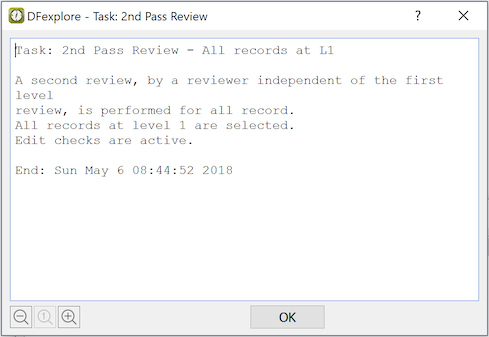
Instructions are specified when the task is created, and can subsequently be modified.
To perform a task, double-click it in the list, or highlight it and click .
After selecting a task, a confirmation dialog with the task instructions (if available) and the number of records matching the task criteria is displayed.
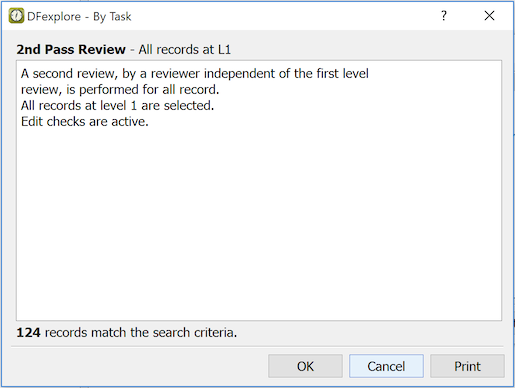
Confirm the retrieval by clicking .
The subsequent task record list includes those records (sites, subjects and visits) with matching task criteria. If your user preference Open first task record when task set is built is enabled, the first task record opens automatically; otherwise a subject binder must be selected to display the task records.
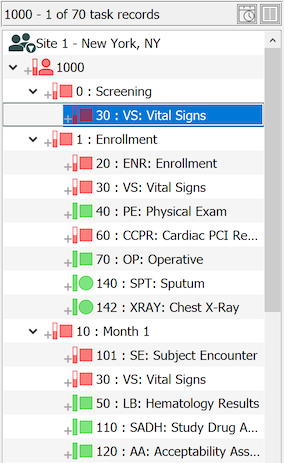
The title shows the current subject ID, the current task record and the number of task records for this subject.
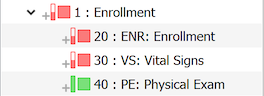
Task records are flagged with a plus symbol
(  )
which changes to a checkmark (
)
which changes to a checkmark (  )
when the record is saved, indicating that the task for that record
has been completed.
The current record counts are displayed at the bottom
of the DFexplore window (
)
when the record is saved, indicating that the task for that record
has been completed.
The current record counts are displayed at the bottom
of the DFexplore window (  ).
).
Click to open the subject binder and review other records for the current subject. Click the button again to return to Task Records only.
More than one user can work on the same task at the same time. Each user gets a list of pointers to the records currently available for the task, but a subject binder is locked only when it is opened, and only one user can have the binder locked at a time. Other users are able to open the binder in view only mode until the lock is released.
Saving a task record changes the task icon from
to
, but only for
the user who saved the record.
Thus if more than one user is working on the same task at the same time,
it is possible that the task has been completed by one user
before another user opens the subject binder, and that the second user
may wonder why the record has been included in the task set.
A clue that this may have occurred is provided by the value for
Last Save at the bottom of the screen - it
may indicate that the record has
been modified since the user began working on the task.
When you are finished performing a task, select > to dismiss the task set. This removes the icons from task records, and resumes access to all subject binders and data records.
Users with permission can define tasks for themselves and other users using the task definition dialog. Only one user can define tasks at a time, but other users can open this dialog in view only mode.
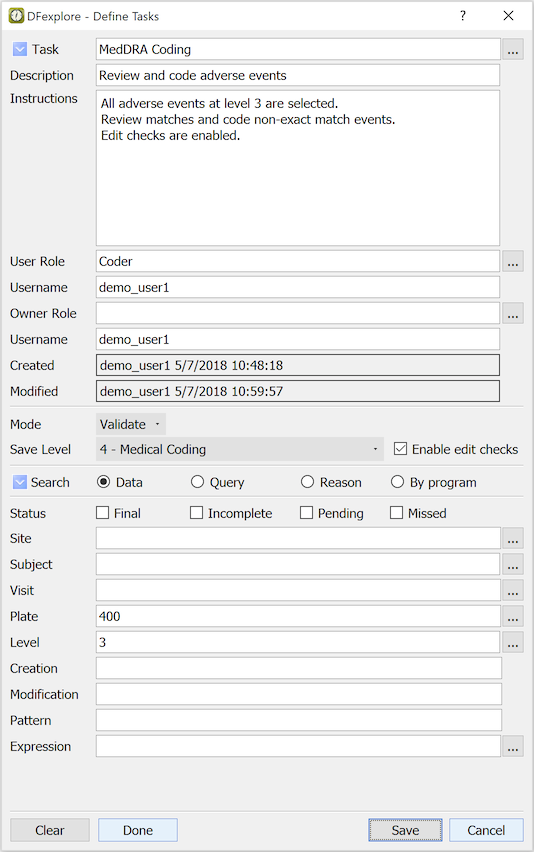
Task definitions have the following properties:
Task name, Description and Instructions document the meaning and purpose of the task.
User Role and Username identify who is allowed to perform the task.
Owner Role and Username identify who is allowed to modify the task definition. In addition, study administrators have permission to modify all tasks.
Specify a Mode and Save Level to indicate how each record level should be updated. Mark Enable edit checks to indicate that edit checks fire (or not) when the task records are retrieved and traversed.
Save Level is a number (1-7) that is stored as a special field (
DFLEVEL) in each data and metadata record for workflow management. New data entry is typically saved at level 1. Higher levels are used to indicate that some review task has been completed - analogous to moving paper CRFs from one person's inbox to another.The final section is for record selection by record metadata and record properties. It includes data, query or reason criteria, or any standard DFdiscover or custom program that outputs a data retrieval file.
Multiple user and owner roles, and usernames, may be entered using a comma delimited list.
Task ownership specifications are ignored for study users with DFdiscover or study administrator privileges. These special users can view, edit and delete any task including those created by other users.
The task set returned to each user depends on their role permissions, and equals the intersection set created by the task retrieval criteria and the user's permissions. Thus it is not possible to grant extra permissions to a user within a task definition. For example, one task can be defined and used by all of the clinical sites because each site receives only the data records they are allowed to see.
This section includes several example task definitions. These examples illustrate how data, query, reason and program criteria are used to define the records to be selected for different tasks.
Example 5.1. Review Task for drug coding
This example illustrates a review task for drugs recorded on plate 400 which have reached workflow level 3. The expression builder (not shown here has been used to select records where the 'check if none' data field (MEDNONE) is empty (code 0) because we only need to review pages on which drugs have been recorded.
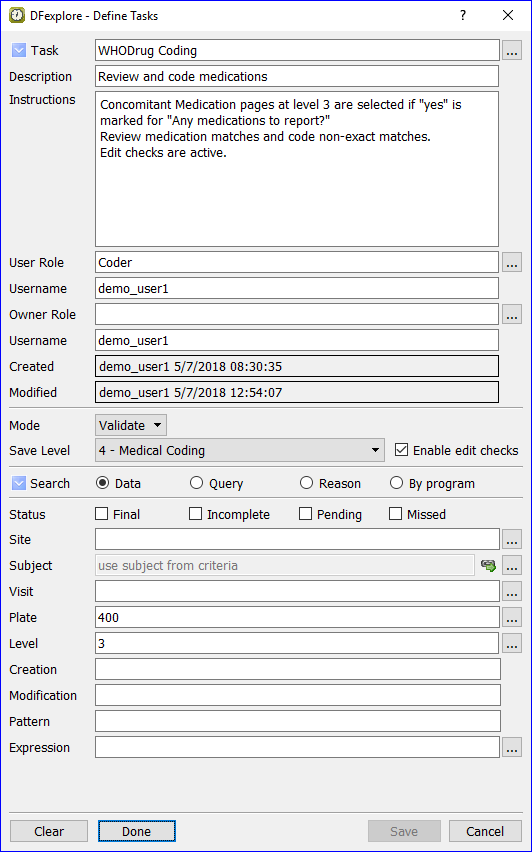
To be selected, records must meet all of the specified criteria. The task is performed in Validate mode with edit checks turned on. Each saved record has its save level raised from 3 to 4.
The expression builder is accessed via next to the Subject field, Selecting Subjects based on Criteria, and implements subject selection based on multiple criteria across multiple plates.
This example illustrates a task for someone who reviews new queries created by data entry staff during new data entry at level 1, to make sure they are clear and appropriate before being sent to the clinical sites in a Query Report.
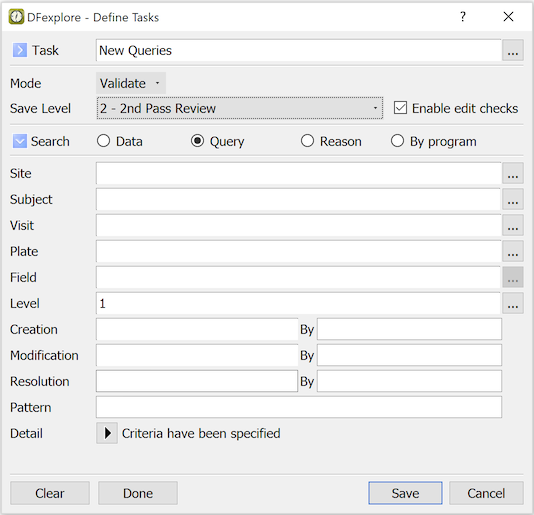
This task should be performed using the > dialog so that queries can be saved on their own, raising them to level 2 without changing the workflow level of the data records.
The additional Query Detail dialog is used to specify the unique query criteria.
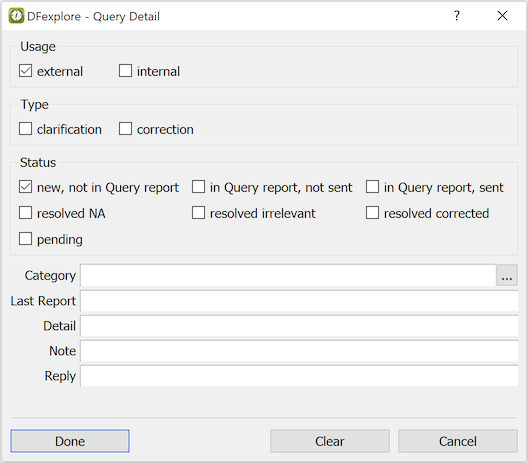
Example 5.3. New Reasons Review
New reasons entered to explain data values are set to status Pending with the expectation that they are reviewed and either approved or rejected, along with a query explaining why and requesting a correction or additional information.
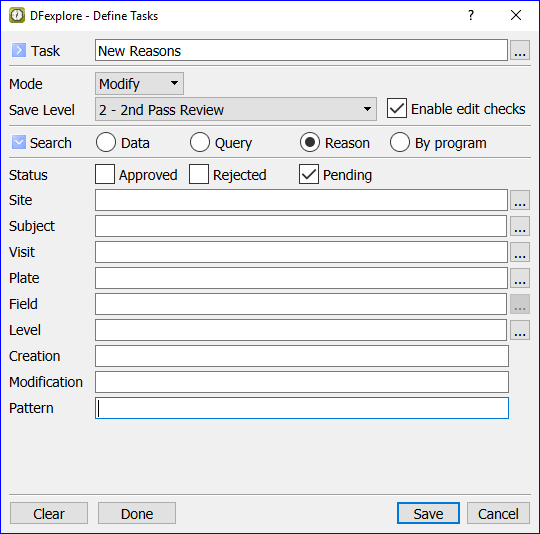
Task records = all data records with reasons that have status Pending. Mode is set to Modify and the sign off level is set to 2. We could also have used Edit mode which would leave the reasons at their current workflow level.
This task should also be performed using the > dialog.
The following examples illustrate how tasks can be defined by running a program that generates a data retrieval file as output.
DFdiscover includes 2 standard programs which are designed for this purpose: which selects records from the study journal files and which selects records identified by edit checks. A few examples are shown here.
A full description of these programs can be found in the Section A.4, “Programs”. If you need to write a custom program, an explanation of data retrieval files can be found in Programmer Guide, Data Retrieval Files (DRF).
Example 5.4. Image Review with Double Data Entry
In this example, double data entry (i.e. Mode=DDE) is performed on data records
saved by other users (-xu whoami)
with associated images (-image yes),
which were at level 1 (-v 1)
with status final or incomplete (-s final, incomplete) at any time during
the study, and still meet these criteria today (-d 2).
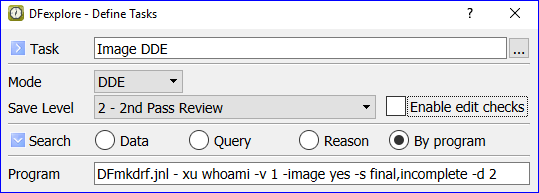
Example 5.5. Image Review without Double Data Entry
Instead of performing double data entry, it may be considered adequate to review level 1 data entry records and move them to level 2. If so, the same retrieval criteria can be used with Validate instead of DDE mode.
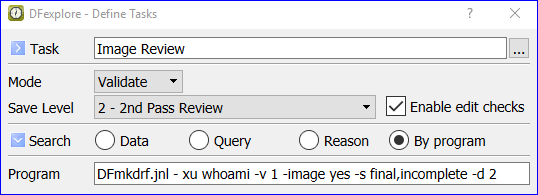
Example 5.6. Search for Today's Records
Users sometimes forget exactly what case they were working on earlier in the
day but want to retrieve it so they can check something or make a change.
With no deselection (-d) option specified, records are retrieved even if
subsequently saved today by someone else.
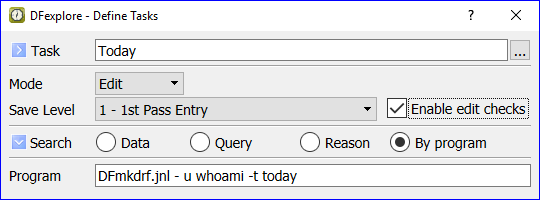
The edit check programming language gives the programmer access to all data fields
for all plates, visits and subjects, and includes functions that can be used to test for
the existence and status of queries and reasons.
Thus it is ideally suited for the definition of tasks that involve complicated
record retrieval criteria. All the programmer needs to do is raise a message
using dfwarning or create a query using dfaddqc
on records that are to be selected, and use function dfbatch if the edit check
is to be executed only when the task is being performed.
Example 5.7. Search by All Edit check Results
This task runs all edit checks (-E ALL) on plate 1 (-P 1) data
records that are currently at level 1 (-v 1). No edit check actions
are applied. Instead records are retrieved if one or more
edit checks would have added a new query, modified an existing query,
displayed a message, or changed a data field.
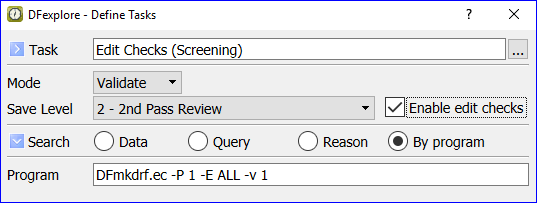
Example 5.8. Search by Specific Edit check Result
In this example the edit check (-E CheckInit)
is programmed to check subject initials and display a warning message
if they differ from some reference value.
In this task, the edit check is run on all pages used in the study (-P 1-102) and
thus retrieves all records on which this message would be displayed.
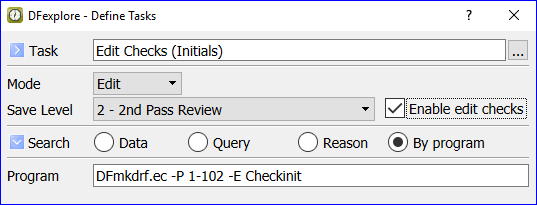
Example 5.9. Search by Custom Edit check
The following example shows how an edit check could be used to find unusually large changes in diastolic or systolic blood pressure between visits. It could be programmed to add a query if a suspicious change is found, and to do nothing if a query for this category has already been added to the blood pressure field in question.
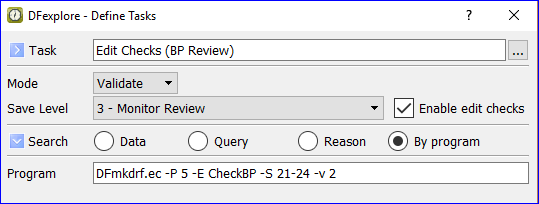
In this example
edit check (-E CheckBP) is triggered on page 5 (-P 5) at all
follow-up visits (-S 21-24) which are currently at level 2 (-v 2).
By running this edit check in a task, you can review the blood pressure readings recorded on the submitted CRF pages and verify that any unexpected changes are not the result of data entry errors.
In addition to using predefined tasks to select data records and set workflow modes and levels, users who have Data with Select permission can perform ad hoc retrievals using the same dialogs that are used to define tasks. Working in this way requires an understanding of the study workflow plan and is thus most appropriate for central data management staff. This permission typically is not enabled for clinical sites and thus the features described here may not be available to all users.
DFexplore allows you to work in 5 different modes and to keep track of data reviews and other tasks by moving records from one workflow level to another when a task has been completed.
The default mode, defined when DFexplore starts, is Modify and the default save level is set to your lowest write level (defined in your study roles). Mode, save level, and whether edit checks are enabled, are also set whenever you perform a task or build an ad hoc task set. They can also be changed at any time by selecting > .
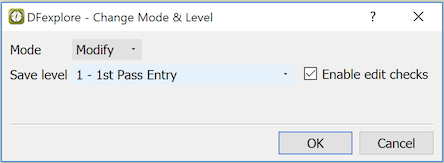
The choices for Mode include:
-
View. No changes can be made to data or metadata, and no changes are made to the workflow level.
-
Edit. Changes can be made to data and metadata (as permitted by user permissions). New and modified metadata are saved at the current level of the data record, and the level of the data record itself remains unchanged.
-
Modify. The workflow level is changed to the specified Save Level, only for those data and metadata records that are modified. It is possible for data and metadata records to end up at different levels.
-
Validate. The workflow level of data and all metadata records is changed to the Save Level when a Save button (Final, Incomplete or Pending) is selected, regardless of whether or not any changes were made to data or metadata.
-
DDE. The current data values and metadata are hidden until you exit each data field, at which time the value entered is compared with the current value in the database. If they differ a dialog appears asking you to select the correct value. You must tab through all data fields before the record can be saved. During save, the data record and all metadata records move to the Save Level. > can be used to check the changes made so far and the data fields that remain to be entered on the current data record.
The dialog can be used to change mode, save level, and to enable or disable edit checks. It is available to users who have Data with Select permission.
The current mode and save level are shown to the left of the Save buttons at the bottom of the screen. For example, Save m[1->2] indicates that we are in Modify mode with a sign off level of 2, and that the data record is currently at level 1. Modes are identified by the letter m for Modify, e for Edit, v for Validate, and d for DDE.
When in View mode only the current workflow level is shown, e.g. Save [3], and the message view mode is displayed to the right of the save buttons.
Ad hoc task sets can be created using the same record selection dialogs already described in the section on defining tasks. As with predefined task sets, the records in an ad hoc task set are also flagged with the 'T' and 't' icons. To get started, select > .
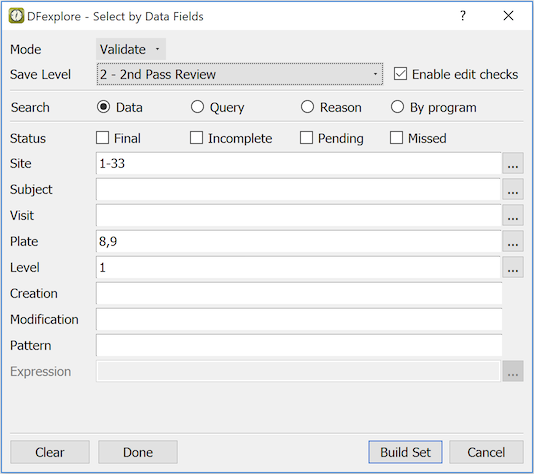
To be selected a record must meet all of the specified criteria. Criteria that are left blank are irrelevant. The search criteria restrict the search to data records, query records or reason records. For example, when searching for records at level 1 you will obtain different results depending on whether you are searching for level 1 in data, query or reason records.
In this example, Plates 8 and 9 that are at workflow Level 1 with status Final are selected for all subjects at Sites 1 to 33. The selected records are to be reviewed in Validate mode with a save level of 2. Thus, whether or not a record is modified, it is raised to level 2 if it is saved using one of the Save buttons.
If you click , the dialog remains open and you are able to add more records to the ad hoc task set by specifying a new set of criteria and again clicking .
Click when you are finished building your task set and you are ready to review the records.
In addition to the record selection criteria, the dialog requires specification of the Mode and Save Level. These settings apply to both data and metadata records.
It is important to remember that modes do not grant any permission that you do not already have. Permission to view and modify data and metadata are controlled by study roles defined and assigned to users by the study management team. Thus, you are only able to select records you are allowed to see, and regardless of the mode you select, you are only able to modify data and metadata for which you have modify permission.
When you click a confirmation dialog indicates the number of records in the database that match the selection criteria. Click to proceed or to abort the selection.
If you proceed, the record list is reduced to show only those sites, subjects and visits that contain records in the ad hoc task set, and each of these records is flagged with the task icon. Just as with predefined tasks, the not completed task icon (plus symbol) changes to the completed task icon (checkmark) when a task record is saved. This shows that the record has been reviewed but does not necessarily mean that the task has been completed as intended. If the record still meets the selection criteria for the task it will come up again the next time the task is performed. All other sites, subjects, visits and records are hidden.
To toggle the current subject between task records and all records, click at the bottom of the task records list. The entire record list containing all sites and subjects can also be toggled using the menu items > and > .
This option can be used to retrieve data records listed in a Data Retrieval File (DRF).
These files all have a .drf extension. They can be loaded from either
the study drf folder or your local computer.
DRFs can be created by standard DFdiscover reports,
by saving a current task set using > ,
by using or
(described in Section A.4, “Programs”) or with a custom program (described in
Task Definition by Program).
To retrieve records listed in a DRF, select > .
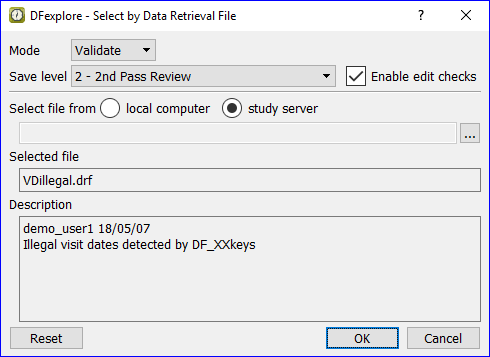
The DRF in this example is named VDillegal.drf.
This is a standard DFdiscover DRF which lists illegal visit dates detected
by DFdiscover report DF_XXkeys.
Validate mode is specified which means that the workflow level of existing data and metadata records are changed to 2. The file is selected from the study server, as this is a standard DRF. If the DRF contains a descriptive header it is displayed in this dialog when the file is selected. If each record in the DRF includes a description (e.g. explaining why it was included) it is displayed in DFexplore's message window when a record is selected in the record list. The message is optional and may not be present in all cases.
The Batch Validate feature is used to move all matching data records to a specified workflow level in one step. You require permission for Data with Select to use this feature. Data records may only be batch validated if they meet all of the following criteria:
You are able to retrieve the records. Records that you do not have permission to get, or which are currently locked by another user, cannot be batch validated.
Record status is final, incomplete, pending or missed. New records cannot be batch validated.
The records are currently at levels for which you have modify permission.
You can only move records to levels for which you have write permission.
There are 3 batch validate selection options: move the current page only, move all open pages for the current subject, and move all records in the current task set.
In this example all open pages for the current subject are moved to workflow level 3 when is clicked. The open pages could include visits opened by selecting them in the record list (using > ) or as the result of a predefined or ad hoc task.
After clicking , a confirmation dialog requesting your username and password is presented. This batch action requires your username and password for the first use, and for subsequent uses your password only. The specified records are moved immediately. No edit checks are triggered.
Some tasks require selecting an item from a predefined lookup table. This functionality is implemented in DFexplore using an edit check to achieve the desired behavior. For example, the edit check might be programmed to provide the lookup table to only specified users, users with specified roles, or users performing a specified task; and the lookup table might always appear on entry to some data field or only when an exact match can not be found automatically.
Regardless of how the edit check is programmed, if a lookup table appears while performing data entry, you are able to search the lookup table and select one of its entries (rows), or click to select none of them.
This example shows a lookup table which has been created for MedDRA coding. The division of each row into fields, the field labels, the order in which they appear, which fields are shown in the dialog, and which fields are returned to the edit check when a row is selected, are all customizable by the edit check programmer.
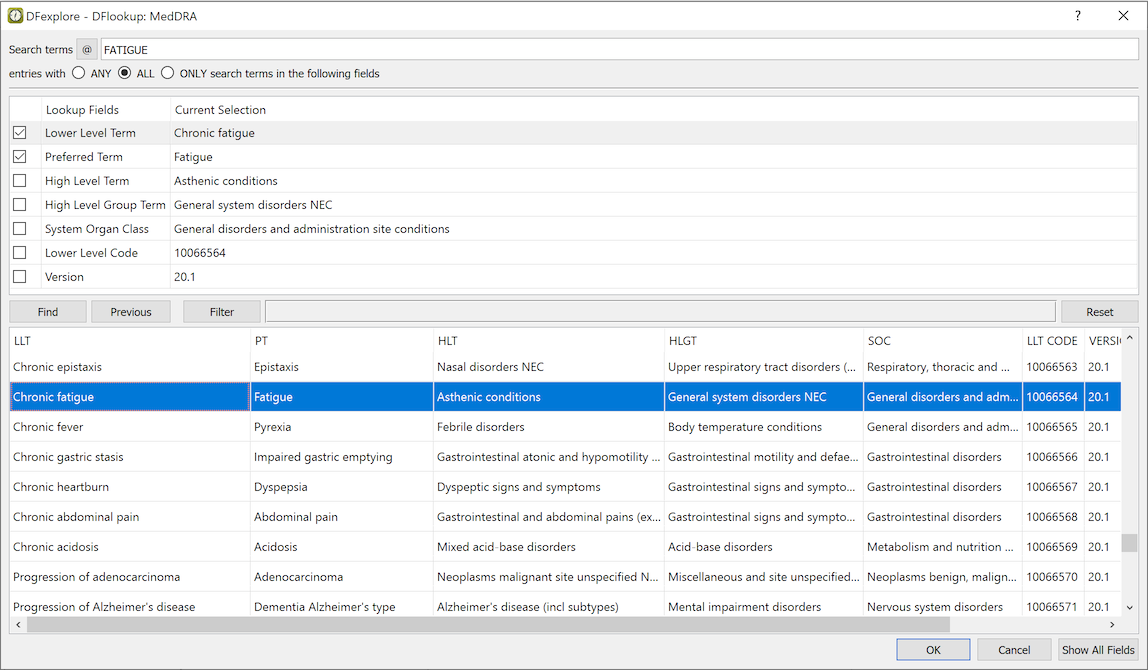
The top section of the dialog shows the field labels and the field values in the currently selected row. The bottom section is a scrolling list of all rows in the lookup table, typically with abbreviated field labels (acronyms) at the top of each column. If all fields can not be seen, click to reduce the display size of each column to fit them all within the current dialog. The size of each column can be adjusted by right-clicking the vertical line separating the field labels and dragging it left or right.
To search for one or more terms enter them in Search Terms,
check the option to find entries that contain ANY, ALL,
or ONLY the terms,
check the fields to be searched, and click or
. displays the
next matching row, while reduces the table to display all matching rows.
After reducing the rows to a filtered set you can enter new search terms and search or filter again within the current rows. Click to display all rows in the lookup table.
When you have found the correct row either double-click it, or highlight it and click . This returns your selection to the edit check and dismisses the lookup table. What happens next depends on what the edit check is programmed to do. Typically all or some of the fields from the row you selected are entered into specified data fields on the current page, but the edit check may be programmed to do something else.
Queries can be created, modified and deleted by edit checks with no user intervention, or manually by selecting , or from the menu. You can also directly add or modify a query in the Metadata editor panel or from the specific Query panel.
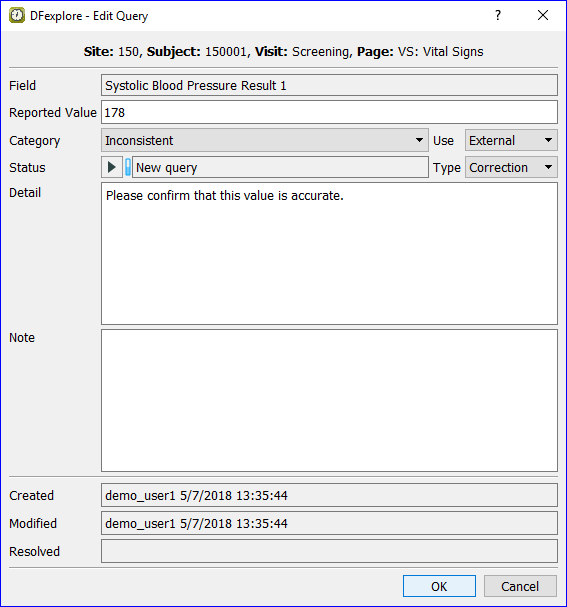
The query dialog has the following components:
-
Title. The title at the top of the dialog shows the context needed to identify which site, subject, visit and page the query is about.
-
Field. The field description, as entered in the study setup, identifies the data field in question.
-
Reported Value. When a new query is created, this field shows the value currently recorded in the data window, but you can change this. For example, if a date is unclear you might enter a best guess in the data window but change the query to indicate that the year was unclear (e.g. Jan ??,2017).
-
Category. The category type can be one of the following default categories: missing, illegal, inconsistent, illegible, fax noise, and other. It may also be any user-defined category. The category cannot be edited after the query is created. Although multiple queries are allowed on a single field, at most one query of each category is permitted per field.
-
Use. Use can be
external, meaning the query is directed to the clinical site; orinternal, indicating it is for the data management site only. -
Status. The status of each query is updated as appropriate to one of the following:
-
New. The query addresses a new question which has not yet been transmitted to the clinical site.
-
Revised. The query addresses a revised question which has not yet been transmitted to the clinical site.
-
Outstanding. The query has been transmitted to the clinical site but has not yet been resolved.
-
Pending. The site has responded to the query but the reply has not yet been reviewed by the data management site.
-
Resolved NA. The query has been resolved - the requested data or correction is Not Available.
-
Resolved irrelevant. The query has been resolved - the query was deemed to have been unnecessary.
-
Resolved corrected. The query has been resolved - the requested correction or information has been received.
-
-
Type. Type is
Correctionif the query asks for some data correction, orClarificationif the query requests additional information. -
Detail. A description of the issue and the requested resolution can be entered manually or, if standard queries have been predefined, they can be selected by typing a short acronym or using to select the query from a lookup table.
-
Note. An internal note, used only by data management staff, can be entered for any internal purpose, such as recording special circumstances explaining why or how a query was resolved.
-
Timestamps. The creation timestamp is updated when a query is saved with status
New. The modification timestamp is generated when a query is saved after modification of any of the fields described above. The resolution time stamp is updated when Status is changed to one of the 3 resolution types.
Clicking saves the query locally. It is applied to the study database when the data record is saved.
Some data queries resolve automatically when the data field is corrected while others do not. For auto resolution to occur all of the following conditions must be met.
Query Use = 'External'
Query Type = 'Correction'
Query Category = 'Missing' or 'Illegal'
The data field does not have a Reason with status 'Rejected'
If all of the above criteria are met then:
if the study setup includes a legal value specification for the data field, then entry of one of the specified legal values resolves the query
-
if legal values have not been specified for the data field, then entry of any value resolves a query with category 'Missing' but not a query with category 'Illegal'.
In addition to the above auto resolution rules, edit check programmers can
resolve queries when certain conditions are met using the edit check function
dfeditqc. In this case there are no restrictions on the type of queries
that can be resolved, other than those imposed by the edit check programmer.
Central office review and approval of reasons and query replies can be performed using > or > .
The dialog looks the same for these two options, but they differ in behavior. The Review dialog lists all queries and reasons on the current page, while the Approve dialog lists only those queries and reasons with status 'Pending'. When a query or reason is changed from status pending to approved or rejected, it is removed from the Approve dialog but remains visible in the Review dialog.
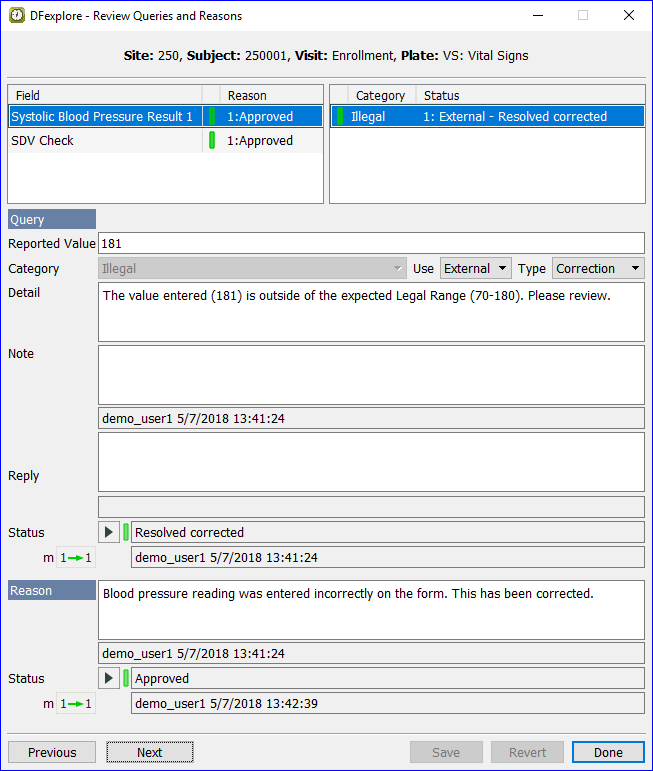
To use this feature, begin by retrieving the records to be reviewed, and if necessary set the working mode and level per study workflow SOPs. Using these dialogs in 'Validate' mode is generally the best choice as it allows you to save the data records and also move them to the same level. Select the Review or Approve dialog and position it beside the data window. As you traverse the data records, all relevant queries and reasons on the current record appear in the dialog. As you select each query and reason in the dialog the relevant data field is highlighted in the data window making it easy to see the relevant item.
The Review/Approve dialogs are generally used to review and approve
new reasons and query replies, but as needed you can also modify or even delete queries
and reasons if your permissions allow. Note: There is one limitation.
Changes cannot be made to queries and reasons on Pending, level 0 data records
as this status indicates that the most recent user was interrupted during the entry of a new record
and intends to complete it before it is reviewed by study managers.
The two buttons below Query Status and Reason Status (each has this appearance
 )
can be used to save your
changes to the current query or reason before moving on to the next one,
or you can delay saving changes until all queries and reasons on the current
data record have been reviewed, in which case an asterisk appears beside
each query and reason with unsaved changes. Click
to save both the reason and query on the current
field.
Click
to dismiss the dialog without saving any changes.
)
can be used to save your
changes to the current query or reason before moving on to the next one,
or you can delay saving changes until all queries and reasons on the current
data record have been reviewed, in which case an asterisk appears beside
each query and reason with unsaved changes. Click
to save both the reason and query on the current
field.
Click
to dismiss the dialog without saving any changes.
If you change the status of a query in these dialogs to 'New' or 'Revised', or you 'Reject' a pending reason, the data field turns blue, and when the query and reason changes are saved the status of the data record changes to 'Incomplete' (if needed) to signify that it contains one or more outstanding problems. On the other hand, approving all of the query and reason replies on a data record does not automatically make it 'Final' but does enable the 'Final' save button, which can be selected if you want to change the data record to status 'Final'.
The Review/Approve dialog allows you to perform workflow management on the metadata independently of the data records. When you have completed your review of the metadata on one page, you can proceed to the next page in the task set. You do not need to save the data record itself, unless you have made changes to data fields that you want to keep or you want to change the data record status and/or level. The workflow level is changed on data and metadata records that you save.
As an alternative to faxing, CRFs can be scanned to a PDF file, and then transmitted to a DFdiscover server. This capability is available via the standalone DFsend application and also within DFexplore using > .
When the server receives the PDF it is processed just like an incoming fax; the pages are reviewed and entered by a user with permission to use Image View, and the pages are inserted into the database and appear in the subject binder.
CRFs can be scanned in black & white, grayscale, or color and saved as a PDF file. There is a limit of 999 pages that can be included in one PDF document.
Start DFexplore and login to the destination DFdiscover server. Since a PDF is processed just like an incoming fax, it doesn't matter which study you are using when you transmit a PDF. The PDF can even contain CRF pages for multiple studies, as long as all pages in the PDF file are for studies that reside on that same DFdiscover server.
If you use different DFdiscover servers for different studies, make sure you select, and login to, the correct server. Transmitting a PDF to the wrong DFdiscover server would be the same as sending a fax to the wrong fax number.
Select > in Data View.
This displays the operating system file selection dialog. Use it to select the PDF file(s) to transmit.
The confirmation dialog identifies the DFdiscover server and each PDF file you selected for transmission. After confirming that these are correct, click to start the transmission.
A progress bar is updated while each PDF transmission is underway. Pressing cancels transmission of any remaining PDFs but does not stop the current transmission.
When the transmissions are complete, the dialog shows the status of each PDF: 'transmitted', 'failed' or 'canceled'. Click to select additional PDFs for transmission. dismisses the dialog.
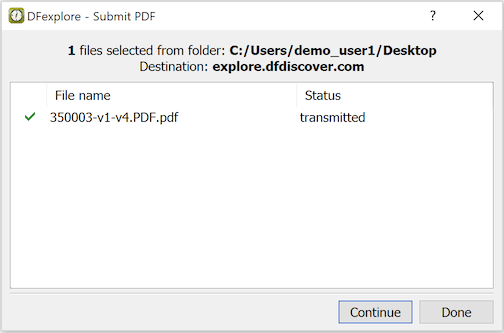
PDFs transmitted to the server from DFexplore are registered in the DFdiscover document log. Each transmitted file is also added to the DFdiscover document archive.
Select > to view the date and time the page was centrally received along with the submission method and user.
To use this feature your study role must include permission for 'DFexplore: Data-Submit PDF'.
This feature is blocked if a study has been 'disabled' or put into 'read-only' mode by a study administrator. If a study is in 'restricted' mode, PDFs can be submitted by study and DFdiscover administrators only.
Transmitting Scanned CRFs sends one or more PDFs to the DFdiscover server for processing in Image View. It is yet another method for adding new CRFs to a study for data entry.
In some cases however, CRFs are not meant for separate data entry. Instead these CRFs may belong to already existing data records. This functionality is available via > for users that have permission to 'Import Subject CRFs'. With this feature, a PDF file is imported and each page can be immediately attached to an appropriate data record.
The imported pages may be supporting documentation e.g. letters, reports, test certificates, etc. or copies of paper CRFs or worksheets containing subject data.
Select > in Data View. From the file selection dialog, select a PDF for import.
The import dialog contains two main sections: a window for reviewing the PDF pages on the right, and a spreadsheet for identifying the data records they belong to on the left.
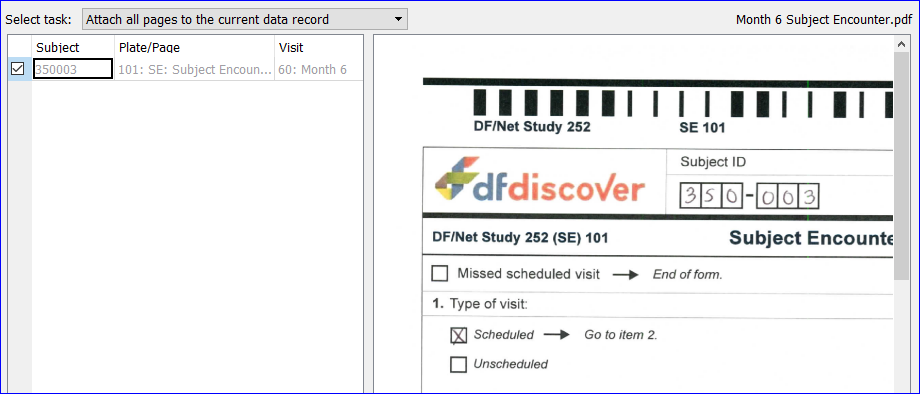
This feature has 3 modes of operation, chosen from the Select task drop-down:
Attach all pages to the current data record. To use this option, the destination data record must be opened before is selected. When the import dialog opens the keys identifying the current data record are displayed in the spreadsheet and cannot be changed. Simply select the check box beside each page you want to import, or click to select all pages. Click . A dialog appears asking you to re-enter your password (you can still at this point). If you proceed and enter your password, the selected pages are imported. A results dialog appears, displaying a summary of the transaction including a list of the pages that were imported. If the current data record had one or more images before import, all imported pages become secondary images, otherwise the first imported page becomes the primary image and the rest become secondary. The imported images can be reviewed and the primary/secondary classification can be changed using the Review Images dialog, which is selected by clicking the image count button at the bottom of the screen or by selecting > .
Attach each page to the data record identified below. Use this option if the PDF contains pages that belong to a number of different data records. To use this option you must be able to identify the data record that is to receive each page by entering its keys (Subject, Plate/Page and Visit) in the spreadsheet. If any of the imported pages are barcoded to identify where they belong in the subject binders, values for Plate/Page and Visit are read from the barcodes; otherwise enter the appropriate numeric value in the spreadsheet, or right-click a cell to use the selection dialog. Enter the Plate/Page number first. The Visit selection list then shows only those values that are consistent with that plate, per the study visit map. To prevent errors DFexplore does not allow pages to be imported if they are barcoded with a different study number. Also, users can only import pages for data records that their study permissions allow them to modify. If a key field contains a value that is illegal or not permitted, the cell appears purple and the page selection check box is not available until the problem keys are corrected. If a page contains a barcode for a different study or the identified record is at a workflow level you cannot modify, a red X replaces the page selection check box indicating that the page cannot be imported. After entering valid keys a check box appears which when checked indicates that the subject binder can be locked and that the page has been selected for import. If the page cannot be imported because the subject binder is locked by another user a lock icon replaces the check box and the message This record is currently locked by another user is displayed. When the pages you want to import have been identified and checked click and enter your password. Each page is attached to the specified data record as a primary or secondary image, as described for the previous option. The assignment is displayed in the results dialog.
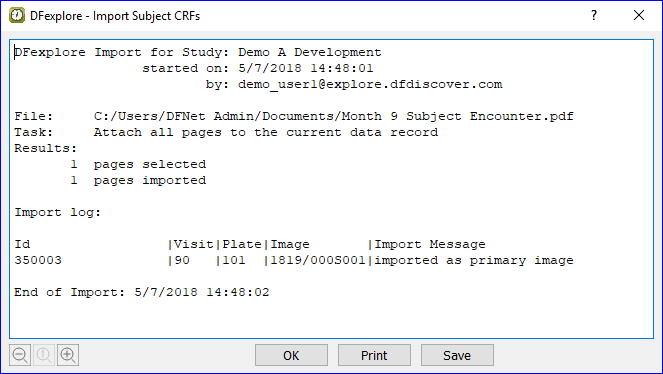
If a page is imported for a data record that does not currently exist in the study database, a pending data record is created and added to the subject binder.
-
Import data entry worksheets/CRFs identified below. Use this option if you want to import worksheets or CRFs on which data has been recorded and then use DFdiscover's split-screen data/image feature to enter the data into the corresponding data records. This option begins like the previous one: the pages to be imported are identified and selected, the import button is clicked and you are prompted to enter your password, after which the selected pages are imported and the results dialog appears. It differs from the previous option as follows:
Only one page can be imported for each data record. If the same keys are entered in the spreadsheet for a second page, the selection check box becomes unavailable for that page.
Each imported page becomes the primary image for its data record. The previous primary image (if any) becomes secondary.
DFexplore builds a task set of all imported pages, and displays the first task record when you close the results dialog. If any of the imported pages did not have a matching data record before import, a data record with pending status is created and added to the task set.
The user performs data entry by comparing the data fields with the values recorded on the imported CRF or worksheet, and entering or correcting the data fields as needed.
All imported pages should be processed before releasing the task set, but if this is not possible they can be saved using > . They can then be retrieved and completed another time using > .
The following keyboard shortcuts may be useful in the import process:
Tab or Right arrow moves forward across the cells in each row.
Shift-Tab or Left arrow moves backward across the cells in each row.
Pressing Enter on a Subject cell, or completed Plate or Visit cell, moves down to the next cell in the column, as does Down arrow.
Shift-Enter on a Subject cell, or completed Plate or Visit cell, moves up to the next cell in the column, as does Up arrow.
If you know the numeric value it can be typed into an empty cell or you can over-type to change a completed cell. Plate and visit labels are displayed after the numeric value is entered in these cells.
If you don't know the numeric value for plate or visit a selection dialog showing the legal values and corresponding labels can be launched using right-click, Control-S or by hitting Enter when the cell is empty.
Within the selection dialogs use the Up and Down arrow keys to find the desired value and then hit Enter to select it and close the dialog.
Plate must be entered before Visit; only visit numbers that are legal for the specified plate are displayed in the visit selection dialog.
To enter the same value in a range of cells in any column, first select the cells (click the first cell then shift-click the last cell) and then enter the value by typing or using the selection dialog.
To copy and paste the values from one range of cells to another, first select the cells as described above, then use Control-C (or right-click-Copy) to copy the values, then click the first cell in the destination range; finally, use Control-V (or right-click-Paste) to paste the values.
While working within a selected range of cells, the Delete (Backspace) key removes the current value from all of the selected cells.
When all keys have been completed with valid values, the space bar can be used to toggle the import selection check box on and off.
A subject package is a user-specified selection of data records, CRF images, metadata and change history assembled into a PDF. The PDF is viewable with a PDF viewer application, such as Acrobat Reader.
DFexplore includes a feature to create one or more subject packages, for a specific subject ID, set of IDs, or entire sites.
To start the creation of subject packages, select > . The Create Subject Packages dialog is displayed. [4]
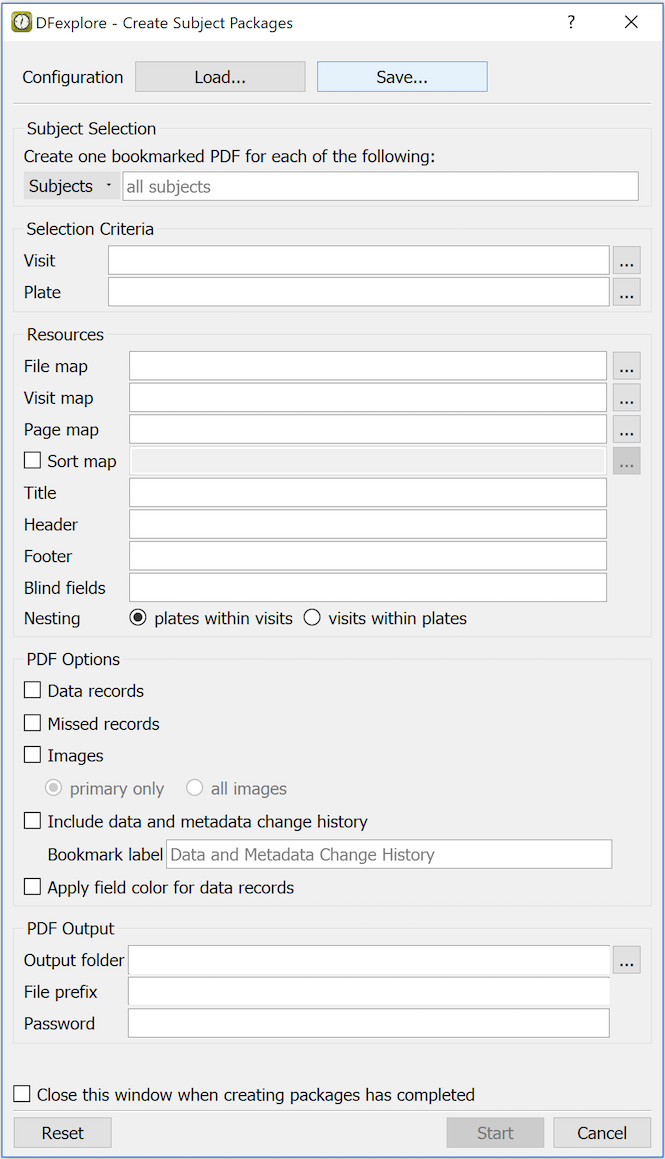
The dialog has several configuration sections:
Subject Selection. Which subjects, or sites, are included? For each included subject, a unique PDF is created.
Selection Criteria. Are only certain visits or plates to be included? By default, all visits and plates appearing in the database for the selected subjects are included. This can be useful for example to create packages containing only the enrollment visit or adverse event CRFs.
Resources. The appearance of the contents in each package is impacted by the settings in several resource files. In most cases, the already defined study resources yield the desired results. A custom title, page header and page footer, and details for fields to be blinded in the output are also specified here. Details for the syntax of the Blind fields setting can be found in Programmer Guide, DFpdf.
PDF Options. In combination with the subject selection criteria, these options determine which data from each subject binder to include in the output. Typical settings include Data records and Images. Metadata (including change history) and secondary images can also be included. Note that including change history and secondary images can result in PDF documents that are very large.
PDF Output. One PDF document is created for each included subject. In this section specify the folder location where each of the PDFs should be created and what prefix should be used for each generated document. The subject ID is appended to the file prefix. The complete document name for each PDF is the concatenation of the values for Output folder and File prefix, which is then followed by the current subject ID. A fixed extension of
.pdfis added to complete the document name.
Complete all of the relevant settings in the dialog. Depending upon the number of subjects or sites selected, and the volume of data, the package creation step can be quite lengthy. Review that all of the settings are correct and as intended. Click . Review the settings summary in the confirmation dialog. Click .
While the package creation process is running, a progress bar is displayed. At completion, a summary dialog is displayed. Review the referenced log file (if more detail is needed) by clicking . Click to dismiss the dialog.
The resulting PDFs are available in the folder previously specified for Output folder. Each PDF is viewable with a PDF viewer application, such as Acrobat Reader. If a Password is specified, resulting PDFs are encrypted and stored in binary format. The recipient needs the password to open each PDF. The summary log file is also in the same folder. It if is not needed, it can be deleted.
This section describes the options available from the application menubar. The specific menus displayed, and the availability of options under each menu, varies depending on user permissions and whether an action is allowed at any given time.
The menu is similar for all views (data, list, queries and reasons) and contains the following items:
-
- users with DFexplore Developer permission can use this option to:
reload lookup tables,
reload edit checks, and
trace edit check execution
These functions make it possible to modify edit check code, republish it and then reload the edit checks to test the modifications and trace edit check execution as you enter and exit records and fields. In order to avoid disrupting production edit checks in use by other users, we recommend using Link Development-Production studies for testing the changes to edit checks before publishing them.
-
- functions the same as DFsend. A CRF with a legible barcode is sent to the image queue of its study. CRFs with illegible barcodes are sent to the Image Router.
-
- create a DRF listing the keys of all records in the current task set. This allows reloading of this same set some time later using > .
-
- create a PDF file containing data and/or images from the current subject binder or task set. Use this option to: print blank CRFs, print documents and data records side by side, or include data records with the same field color coding used in DFexplore.
If a watermark exists for your login role, it appears in the PDF file created by this menu item. Blank CRFs are not watermarked.
-
- create a PDF file containing data and/or images from the current subject binder or task set. This option includes many of the same options as the command line program DFpdf and includes a navigation sidebar indexed by subject ID, visit and plate. Use this option to produce a PDF containing any combination of CRF images and data records with the same color coding used in DFexplore, to blind specified data fields (e.g. for endpoint adjudication committees), and to password protect the PDF file.
Enter field blinding specifications as follows:
plate#s:field#s;plate#s:field#s, and use '*' for all plates and/or all fields. For example:*:8(blind field 8 on all plates),1-5:8;9:22-25,33(blind field 8 on plates 1-5 and fields 22-25 and 33 on plate 9.If a watermark exists for your login role, it appears in the PDF file created by this action.
-
- create a PDF file containing the data record keys, set creation method, set instructions, user name and date for the current task set.
-
- print blank CRF books with subject ID and visit numbers pre-printed, or pages (containing data and/or images) from the current subject binder or task set.
If a watermark exists for your login role, it appears in the printed CRFs created by this action.
-
- print the data record keys, set creation method, set instructions, user name and date for the current task set.
-
- create bookmarked PDF documents containing EDC data records, fax or other image records and audit records for study subjects; one file per subject.
-
- create ODM compliant XML files containing study data.
-
- set user preferences. Changes are applied immediately and persist across login sessions.
-
- change your contact information and/or login password.
-
- display the login/study selection dialog so that an additional login session can be started. The current study login session is not impacted.
This can be useful if you want to compare data in 2 different studies, compare information presented in different views (e.g. list and data views) within the same study, or compare behavior for 2 login sessions with different study roles during study setup.
-
- close the connection to the current study and return to the study selection window, where a different study or different server may be selected.
When a field in the data entry window has the focus the following menu items are available:
-
- undo the last edit operation performed.
-
- redo the last edit operation performed.
-
- copy the contents of the current field to the system clipboard, then clear the field.
-
- copy the contents of the current field to the system clipboard.
-
- copy data from the system clipboard to the current field at the current cursor location.
-
- remove all data from the current field.
-
- select all data in the current field.
The menu is used to select subjects and data records for review. Selected subjects and records are tagged in the record list panel with the letter t (for task).
-
- cancel the current selection criteria and return to the default display showing all subject binders and records.
-
- select data records using a predefined task.
-
- select data records by: site, subject, visit, plate, level, status, etc. as well as by metadata (queries and reasons). This option requires permission for Data - with Select.
-
- select data records using a previously defined data retrieval file.
-
- define individual tasks or tasks for other users.
-
- export previously defined data tasks to a local file.
-
- import data tasks from a local file.
-
- DFexplore supports 4 working modes and allows records to be moved to specified workflow levels. The supported modes include:
-
- users review subject data but can not make any changes.
-
- changes can be made (as permitted by user permissions) but the workflow level of all data and metadata remains unchanged.
-
- the workflow level is changed to the specified sign off level, but only for those data and metadata records that are modified.
-
- the workflow level of data and metadata records is changed to the specified save level when you select one of the Save buttons, regardless of whether or not any changes were made to data or metadata.
-
-
- change the workflow level of a set of records.
-
- e-sign all records for the current subject or a set of selected records eligible for signing and move to a specified workflow level.
The menu determines which subjects and data records are listed in the study binder window. The menu items act as filters. The following choices are available:
-
- show all data records, independent of whether they are included in the current task set.
-
- show only data records that have been assembled in a predefined or ad hoc task using the Select menu options.
-
- show all subject binders.
-
- show only empty subject binders (for which no data has been entered).
-
- show only subject binders that contain data.
-
- show only subject binders with complete data for all visits completed to date.
-
- show only subject binders containing pages marked Incomplete or Pending.
The menu includes the following options:
-
- add a new subject binder to the current site for a specified subject ID. Only subject IDs which have been predefined as belonging to the current site, are accepted.
-
- open all visits in the current subject binder.
-
- close all visits in the current subject binder.
-
- import PDF documents containing CRF pages directly from the local computer.
When a visit is selected in a subject binder, the following options are available:
-
- add visits which do not already appear in the subject binder.
-
- if an entire subject visit is unavailable (e.g. because the subject missed the visit) this option can be used to mark it missed.
If a missed visit report page has not been created for the study a default dialog appears. In this dialog, choose a reason from the choice list. Additional text can be entered to explain why the visit has not been completed. All required pages in the visit are then marked 'Missed', data entry is blocked on all of these pages, and the reason is displayed in the reason window whenever one of these pages is selected.
If an overdue visit query exists it is removed when the visit is marked missed.
-
- undo the previous option if the default dialog was used. If a special missed visit report page has been completed it remains in the study database, just like any other study record, unless it is deleted.
The menu provides the following options for the current page:
-
- offer the same 3 options provided by the save buttons at the bottom of the window: Final, Incomplete and Pending.
-
- undo all unsaved changes that have been made to the current page.
-
- display all images (primary plus all secondaries) and allow user to: select which image to call primary, delete secondary images, and correct keys on secondary images.
-
- correct any errors in the key fields that might have occurred when a page was saved, including corrections to the study number, subject ID, visit number and plate number.
-
- delete a data record. All of the data, queries, reasons and images associated with the record are deleted from the database. Deleting a record is a drastic, and unusual measure. Confirmation is required, and a reason must be entered to explain why the record is being deleted. Once a reason for deletion is applied, you are required to enter your password to confirm and complete the delete process. The delete action, the reason and your user name appear in the audit trail report created by DF_ATmods. Permission to use this option is typically tightly controlled.
-
- if a page is unavailable, and may never be available, this option can be used to mark it missed. Choose one of the standard reasons, or 'other'; additional details explaining why the page was missed can be entered in this dialog.
A page that is marked missed cannot contain data. Thus pages that have already been saved cannot be marked missed unless the data record is first deleted. Also if data has been entered into data fields on a new record before it is marked missed, the data fields are cleared when marking it 'Missed' is confirmed. After a page is marked missed all data fields become inactive to prevent data entry.
If a missing page query exists it is removed when the page is marked missed.
Study managers may add a query to the subject ID of missed records to request additional information from the clinical site.
-
- this undoes the previous option, removes any data query that might have been added to the subject ID field, and enables data entry.
-
- display the date and time the page arrived (if one exists), and the source of the page.
-
- display key properties of all fields defined on the current page, including: name, description, style, need, type, format and legal values.
-
- lists each field with a problem on the current page including: required fields that are blank, illegal values, outstanding queries and rejected reasons.
-
report all changes made to data fields on the current page. For moderate to large databases, this action can take a considerable amount of time to run.
The output is a tabular listing. The listing can be filtered to include/exclude rows showing changes made to data, queries or reasons. The columns included in the listing can be adjusted by clicking and including/excluding columns. The output can be saved to Excel.
Further options for viewing the history of changes are available via the DF_ATmods report and the
-historyoption of the DFexport command. -
- during Double Data Entry, lists the fields that have not yet been entered, and the fields that have been changed from their previous value.
-
- displays a file selection dialog to select PDF, DICOM (dcm, dic, dicom), image (png, jpg, jpeg, bmp), and AV (mp3,wav,avi,mp4) file types, and attach the selected file to the current record as a supporting document. Documents can be reviewed later with the review images dialog. Attached files can each be up to 25MB in size.
The menu provides field-level functions. Access to these functions depends upon the state of the current field and the permissions you have been granted by the study sponsor. The functions include:
-
- assign a predefined missing value code to the current field, or remove the missing value code previously assigned. Missing values may also be accessed using the metadata panel. After applying a missing value code, the keyboard shortcut Control+M can be used to apply the same missing value code to other data fields.
-
- return the current data field to the state it was in when the page was opened; this includes the data value itself as well as the presence/values of any field metadata.
-
- explain the current data value with a new reason. The reason dialog can also be accessed through the metadata panel. If there are outstanding (not yet resolved) queries on the data value, which were previously defined with the auto-resolve attribute enabled, adding a reason to the data value also resolves each such query.
-
- update the reason of the current data value. The reason dialog can also be accessed through the metadata panel.
-
- delete the reason on the current data field (note: permission to use this option is typically tightly controlled).
-
- reply to an unresolved query on the current field. The reply dialog can also be accessed through the metadata panel. Some queries can be resolved by correcting the data field and do not require a direct reply. If the study coordinating site wants a direct reply to the query, the phrase (reply required) appears at the top of the Query metadata window. Can also be performed by clicking
.
-
- add a new query to the current data field. This function is also available via the metadata panel. Can also be performed by clicking
.
-
- modify a query on the current data field. If more than one query is present on the field, use the arrows in the Query window to select the correct query for editing. Can also be performed by clicking
 .
. -
- delete a query from the current data field. If more than one query is present on the field, use the arrows in the Query window to select the correct query for deletion. Can also be performed by clicking
 .
. -
- approve or reject pending reasons and query replies, on the current page.
-
- review all reasons and queries (resolved and unresolved) on the current page.
-
- list all data definition properties of the current data field, including: name, description, style, need, type, format, legal values, edit checks, etc.
-
- report all changes made to the current data field. For moderate to large databases, this action can take a considerable amount of time to run.
The output is a tabular listing. The listing can be filtered to include/exclude rows showing changes made to data, queries or reasons. The columns included in the listing can be adjusted by clicking and including/excluding columns. The output can be saved to Excel.
Further options for viewing the history of changes are available via the DF_ATmods report and the
-historyoption of the DFexport command.
Through the Reports View, it is possible to create new, undocked windows. Those windows remain visible until closed, even if you change to another view. To dock or close all of these windows, use these menu items:
-
- any open and undocked report windows are returned to a docked state.
-
- any open and undocked report windows are closed.
The menu launches the help viewer application and displays information about DFexplore. It also includes additional study information:
-
- display the DFexplore user guide.
-
- display the status of the SSL certificate provided by the server. Use this to confirm the encryption status of communication between DFexplore and the DFdiscover server.
-
- display a summary of the colors used and their meaning.
-
- display the instructions for the current task (if any).
-
- list the role(s) you have been assigned in the current study.
-
- display the study level help.
-
- display the plate level help for the current plate.
-
- display the field level help message for the current field. This may be overridden by the last
dfhelp()message generated during execution of field enter edit checks. -
- display version and copyright information. Confirm that you are running the up-to-date version required by the server. Confirm the security settings of your server connection. On macOS, this menu item appears under > .

[4] There are several other methods for creating PDF documents, including > and > . These are historical options that are being offered for backwards compatibility. Their features have been superseded and they will be removed in a future release.
Table of Contents
The Queries View aids in the review and management of queries. It has features that are specific to queries.
Each query is identified by the subject ID, visit and page on which it occurs. Under the heading Field : Category the data field is identified along with its current value and the category (in brackets). If necessary, this may be followed by a description of the question from the study coordinating site. The last column shows the current status of each query, when status was set and by whom, and the current reply made to the query (if any).
Each query is marked with a symbol that shows its current status: a green filled rectangle for resolved queries, a blue partially filled rectangle for queries that are outstanding, and an orange outline rectangle for pending queries (i.e. where someone has responded to the query but the response has not yet been reviewed by the study coordinating site).
Double-clicking a query closes Query View and opens Data View with the focus on the field to which the query is attached. This makes it easy to locate the field that needs to be corrected or to enter a reply to the query or a reason explaining the data value.
When finished with the data field in Data View and having saved any changes, click at the bottom of the subject binder list.
Query status has one of 3 possible values:
-
Outstanding. the query still needs to be addressed
-
Pending. the query has been addressed and is waiting for someone at the study coordinating site to review it
-
Resolved. the problem has been solved. This may occur automatically, for example when a legal value is entered into a field that has a query with category 'missing' or 'illegal'. Or a query may be resolved by someone at the study coordinating site. Query resolutions are classified in one of 3 ways:
-
resolved corrected - always the desired solution
-
resolved NA - the requested data/information is not and will not be available
-
resolved irrelevant - another value or response has rendered this query irrelevant
-
The available menu actions change when Queries View is selected.
The menu is used to filter the queries to be displayed in the queries table.
The following filters are available:
-
- include only queries on plates that match the defined task
-
- include all queries
-
- include queries that still need to be addressed
-
- include queries that have been resolved
-
- include queries that are awaiting review by the study coordinating site
-
- include queries that have the specified category code
-
- include outstanding queries that request data corrections
-
- include outstanding queries that require a detailed reply
-
- include outstanding queries modified in the past 5, 10, 15, 20, 25 or 30 days
-
- include outstanding queries modified more than 5, 10, 15, 20, 25 or 30 days
-
- display a search dialog for queries with specified properties. This provides the greatest flexibility and specificity for locating queries.
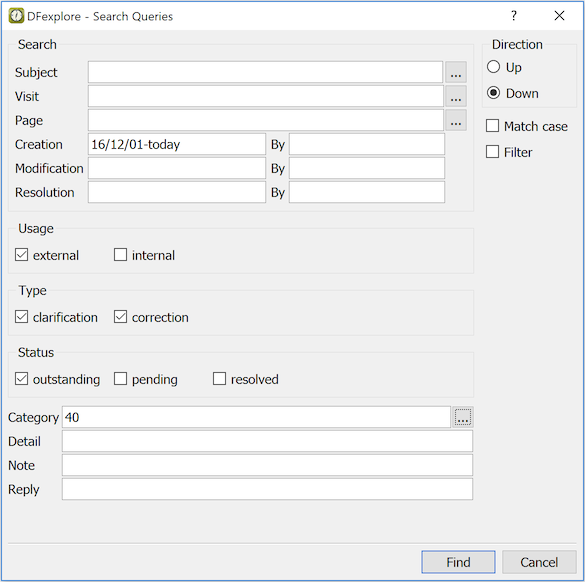
To be selected, a query must match all of criteria and you must have permission to view the query. Criteria left empty are not considered in the search.
To further specify subject selection criteria based on multiple criteria across multiple plates (Selecting Subjects based on Criteria), click .
If Filter is checked, clicking reduces the query list to queries that match the search criteria, and the search dialog closes.
Otherwise search Direction is applied to find the first match starting from the top of the list, or from the currently selected query and changes to .
Searching for a text match in the Detail, Note and Reply fields is case insensitive unless Match case is checked.
This menu has one action, . The menu action is available after a query has been selected in the Queries table. Selecting this option changes to the Data view, opens the relevant subject binder, visit, and page, and places the focus on the field that has the query. This allows you to find, review, and respond to outstanding queries in the context within which each query was created.
A quicker way to jump to the relevant data field is to double-click the query in the Queries table.
To return to the queries table after reviewing a query in Data View, click .
Table of Contents
The Reasons View is used for review of reasons that have been added to explain unusual values, add comments or explain why a data value was changed. Reasons are analogous to comments written in the margins of a paper CRF.
Each reason is identified by the subject ID, visit, and page on which it occurs. Under the heading Field : Reason, the data field is identified, followed by the reason that was entered to explain the current value. The last column shows the current status of each reason, when the status was set, and by whom.
Reason status has one of 3 possible values:
-
Pending. the reason has not yet been reviewed by the study coordinating site
Approved. the reason has been reviewed and accepted by the study coordinating site
Rejected. the reason has been reviewed but has not been accepted by the study coordinating site. For example, some data fields may be essential to a study and only accepted as missing in very rare circumstances. Typically when a reason is rejected the study coordinating site will add a query to explain why the reason is inadequate
The available menu actions change when Reasons View is selected.
The menu is used to select the reasons to be displayed in the reasons table.
The following filters are available:
-
- include only reasons on plates that match the defined task
-
- include all reasons
-
- show reasons that have been approved by the study coordinating site
-
- include reasons that have been rejected by the study coordinating site
-
- include reasons that are awaiting review by the study coordinating site
-
- display a search dialog for reasons containing specified text strings
This menu has only one option, . The menu action is available after a reason has been selected in the Reasons table. Selecting this option changes to the Data view, opens the relevant subject binder, visit, and page, and places the focus on the field that has the reason. This allows you to find and review reasons in the context within which each reason was created.
A quicker way to jump to the relevant data field is to double-click the reason in the Reasons table.
To return to the reasons table after reviewing a reason in Data view, click .
Table of Contents
Image View is used to enter new data records from paper case report forms (CRFs) that have been sent to the DFdiscover study server, or to enter new data records from hardcopy CRF pages you have in hand and do not plan to scan into the system.
When a DFdiscover server receives a scanned CRF page it reads the barcode to identify the study and CRF plate, routes the page to the study, and then uses ICR (intelligent character recognition) to read the data fields and complete a first draft of a new data record. These records are stored outside the study database. They must be reviewed and saved to the study database to become available to users in Data View.
DFdiscover ICR reads check/choice boxes, numbers, dates and visual analog scales, and accuracy depends on how clearly each field has been completed. Any ICR errors must be corrected, all text fields must be manually entered, and comments written in the margins must be reviewed and perhaps entered as reasons or missing value codes.
Use Tab or Return to move forward through the data fields, and Shift+Tab or Shift+Return to move backwards. This will ensure that you traverse all field entry and field exit edit checks designed to assist data entry. When necessary the 2 screens will scroll together to show the same data fields in the data and CRF windows. You can also use Ctrl+T or Ctrl+B to scroll the CRF image screen by itself to the top or bottom respectively to check something that has scrolled by. Alternatively, if you have a large monitor the screen can be split vertically to display a full page on each side (see User Settings).
While entering new records, click to move backward in the list of new records to get an earlier set, or click to move forward in the new record list to get the next available set. Records that have already been entered or that are currently being entered by another user will be skipped. The Next and Previous direction depend on whether you selected to sort by 'oldest to newest' or 'newest to oldest' in the record selection dialog (see below). The meaning of 'Set' also depends on what you selected in this dialog - it could be one or more documents or a specified number of records with specified visit and/or plate numbers.
If you have many CRF pages that need to be entered but not sent into DFdiscover, you can use Image View in EDC Data Entry mode to enter these pages or use Data View to perform the same task. The only difference is that data entry in Data View is performed within one subject binder at a time, while Image View allows you to work independent of subject binders.
New records are typically saved to the study database at workflow level 1 but it is possible to save new records directly to other levels. Image View is typically used only by data entry staff at the study coordinating site; this option is not normally made available to clinical sites.
Image View supports 4 options for building a set of records to be entered. These include: and for entering data from previously submitted (fax, email, DFsend) CRF pages, for entering data from hardcopy CRF pages or other sources held outside of DFdiscover, and which applies automatic record selection rules that have been predefined for a particular user or study role using .
facilitates the easy selection of specific records from the list of pages awaiting data entry, or searching for records with specified plate and/or visit numbers.
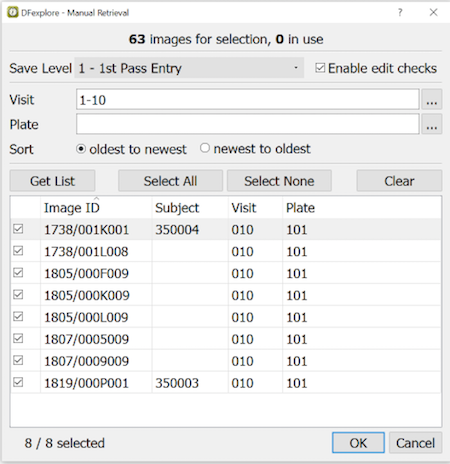
Since visit 1-10 were specified, only these visits were listed when was clicked.
If ICR was able to read the key fields (ID, Visit and Plate) they will appear beside each page name (yyww/ffffppp, where yy=year, ww=week, ffff=fax, ppp=page). Records can be selected individually using a mouse click to select one record and Shift-click to select all records between the last selection and the Shift-click record, or all records can be selected using .
To assemble the selected records click .
allows users to get a specified number of documents, pages or plates at a time, and repeat this process as desired, by clicking . This avoids having to return to the record selection dialog after each set has been entered.
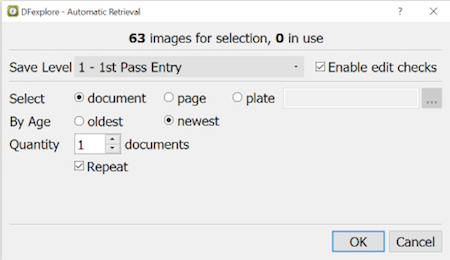
The current status of the new record queue is updated and displayed at the top of Record Retrieval dialog each time it is opened. In this example there are 63 CRF pages awaiting data entry of which 0 are currently locked by other users.
We recommend selecting one document at a time and processing the oldest documents first, but it is possible to select a specified number of pages, to only enter specified CRF plates, or to enter the most recent arrivals first.
is used to build a specified set of blank data entry screens for data entry from sources residing outside of DFdiscover.
Some or all of the keys may be specified. If subject IDs alone are specified, a complete CRF book, as defined in the study visit map (consisting of all required and optional visits and all required, optional and missed visit plates), will be created for each specified subject ID. A maximum of 999 subject IDs and 10,000 data records can be included in each EDC Data Entry set. If subject ID is not specified, you must indicate the number of cases to be created.
If data entry is interrupted, only those records that have been saved to the database will exist in the database; building a set of blank screens does not automatically put blank records into the database.
This example creates data entry records for visit 0 plates 1 and 2 for each of subjects 55034 to 55039, 12 records in total.
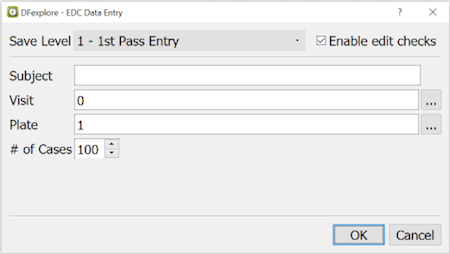
This example creates 100 data entry records for visit 0 plate 1. The subject IDs have not been specified and thus must be entered before each record is saved.
is used to build a specified set of data entry records following a task specification. To define a new task, click at the end of the Task input field. Select from the list and then complete the task definition dialog. This example shows a task created by 'jack' for users with the 'Data Manager' role. Since jack owns the task only he can modify it.
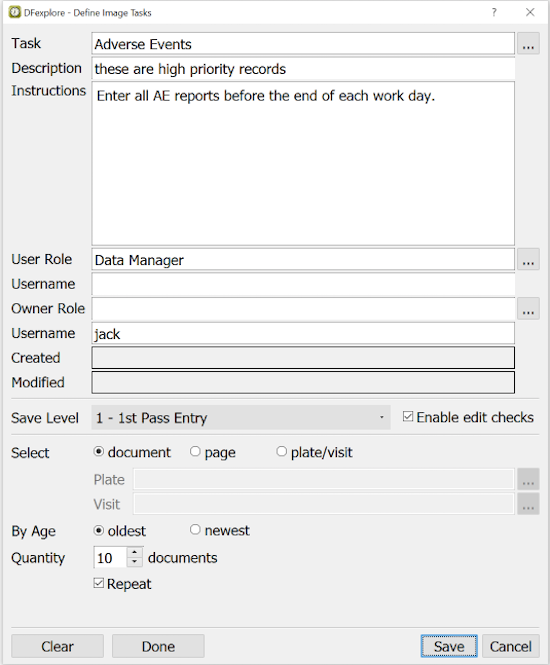
You cannot save entered records in Image View for which you do not have permission. However, it is possible to select an image for which ICR failed to read the keys, and then after entering the keys discover that you cannot save the record. Also if ICR misreads the keys and you have limited permissions, you may be prevented from seeing a page that you should see in the list of received pages. These limitations argue against giving the clinical sites access to Image View, except perhaps for EDC Data Entry only.
Whether using manual or automatic record retrieval, set the Save Level to the workflow level at which new records are to be saved. Typically level 1 is chosen, but it is possible to save new records to any workflow level.
New data entry is always performed in Validate mode, which allows records to be saved even if no changes are made. The mode and workflow levels are shown beside the Save buttons. For example Save v[0->1] indicates that you are in Validate mode, and that data and metadata records will be moved from workflow level 0 to workflow level 1, when you click or . New records saved with Pending status (to indicate that data entry was not completed) are saved to the study database but remain at workflow level 0.
The check box, Enable Edit checks, can be used to enable or disable edit checks during new data entry. Typically edit checks are enabled during new data entry but you may want to delay them to a later stage in your data management workflow process.
Data entry is performed as already described for the Data View. The main difference is that ICR will have already completed many of the data fields and thus the task is to compare the ICR reading with what was written on the CRF page, and to correct any ICR errors and enter any text fields (which are not read by ICR).
If NA or other missing value codes have been written on the CRF, the corresponding missing value code can be selected from the Field menu or using the Missing Value widget in the bottom left corner of the screen. After applying a missing value code in either of these ways, keyboard shortcut Control+M (Command+M on macOS) can be used to apply the same missing value code to other data fields.
If explanations have been printed in the margins, they can be entered using the Reasons widget, also located in the bottom left corner of the screen.
If you need to know when a CRF page arrived or the sender identification, select > .
In this example the current CRF page is page 1 of a 1 page document. The Sender may be the identification of the sending fax machine, or the username that submitted the document. The Image is a unique identifier created by DFdiscover for each CRF page.
It is not unusual for a CRF page to be corrected and resubmitted. For each new record, DFdiscover checks to see if the keys (ID, Plate and Visit) match an existing database record. If a match is found you will be asked if you want to load the existing data record (including reasons and queries) into the data entry window. This will allow you to compare the newly arrived CRF page with the current version of this data record in the study database. DFdiscover will not allow you to enter a matching record into the database without first loading the existing data record. When you save a matching record you will be updating the existing data record with any changes you make; and the new CRF image will become the primary image associated with the data record.
The old image is not deleted, and can be reviewed at any time by selecting > or by clicking the image count button in the bottom-right corner of the DFexplore window. The Review Images dialog shows the date and time each image arrived and allows you to change which image is classified as the primary copy, correct keys if an image has become attached to the wrong data record, or delete images that are no longer needed.
If you process more than one image for the same data record in the same session the last image saved will become the primary image and the previous ones will become secondary. The split screen in fax view shows only the current data record + primary image. Thus returning to a secondary image in the fax view record list will display the image but not the data record. This helps to ensure that users realize they are looking at a secondary image that has been superseded by another image in the record list.
After loading the existing data record, if you discover that you have made a mistake, select > to undo all changes to the current record.
The new High Definition (HD) Images Setting, together with the grayscale and color image handling, is a significant new feature in DFdiscover, which helps modernize DFdiscover by displaying higher quality images.
The default setting is to display standard definition (SD) images (100 dpi) in order to reduce loading time and save cost. The central data management office can enable HD images (300 dpi) to be received for a study via DFadmin. Individual users can determine whether they wish to view the HD images in DFexplore. In other words, in DFdiscover 2016.0.0, users can receive and display HD images if enabled at the study level by the central office. However, if HD images are not enabled centrally or the documents are not imaged at high definition locally (e.g. if they are scanned at 100 dpi and not 300 dpi), they will not be available in DFdiscover to users.
To enable the HD setting in DFexplore, click the button at the the lower-right corner of the the screen in Image View:
, which will change to:
If there is an HD version of the image available, the screen will refresh with the HD image. If HD is not enabled at the study level or an HD image was not transmitted, the SD/HD toggle will change to:
If there is no HD version of the image available, the HD setting will be enabled but the SD image will be displayed.
Like other screen settings such as previous screen location and size, the HD setting is stored locally in user's device-specific settings. This allows you to easily work over a slower laptop connection with HD mode disabled but enable HD mode on another device, an office computer perhaps, which has a fast internet connection.
Also, users are able to export HD images using DFpdfpkg -hd The default behavior for DFpdfpkg is to export SD images only.
![[Important]](../../imagedata/important.png) | Important |
|---|---|
|
High Definition (HD) is only applied to documents which arrive via email attachments, DFsend, or > , and is not applied to faxed documents. |
Each new page has 4 keys which together uniquely identify it: the DFdiscover study number, plate number, visit number and subject ID. The study and plate numbers are always in the barcode, the visit number can appear either in the barcode or as the first data field on the page, and the subject ID always appears as the first data field following the visit number. It is critical that these keys are correct, and they should be carefully checked before a new record is saved to the study database.
If ICR has misread a subject ID or visit number data field, they can be corrected by modifying the data field. However, to correct the keys as they appear in the barcode, you must select > and use the Change Barcode dialog.
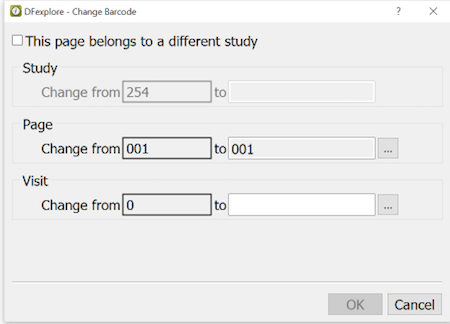
When the Plate and/or Visit number are changed the correction will appear immediately in the new record list, but if the study number is changed the page is sent to the Image Router and will be removed from the new record list of the current study.
While entering new records you can open the current subject binder to review and/or modify other records, using at the bottom of the record list. Before switching to Data View you will be asked if you want to save or discard any changes you have made to the current Image View record.
The subject binder opens to the current Image View record in Data View. This record will be tagged with the letter 't' in the record list to identify it as the current Image View task record. This record cannot be modified while in Data View, and will display: View only: record in use by Fax view in the message window at the bottom of the screen. The switch button, now labeled , can be used to return to the current Image View record and continue with data entry when you are finished reviewing other records in Data View.
Each set of CRF pages retrieved using the 'Automatic' or 'Manual' method is locked by the user who selects them. This is a lock on the image ID, not on the keys, which may at this point be blank or incorrect. These image locks prevent other users from trying to enter the same new pages in Image View. In large studies, with hundreds of pages arriving each day and several users working together to perform new data entry, it is best to minimize the number of pages that each person retrieves at a time. We recommend getting 1 document at a time.
When entering these records a record level database lock is requested for the key fields (ID, visit, plate) as soon as you move into a non-key field. You will not be able to change data or metadata, or save the record, if someone has the subject binder locked in Data View, or if someone is currently entering another record with the same 3 keys in Image View. However, it is possible for multiple users, all working in Image View, to simultaneously enter new data records with different visit and/or plate numbers for the same subject ID.
The only difference between EDC Data Entry and entering a set of records from submitted CRFs is that EDC Data Entry records do not have images and thus do not have image locks.
While working in Image View it is possible to switch to Data View to review and/or modify other records for the same subject ID. When you select Switch to Data View the record level database lock acquired on the key fields in Image View is released, a Data View subject level lock is immediately requested, and the subject binder is then opened to the same page that was being entered in Image View. If the subject ID lock is obtained, enter Data View in Edit mode with the lowest write level; which means that existing records which are modified and saved will remain at their current workflow level, and any new data or metadata data will be saved at the lowest write level.
If the subject ID lock cannot be obtained, Data View can still be accessed in View Only. However, because the record level database lock was released it is possible that upon returning to Image View further data entry will be prevented due to another user now having the database lock on that record.
If the subject ID lock is obtained on switching to Data View, any record in the subject binder can be modified (provided you have modify permission) except for the originating Image View record, which will be displayed in View Only mode. This record must be entered in Image View. You can easily return to it by selecting Switch to Image View that takes you back to this record in the Image View record list.
When a new record is saved in Image View and you move to another record, the database lock is released and the record becomes available to other users. All saved data records remain in the Image View list until they are released or the next set of new records is retrieved. This facilitates returning to a previously entered record to review or modify it. But remember that it is possible to discover that another user has modified or even deleted the record since you last saved it.
This section describes the options available under the menu labels Select and Plate in the application menubar. Only those options that are unique to Image View are included. All other menus and options are the same as already described for Data View.
The menu is used to select pages from the new record queue for data entry. The options include:
-
- as described above this dialog is used to specify how records are assembled for data entry.
-
- use this option to display the list of records awaiting data entry and manually select those you want to enter next.
-
- use this option to build a set of blank records for data entry from hardcopy CRF pages held outside of DFdiscover.
-
- this option allows users to select a predefined new data entry task.
-
- use this option to specify a task for new data entry, including record selection rules, grant users/roles permission to use the task, user instructions, etc.
-
- export predefined image tasks to a local plain text file.
-
- import image tasks from a local plain text file.
-
- this option applies the current record retrieval specifications to assemble the next set of records for new data entry.
-
- this option allows users to return to the previous set of records, but only records still remaining in the new queue will be displayed; any already entered or now in use by other users cannot be accessed.
The menu includes the following options:
-
- this menu item has pull rights for 'Final', 'Incomplete' and 'Pending' which are equivalent to saving changes using the buttons at the bottom of the screen.
-
- undoes all changes to the data, queries and reasons on the current page.
-
- this option is used to review all of the images attached to the current data record, and is only available if the current record has more than one image.
-
- as described above this dialog is used to make corrections to the values of barcoded key fields.
-
- this option deletes the current image from the new fax queue. If the image and its corresponding data record have been entered and saved to the database, returning to the image entry in the new record lists and then deleting the page will prompt the user for both a reason for the deletion and their password.
-
- this option shows the arrival date and time, and fax sender ID of the current CRF page
-
- lists each field with a problem on the current page including: required fields that are blank, illegal values, outstanding queries and rejected reasons
-
- report all changes made to data fields on the current page. For moderate to large databases, this action can take a considerable amount of time to run.
Table of Contents
- 9.1. Introduction
- 9.2. User Preferences
- 9.3. Navigation
- 9.4. Working on a Task
- 9.5. Selecting Data Fields
- 9.6. Searching Data Records
- 9.7. Functions
- 9.8. Saving Defined Views
- 9.9. Exporting Data Records
- 9.10. Exporting a Data Retrieval File
- 9.11. Exporting SAS Data Sets
- 9.12. Importing Data Records
- 9.13. Metadata - Queries, Reasons, Query Reports and Missed Records
- 9.14. List View Menus
List View is a read-only, spreadsheet-like presentation of study data. List View provides functionality to export data in various formats including Excel. List View also provides two ways of looking at your data - by Plates & Metadata or by Modules. List View is the only view that presents data in a module-based view.
As in all other views, what you see and what you can do depends on your user role and permissions for the current study.
Plates & Metadata. In Data View only one data record is displayed at a time. In List View all data records for a selected plate can be displayed at once. Each row is a data record and each column is a data field. This view is useful for comparing data records, searching for particular values, or scanning for data problems. Outlier values can be identified by sorting the spreadsheet on any column - click the field name at the top of a column to sort.
Modules. In Module List View, all data associated with a module is displayed in a single spreadsheet view. Key information is provided in the first six columns followed by three module reference fields, then the user-defined data fields within the module. If there are fields that are not referenced on a particular plate, the unreferenced field cells are shown in grey. Modules that have not been used on any plate are ignored.
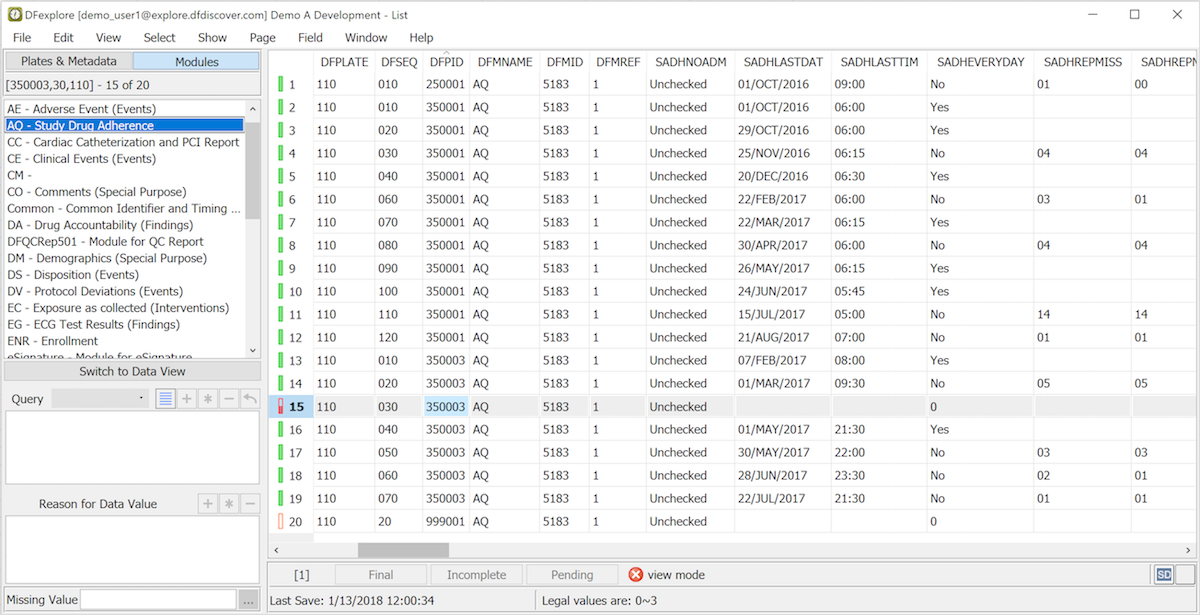
As in Data View, the cells in the spreadsheet can be color-coded to identify: illegal values (red), rejected reasons and outstanding queries (blue), pending reasons and query replies (orange) and approved reasons and query replies (green). Queries, reason and missing value code are displayed in the metadata panels when a cell is selected that has these attributes, and any images associated with a data record can be reviewed when a record with images is selected.
List View does not support data editing. Double-clicking any cell in the table switches to that data field in Data View where edits can be made (and saved). Clicking in Data View takes you back to the original cell in List View. Any changes that are made to the data record, or to its queries and reasons, while in Data View are displayed when you return to that record in List View.
All data records are retrieved from the DFdiscover server when you select a new page in List View, so the spreadsheet is up-to-date each time you select a new page. Also, DFexplore retrieves the current version of each data record when you select it in the spreadsheet, again the record is up-to-date at that instant. However, changes made since the records were retrieved, arising from other users or batch edit checks, are not automatically displayed; some or all rows in the table may become out of date while you are viewing them. As needed, update all records in List View at any time using > .
The List View section of the Preferences dialog, available from > can be used to customize the appearance of List View. Preferences can be used to enable/disable field color-coding and text expansion, determine whether field codes or code labels are displayed, select column labels (field Name, field Alias and prepend with field number), and select the display format for date fields. All selections made in the preferences dialog are study specific and are retained across DFexplore sessions.
To display the data records stored in the study database for a particular CRF page or module, select it from the list in the left panel. Within the data table you can select any cell with a mouse click, use the left/right keys to move across the fields in a data record, and use the up/down keys to move across data records.
The default record sort order is ascending by subject ID and within subject ascending by visit number. The rows of the data table can be sorted on any column by clicking the column label. Each click toggles the sort order between ascending and descending. Use shift-click to sort on a second column, in the current sort order within the currently sorted column.
The keys (subject ID, visit, page) of the current record and the number of data records in the table are always visible in the upper-left corner. The workflow level at which the current record was last saved appears along with the date and time at the bottom. If a Help message has been defined for the current data field it is shown in the help message window, also at the bottom.
If a set of task records was assembled in Data View it remains in effect on switching to List View; only those CRF pages or modules and data records that met the task criteria are displayed. To see all CRF plates in the page list and all data records in the data table select > and > respectively. To see all modules and all data records, select > .
This does not cancel the task set.
Task records can still be identified by the T icon
that appears on each task record in the data table.
To cancel a task and see all data records choose > in List View or Data View.
To select a subset of the data fields, or to include metadata fields, on the current plate or module, select > . The field selection dialog has 3 main sections:
Display Fields. The fields that have been selected for display in List View and/or for export.
Data Fields. Fields from the current plate or module.
Metadata Fields. Metadata from the set of fields, module, plate, page, visit, image, site and study properties.
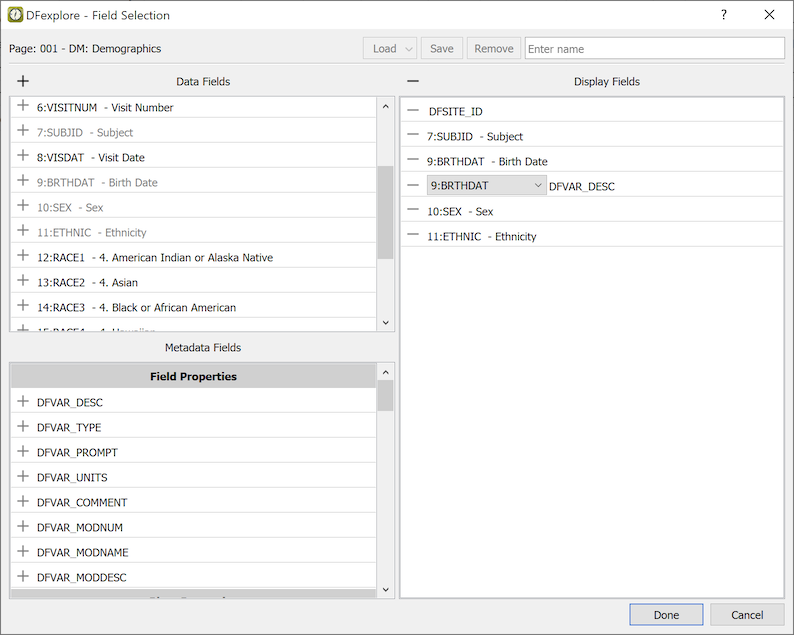
Fields can be selected for inclusion by clicking the plus icon
(  )
beside each field or by using drag and drop to add
them to the Display Fields list.
Click the plus icon at the top of the Data Fields list
to select all fields of the selected plate or module,
in their default order.
Fields can be reordered using drag and drop within the Display Fields list.
)
beside each field or by using drag and drop to add
them to the Display Fields list.
Click the plus icon at the top of the Data Fields list
to select all fields of the selected plate or module,
in their default order.
Fields can be reordered using drag and drop within the Display Fields list.
Once added, individual fields can be removed from the Display Fields
list by clicking the minus icon
(  )
beside each field.
All fields can be removed from the Display Fields list by clicking
the minus icon at the top of the Display Fields list.
)
beside each field.
All fields can be removed from the Display Fields list by clicking
the minus icon at the top of the Display Fields list.
In addition to plate or module List view data, study metadata can be included. Metadata available for the selected plate or module is displayed in the Metadata Fields list. Metadata fields are grouped into categories: Field Properties, Module Properties, Plate Properties, Page Properties, Visit Properties, Image Properties, Site Properties, and Study Properties.
Metadata fields can be selected using the plus sign beside each field or using drag and drop to add them to the Display Fields list. Once added, metadata fields can be removed from the Display Fields list using the minus icon beside each field. Fields can be reordered using drag and drop within the Display Fields list.
Several metadata keywords, DFVAR_DESC through DFVAR_COMMENT, as well as any user-defined properties at the field level, or at the module level when a plate is selected, are properties of each data field. Use the field drop-down list to further indicate for which field the property is requested. In the example, metadata DFVAR_DESC (the field description) is selected for the field BRTHDAT.
User-defined properties at the study, plate, module, and variable level are included with other study metadata where values have been defined for the selected plate or module. Futher details on user-defined properties can be found in Study Setup User Guide, User-defined Properties. The complete list of metadata fields and their meaning can be found in Programmer Guide, Including Metadata in Output.
The Search dialog, available from , can be used to find records within the current plate or module that meet specified criteria. If the Filter option is selected the record list is reduced to those records that meet the search criteria when selecting at the bottom of the dialog, otherwise this button is replaced by a button, and the focus simply traverses those fields that meet the search criteria each time the button is pressed.
Clicking next to the Subject ID field opens another dialog for Selecting Subjects based on Criteria, which implements subject selection based on multiple criteria across multiple plates.
The Search dialog can also be used to add data records from the current plate or module into a Task set. After entering the record selection criteria, click to display a task confirmation dialog (for Mode and Edit checks options) after which the selected records are flagged with the task icon to show that they belong to a new task set. becomes active and can be used, after entering a new set of record selection criteria, to add more records to the current task set. This can be repeated as necessary to build a task set.
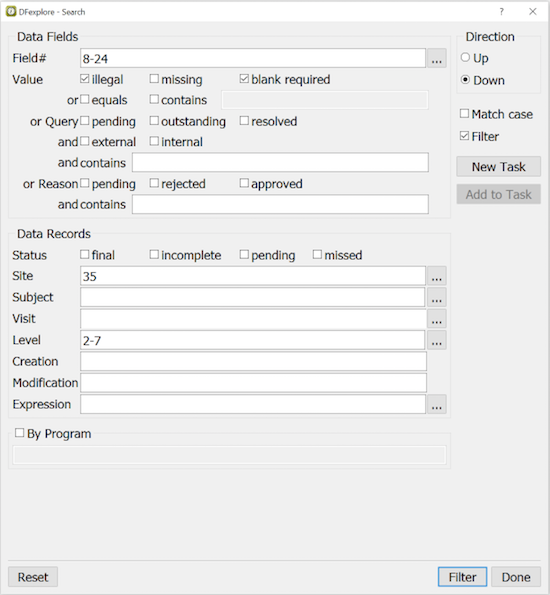
In this example, the current record list is filtered to show only those records for which: fields 8-24 are illegal or blank but required, site is 35 and workflow level is 2-7.
After specifying the search criteria, click to start the search. A dialog appears showing the number of records that meet the search criteria and asking for confirmation before filtering the record list to display only these records.
To be selected records must meet one or more of the criteria specified in the Data Fields section and all of the criteria specified in the Data Records section.
To undo a Filter and display all data records for the current plate or module, select > . To undo a Task and remove the 't' icon from all records select > .
The Search dialog includes an expression editor that can be used to create simple algebraic statements describing the desired data records. Expressions can be entered directly in the text widget or by clicking the Fields, Symbols, Codes and Functions in the appropriate order.
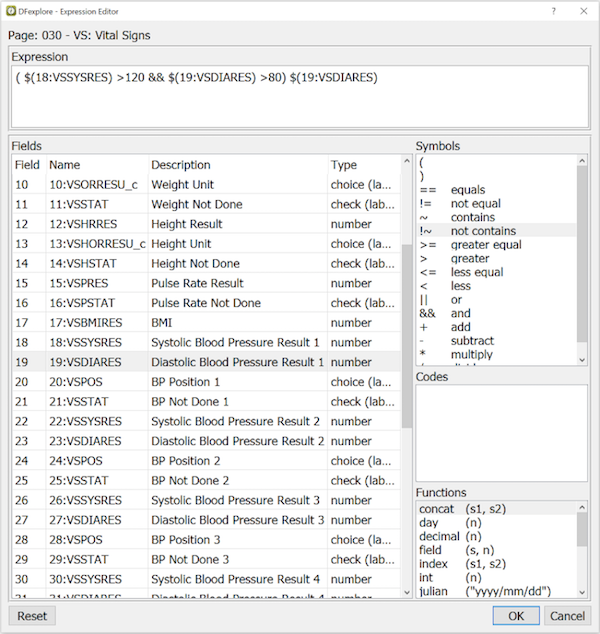
This example selects subjects with a first systolic blood pressure reading above 120 and a first diastolic blood pressure above 80. Click to add this expression to the Search dialog.
| Numeric Codes and Code Labels |
|---|---|
|
Expressions must be created using code labels, when labels are being displayed in List View. If numeric codes are being displayed, expressions must test for codes, not labels. |
Several functions are available for use in constructing expressions.
concat(s1,s2) | Test the concatenation of 2 strings. e.g. to find records where the concatenation of 2 fields named 'Mtype' and 'Mnum' combined to give the value 'A1234': concat($(Mtype),$(Mnum)) == "A1234"
|
day(n) | Test for a day of the month in a date, e.g. to find records where 'Screen 1 Date' occurred on or after the 15th of any month: day($(S1DATE)) >= 15
|
decimal(n) | Test the decimal component of a number, e.g. to find records where weight is not a whole number: decimal($(WEIGHT)) > 0
|
field(s,n) | Test a specified word in a string, e.g. to find records where the 2nd word in a drug name is "ACID": field($(DRUGNAME),2) == "ACID"
|
index(s1,s2) | Find the character position in string s1 where string s2 first occurs. e.g. in the following statement local variable 'X' is set to 3: number X = index("A56GH9","6GH") ;
|
int(n) | Test the integer value (truncated) of a field. e.g. to find a subject's current age in years at visit date 'VDATE' using the subject's birth date stored in field 'BDATE': number age = int((VDATE-BDATE)/365.25) ;
|
julian("yyyy/mm/dd") | Determine the julian equivalent to a date, e.g. to find records where 'Screen 1 Date' occurred after Nov.15,2017: $(S1DATE) > julian("2017/11/15")
|
length(s) | Test field length, e.g. to find initials shorter than 3 characters length($(PINIT)) < 3
|
month(n) | Test for a month in a date, e.g. to find records created in June of any year: month($(DFCREATE)) == 6
|
substr(s1,n1,n2) | Test a sub-string of a specified field, e.g. to find records where the middle subject initial is "X": substr($(PINIT),2,1) == "X"
|
time("hh:mm:ss") | Convert string representation of a time to a time value, e.g. to find records created after 6pm: time($(DFCREATE)) > time("18:00:00")
|
today() | Test against today's date, e.g. to find records created today: julian($(DFCREATE)) == today()
|
tolower(s) | Convert a string to lowercase, e.g. to find records containing "inuit" in the Race Other field, ignoring case: tolower($(RACEOTH) == "inuit"
|
toupper(s) | Convert a string to uppercase, e.g. to find records containing "INUIT" in the Race Other field, ignoring case: toupper($(RACEOTH) == "INUIT"
|
year(n) | Test for a year in a date, e.g. to find records modified in 2017: year($(DFMODIFY)) == 2017
|
If the expression builder does not have the capabilities you require, searching
can also be performed using a custom program specified in the last option
at the bottom of the Search dialog. Custom programs must be stored in the study ecbin
directory and must generate a data retrieval file as output.
DFdiscover includes 2 standard programs,
and
(described in Section A.5, “Selecting Subjects based on Criteria”),
which can also be used for this purpose.
When searching 'By Program' the Filter option must be enabled. When is clicked the record list is reduced to show only those records identified by the program. If in addition to the 'By Program' option the 'Expression' builder or any of the other options in the 'Data Records' section are used, records are selected only if they meet all of criteria specified by all of these options. If any of the 'Data Fields' options are used the set of records selected is further reduced to include only those records that meet at least one of the field level criteria.
List views consisting of specified data fields, field order and record selection criteria can be defined for use by specified users and/or roles using > to display the Define Views dialog.
The steps include the following:
Click next to the View Name field, click New View and then enter a name and description.
Select the plate or module and data fields, in the desired order. If no fields are specified all fields in plate or module order are used.
Select list view options. These override your Preference settings for List View when the view is selected.
Specify the roles and usernames to identify those who can use the view and those who own and can change it.
Specify the record selection criteria. If none are specified all data records for the plate or module are retrieved when the task is selected.
Click next to the Subject ID field to open another dialog for Selecting Subjects based on Criteria, which implements subject selection based on multiple criteria across multiple plates.
To form a new task set from the imported records, choose one of the Create a new task set containing ... options, and specify the task Mode, Save Level and whether to Enable Edit checks if you switch to Data View to review or modify a data record. If a new task is created, any previous task is canceled when the view is selected.

| Note |
|---|---|
This dialog is available to users who have 'List - create Views' permission and can only be used by one person at a time. |
Once views have been defined, users can select a view using > . This displays a dialog showing the predefined view names and descriptions. The current view, if any, is canceled when a new view is selected.
If no records meet the selection criteria for a selected view, the dialog reports that no records were found, the view is canceled, and the spreadsheet returns to its base state, showing all data fields and data records. The current view can be canceled at any time to return to the base state by selecting > .
Canceling the current view does not cancel the current task set (if any). The spreadsheet returns to the base state showing all data fields and data records but any task records remain flagged. Clearing the current task set is a separate operation which is performed using > .
If you have permission to save data, the records currently displayed in List View can be written to a local file by selecting > .
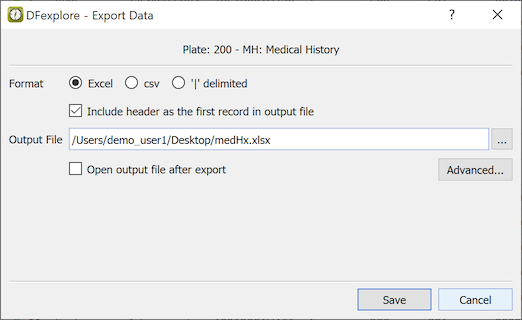
To export the data records displayed in the current List View specify:
a field delimiter, or Excel format,
if field names should be included as column names in the first output row, and
an output file location.
Any data fields that have been hidden using > are not exported. The message Warning: Data will be saved with reduced fields appears at the bottom of the dialog when this is the case.
A Data Retrieval File (DRF) containing the key fields of the records currently displayed in List View can be written to a file on your local disk by selecting > and using the dialog.
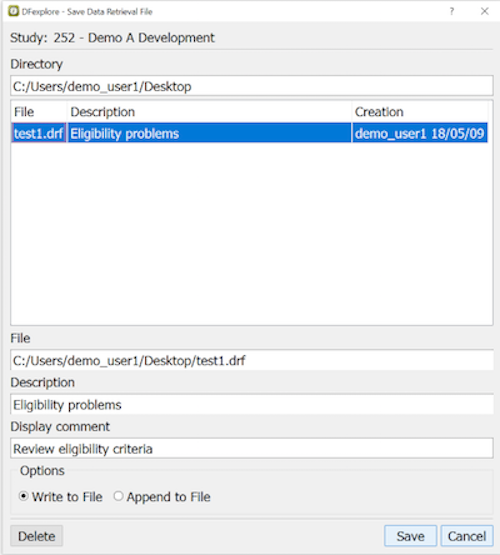
On entering an output directory/folder and pressing Return any existing DRFs in that location are listed.
Output can be written to a new DRF or an existing DRF can be selected and overwritten.
To export the records displayed in List View to a DRF specify:
an output file
a short descriptive label for the DRF
a comment for record level DFexplore help
whether output overwrites or appends to the output file
An existing DRF can be selected and deleted using .
Users with permission can create and export data sets in SAS format to a file location on their local disk by selecting > and using the dialog.
For instructions on creating and running DFsas jobs, refer to Programmer Guide, DFsas: DFdiscover to SAS.

DFexplore works with DFsas job files located in the study dfsas directory on the DFdiscover study server. All existing DFsas job files are listed when the DFsas window is opened and the list is updated if any new jobs are added.
Selecting a job file loads it into the text window where it can be edited and saved back to the study server.
Selecting Run executes DFsas for the current job, which creates SAS job and data files and returns them to the local computer in a .zip file which is stored in the specified RUNDIR.
New DFsas job files can be created by clicking and using the dialog. The new job file appears in the text window and can be edited (as described in Programmer Guide, DFsas: DFdiscover to SAS) to create the desired DFsas job file.
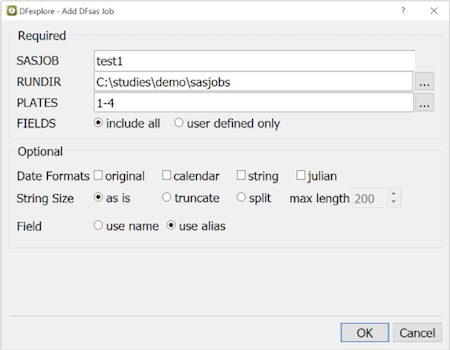
The following can be specified when adding a DFsas job:
SASJOB: new DFsas job file name
RUNDIR: location on the local computer where SAS job and data files are stored.
PLATES and FIELDS: a DFsas job file can include some or all data fields on some or all study plates
Date Formats: optional, see below
String Size: long text can be truncated or split into multiple fields
Field: use name (default) or use alias when there are repeating modules and where field aliases are unique accross the study.
If no plates are specified or 'ALL' is specified, all user defined plates in the range 1-500 plus DFdiscover plates 510 (reasons) and 511 (queries) are included in the DFsas job.
If no date format options are specified, dates are exported using the format and imputation specifications in the study setup. Alternatively, one or more of the following specifications can be selected:
original - turns off imputation, outputs the value exactly as stored in the study database, and creates a date informat for SAS.
calendar - performs imputation as specified in the study setup, converts 2 digit years to 4 digit years, and creates a date informat for SAS.
string - turns off imputation, outputs the value exactly as stored in the study database, and creates a character informat for SAS.
julian - performs imputation as specified in the study setup, converts the date to a julian number, and does not create an informat statement as SAS does not need one for numbers.
Date imputation can be turned off for all dates, regardless of study setup specifications and regardless of which date formats are selected, by specifying 'IMPUTE no' in the global statements.
After saving a DFsas job file it can be executed at any time by selecting Run. A confirmation dialog appears with one option: Force DFsas to include all specified plates. Select this option if you want to include all of the plates specified in the DFsas job file, even if they do not currently contain any data records. If this option is not selected, a SAS data statement is only created for plates with data records.
After confirming that you wish to execute the selected DFsas job, DFdiscover runs DFsas on the study server and returns a .zip file, containing a SAS job file and a data file for each plate, to the specified RUNDIR on your local computer.
Data from labs and other sources can be imported to a DFdiscover plate by selecting > in List View and following the steps listed below. Permission to use this feature must be granted in your study role.
Each imported data record may either create a new data record in the study database or replace an existing data record, having the same keys (ID, visit, plate). If a replacement record is imported all of the data fields on that record are replaced; it is not possible to replace only some fields while leaving others unchanged. If a replacement record is imported with status=7(delete) the database record is deleted.
Import options may be set to add the reason 'Set by DFexplore Import' to any field that is changed, and to add automatic queries for missing and illegal values. All imported data records, plus any reasons and queries generated during import, are logged in the study audit trail by date, time and the username performing the import.
-
Select the Input Data File
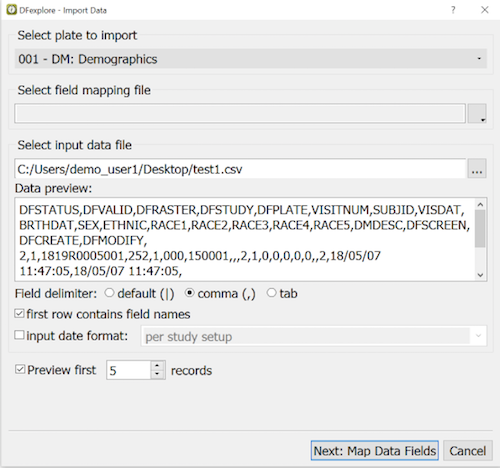
Select the import destination, i.e. the database plate.
If imports from the same source recur, the mapping of input fields to study database fields can be saved to a mapping file and reused.
When the input data file is selected the first 3 records are displayed in a preview window.
The input field delimiter must be one of: '|', comma or tab.
Having field names in the first input row is useful as an aid to field mapping, but it is not necessary.
If the date format used in the input data records differs from the format used in the study plate, choose the input date format to convert dates to the format used in the plate.
If the input file is very large, specifying a small number of records to preview allows you to quickly verify that the mapping and data appear correct before loading all of the input data records.
Click .
-
Map Data Fields
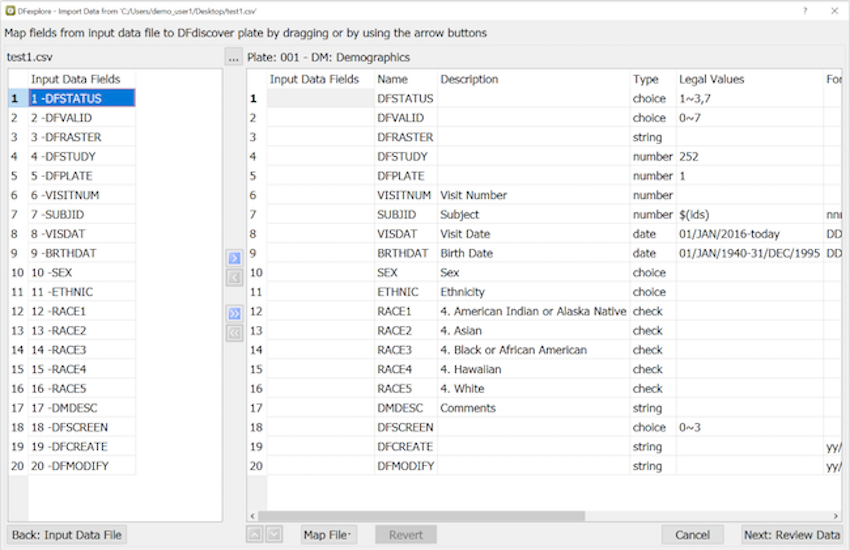
To specify the mapping of input fields to database fields simply drag fields from the left panel to the right panel beside the corresponding Generic Name for the field in the study database, or use the buttons to move the current input field in the left panel to the next available slot after the current input field in the right panel. For example, clicking the right arrow button in the above dialog moves input field '1 -DFSTATUS' to Plate 001 field 1 DFSTATUS.
The double arrows move all fields to the right panel, or back to the left panel, and can be used when all fields in the input records exactly match fields in the destination plate.
Once moved to the right panel, input data fields can be matched with the correct generic name by dragging them with the mouse or by using the up and down arrow buttons.
If the input file contains fields that are not included in the plate they can be omitted. It is not necessary to match and import all fields from the input records.
If the plate contains fields that are not included in the input file a value can be specified under Value if not mapped, otherwise the field is blank in all imported data records. If the word
todayis specified for an un-mapped date field the current server date is inserted when the data records are imported.The only field that is required in the input file is the subject ID. The visit key field can be specified in the Value if not mapped column, as can any other field that you want to set to the same fixed value for all input records.
Database records for a specified plate and visit can be deleted by importing a file that contains only the subject ID, and then specifying the relevant visit number and setting status=7 in the Value if not mapped column. No other fixed values are required.
Plate fields
DFRASTER,DFSTUDYandDFPLATEare set automatically and need not be mapped, but if they are then DFRASTER is treated as a key field which must match an existing record when importing replacement records in 'Replace' mode, and must equal0000/0000000when importing new records in New mode.The time stamps,
DFCREATEandDFMODIFY, cannot be mapped. They are completed by the server when records are imported.During mapping click to review the current mapping of data records, and to return to the mapping dialog.
If other data files with the current mapping are imported in the future, the mapping can be saved to a file using > .
If you forgot to specify a saved mapping file in the previous dialog it can also be selected in the mapping dialog using > .
Click to undo the current mapping and start over, or to abort the data import action.
When mapping is complete, click .
-
Review Input Data Records
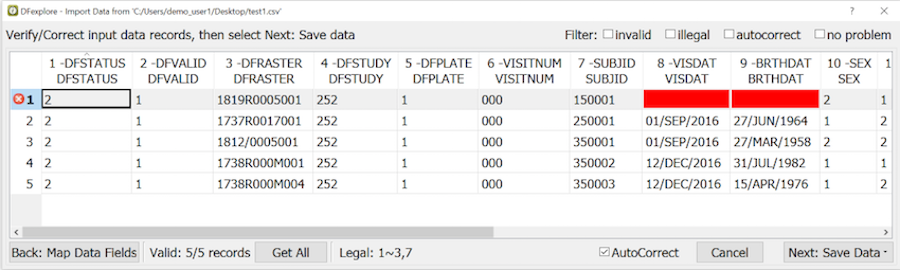
The spreadsheet previews a subset of the data records. Scroll left and right to verify that all fields have been mapped correctly.
Click to load all remaining input records - specifically 5 as illustrated in the example.
Problem fields are identified by color: magenta for invalid values which prevent the record from being imported, yellow for values which are auto corrected on import, and red for illegal values, which are imported as is.
Check AutoCorrect to reveal how the yellow fields will be corrected.
Corrections can also be made by editing the values in the spreadsheet.
The data records can be filtered using the check boxes to display any combination of records with invalid, illegal and autocorrect values, or records with no problems at all.
-
Auto corrections that change the input value include:
Strings longer than the field store length are truncated
Numbers are truncated to the number of decimal places in the field format
Numbers greater than the field store length are imported as blank fields
Undefined codes in choice and check are imported as the field's blank value code
Invalid dates are imported as blank fields
Auto corrections that merely change the format of the input value include:
String and date mapping is applied if specified in the field setup
Leading zeros are added where required by the field format
Leading zeros are removed where not required by the field format
Leading '+' signs are removed from unsigned fields
Input date format is converted to database format if specified in step 1
-
Save Data Records
After the action, click for a file selection dialog. Alternatively, click to present the Import Records to DFdiscover Database dialog.

Choose Mode.
New: all input records have keys (ID,visit,plate) that do not already exist in the study database. Only new records are imported; any replacement records are rejected.
Replace: all input records have keys (ID,visit,plate) that already exist in the study database. Only replacement records are imported; any new records are rejected.
Merge: the input contains both new and replacement records. All are imported.
In the Queries section, it is recommended to resolve missing and illegal value queries if a legal value is imported, otherwise the queries do not correspond to the corrected values and will likely confuse users. None of the other query categories can be logically auto corrected in this way and thus remain unchanged.
Queries can also be created automatically during import to flag missing and illegal values. If these options are selected existing queries are not modified or replaced, new queries are only created for fields that do not already have a query.
Mark Add Reasons to database fields that are changed by imported replacement records to automatically add a standard reason,
Set by DFexplore Import, to database fields that are changed when a replacement record is imported. Reason status can be set toPendingorApproved. To setApprovedstatus, the user must have permission to approve reasons on the records being imported. If this is not the case reasons are created with thePendingstatus. Reasons that are created during import replace any existing reasons on the fields that are changed. The previous reasons are available in the audit trail, for example by selecting > .Mark Task Set to create a task that allows review of the imported data records when import is complete. The task set can contain all imported records or only those with illegal / missing values. This will be useful to review any queries generated during import. The task set must also include settings for Mode, Save Level and Enable Edit checks.
Click .
-
Confirm Import Data
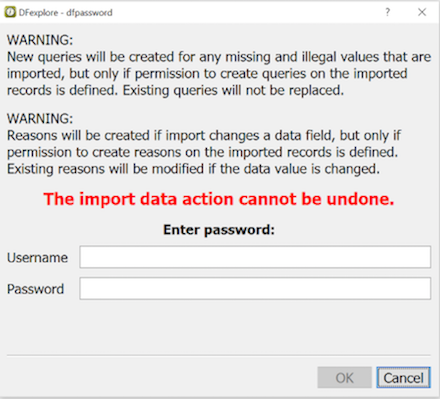
If the options to create queries and reasons were enabled in the previous dialog, two warnings will appear, as a reminder of the implication of those settings.
To start data import, enter user credentials for the study in the Username and Password fields. Click to proceed, or to return to the previous dialog.
-
Review Results
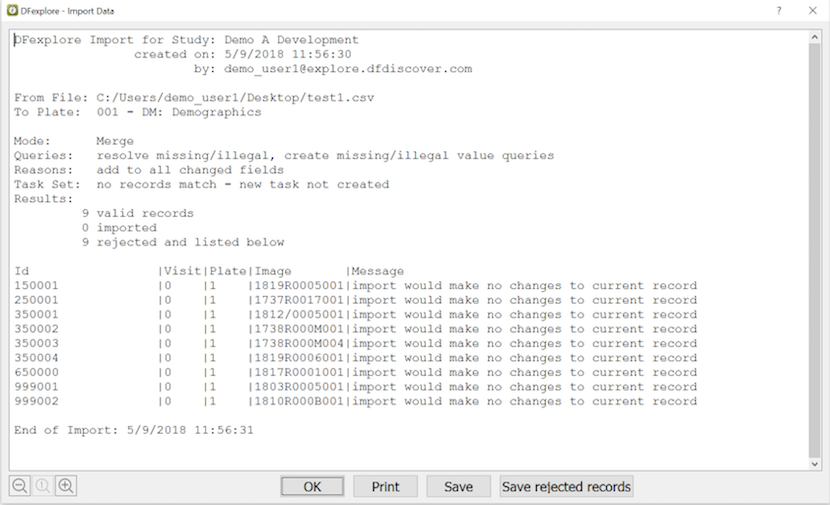
The Import Data dialog appears when the import is complete, with a summary of the import specifications and results.
If any records are rejected, they are displayed in this dialog along with the reason they are rejected. Click to save these records so that the problem(s) can be resolved and the import can be re-attempted.
We recommend keeping a record of all data imports by printing or saving this report. While the audit trail shows any new records and data changes made during import by: date, time and the username who performed the import, it does not distinguish between data entered and saved in Data View and records that were imported in List View.
Input data records may be rejected for the following reasons:
The database record is currently locked by another user
Mode=Replace but the record does not exist in the study database
Mode=Replace/Merge and input keys match a database record but
DFRASTERdiffers from the current database valueMode=Replace/Merge and input keys match a database record but input record is identical to the database record
Mode=New but the record already exists in the study database
Mode=New but
DFRASTERis mapped and is not equal to 0000/0000000User does not have the permissions needed to import the record
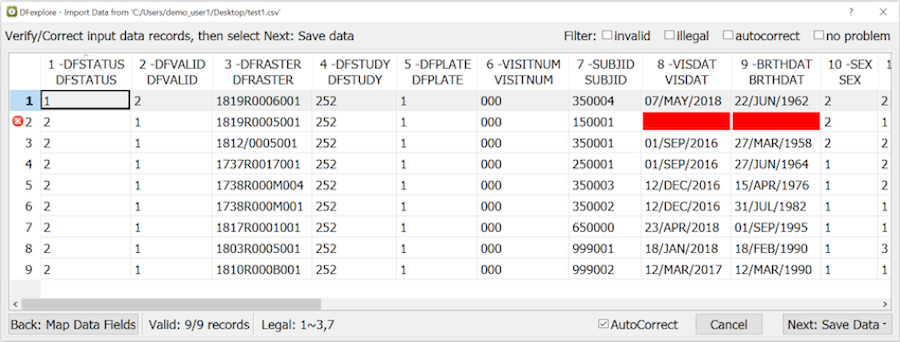
In addition to displaying subject data records List View also displays queries, reasons, returned Query Reports and records that have been classified as 'missed'. Users who have permission to see a data record automatically have permission to see queries and reasons attached to fields on that record. Permissions for Query Reports must be granted explicitly through plate 501, otherwise Query Reports do not appear in List View. Missed data records follow the same permissions as regular data records.
Changes can only be made in Data View. Double-clicking anywhere on a metadata record in List View switches the view to Data View with the focus on the field that was double-clicked. Click in Data View returns you to the field that was double-clicked in List View.
For roles without "Show Hidden Fields" permissions and fields with Hidden/Masked property, no query or reason is displayed in List View.
Queries can be searched using > . This dialog shows the number of queries that meet all of the current search criteria. The next to the Subject ID field opens another dialog for Selecting Subjects based on Criteria which implements subject selection based on multiple criteria across multiple plates. After entering new criteria click to update the counts.
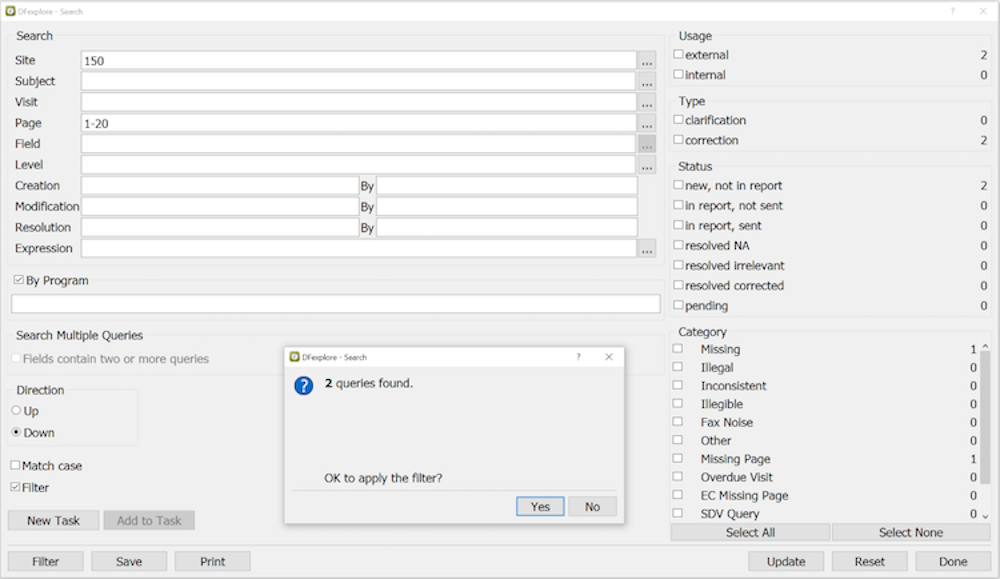
In this example 2 queries match all of the specified criteria.
Click or to output the criteria and counts shown in this dialog.
Click to select these 2 queries and remove all others from the current list view.
Click to put the data records with these queries into a new task set.
After clicking , new criteria can be specified to narrow the search further within the previously filtered set.
Records matching new search criteria can be added to a current task list by clicking .
If you submit Query Reports to the sites they may respond by writing directly on a printed copy of a report and submitting it back to DFdiscover. Returned Query Reports are not subject CRFs and thus are not displayed in a subject binder. They can however be processed in Image View, just like data records, and saved in the study database with key fields: ID equal to the Query Report number (composed of the site number and Query Report creation date), and Sequence equal to the Query Report page number. Any Query Reports that have been saved in this way can be reviewed in List View.
If you have permission to modify returned Query Reports you are able to correct
any errors that might have been made when the key fields were entered.
To make corrections, select > to set mode to anything
except View, and then select
> to
display the Change Keys dialog.
Like subject data records, Query Report pages can be filtered using the Search dialog, and the current set of pages can be printed or saved in a PDF file by selecting these options from the menu.
Workflow tasks can also be performed on Query Reports in List View. For example, new Query Reports are typically saved at level 1 when they arrive in Image View. Someone may then have the task of reviewing them and moving them to level 2 to indicate that they have been reviewed. To perform this task select > to set Mode to Validate and Level to 2. Next selecct > to find the Query Report pages that are currently at level 1. After reviewing each page, save it by selecting or . This moves the page to level 2. Use the search dialog again at any time to find the pages that currently have incomplete status.
This section describes the List view options available under the , , and menus in the application menubar. The options available under the remaining menus have already been described for the Data view.
The menu is similar to all other views (data, queries, and reasons) with the exception of the following items:
-
- Users with permission can create and export data sets in SAS format to a file location on their local disk. Refer to Exporting SAS Data Sets for further information. For instructions on creating and running DFsas jobs, refer to Programmer Guide, DFsas: DFdiscover to SAS.
-
- Users with permission can import data from labs and other sources to a DFdiscover plate with this feature. Refer to Importing Data Records for further information.
-
- Users with permission can export data records. Refer to Exporting Data Records for further information.
The menu is used to select the data records (rows) and data fields (columns) to be displayed in the List view table. The options include:
-
- cancel current task set (if any) and show all data records for the CRF page currently selected in the left panel of the List view dialog. When canceling a task set a new mode and save level can be specified in a pop-up dialog.
-
- select and arrange the data fields page to be displayed from the current page.
-
- specify criteria used to find data records, reduce the rows in the List view table to those meeting the specified criteria, and/or to create a new task set.
-
- select data records (rows) and data fields (columns) using a predefined view.
-
- cancel previous By View selection to display all data records and data fields for the current page.
-
- define views for oneself and/or for other users.
-
- export predefined data views to a local plain text file.
-
- import data views from a local plain text file.
-
- update all data records for the current page from the study server to get new records that may have been added or changes that may have been saved since the view was opened.
The menu is used to select the study page types and individual records to be displayed in the List view table. The options include:
-
- show all page types defined for the study
-
- show only those page types included in the current task set
-
- show all data records for the currently selected page type
-
- show only those data records included in the current task set
Table of Contents
Reports appear as an option under the View menu if you have been granted permission to run one or more of the standard DFdiscover reports or study specific reports. Reports can be updated and viewed within the Reports View and can be printed or saved to an Excel, PDF, HTML, Archive HTML or text file. The Reports View is illustrated below.
Reports are generally categorized as one of 3 types. These 3 types are presented in the reports list. Clicking any type updates the reports list with the reports of that type.
DFdiscover Reports: All of the standard DFdiscover reports for which you have permission are listed. The standard reports are designed to address common trial management needs, like summarizing data management status for individual subjects and clinical sites. The DFdiscover Reports are themselves separated into two groups: legacy reports and standard reports. Legacy reports generate plain text output only. It is not possible to save the output from legacy reports as Excel. Standard reports generate HTML output and can be saved in different formats, including HTML, Archive HTML, PDF, Excel and Text. The HTML and Archive HTML output formats have the same content but the HTML content has references to external resources (like CSS and JS) while Archive HTML is self-contained, without external resources.
Study Reports: Lists the study specific reports, designed by programming staff at the trial coordinating site, to address needs not covered by any of the standard DFdiscover reports.
History: As each report is run it is added to the History list. You can review the output from any recently run report by opening this list and selecting the report. You can re-run reports from within the History list by selecting the report in the list and clicking . Unless changed, a selected report runs with the same options used the first time and then is also added to the end of the History list. If the report History list is saved, the options are also saved.
All DFdiscover reports include documentation that can be accessed by selecting the report name and then clicking . The documentation generally includes a description of any options that may be specified before the report is run and an explanation of the report output.
In > , enabling the user preference
Each report run opens in a new tab allows each report run
(and explain action) to appear in a separate tab.
Tabs appear in the "tab bar" at the top of the main report output window.
Tabs can be re-arranged by drag and drop.
Tabs can also be closed by clicking the X
(  ).
).

Reports View is limited to a maximum of 25 tabs at once.
Once 25 tabs are open, subsequent report runs display this warning
and the oldest tab is closed.
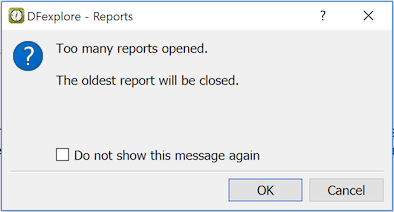
Further, it is possible to undock and dock report tabs. Any tabbed window can be "grabbed" with the mouse and dragged out of the tab bar. This is an undocked report.
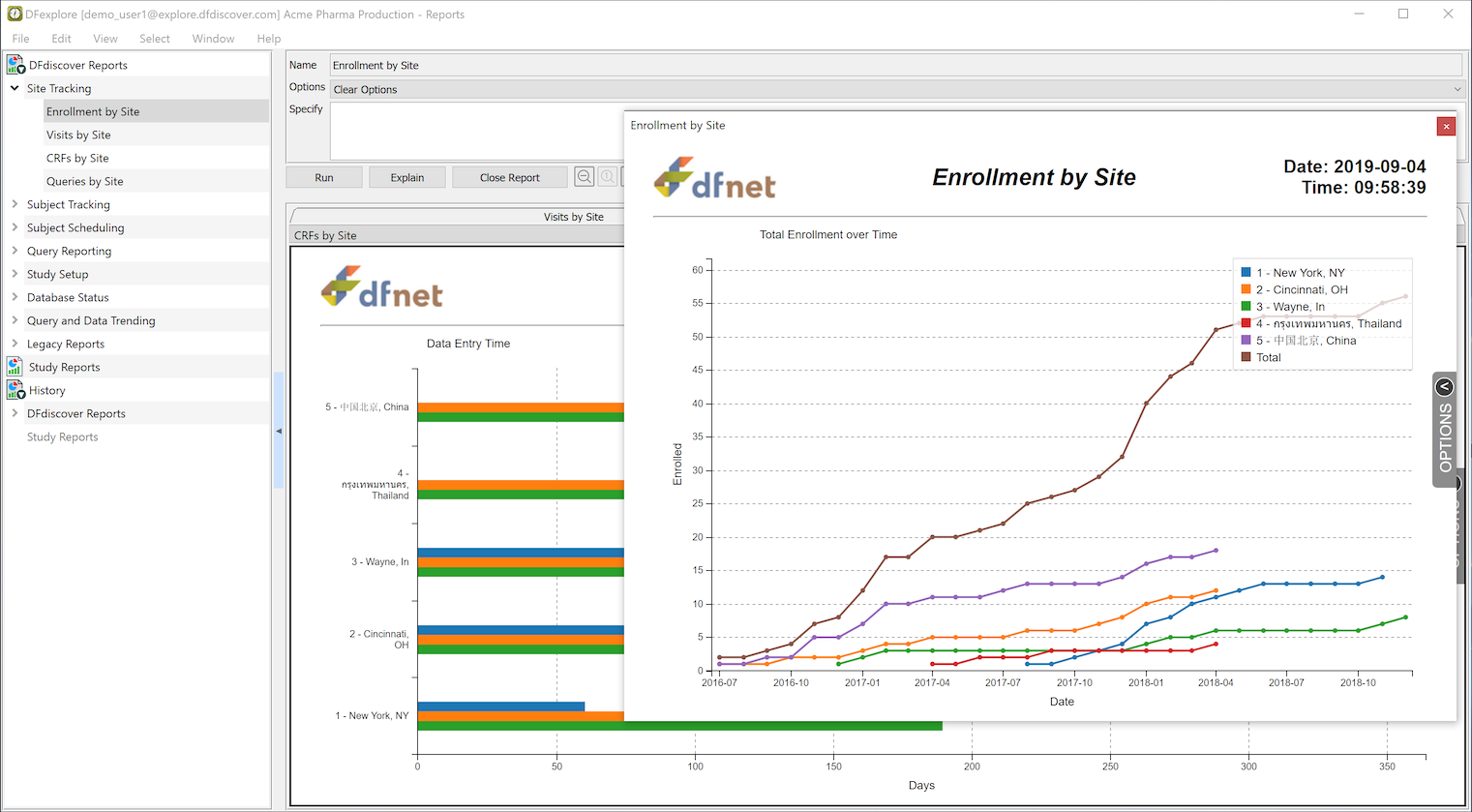
An undocked report can also be re-docked by dragging the tabbed window over top of the tab bar.
DFdiscover reports include built-in interactivity - output can be manipulated and displayed in diverse ways without re-executing the report. Some of the interactivity options include:
Options drawer. The options drawer is opened by clicking on the vertical options tab (
 ).
Several appearance settings and behaviors can be changed in the options
drawer.
Each report has a common option to display/hide the header, plus its own
unique settings.
When the drawer is open, the reports window output is updated immediately
whenever a setting is changed.
When no further changes are needed, click the options tab again
(
).
Several appearance settings and behaviors can be changed in the options
drawer.
Each report has a common option to display/hide the header, plus its own
unique settings.
When the drawer is open, the reports window output is updated immediately
whenever a setting is changed.
When no further changes are needed, click the options tab again
(  )
to close the drawer.
)
to close the drawer.
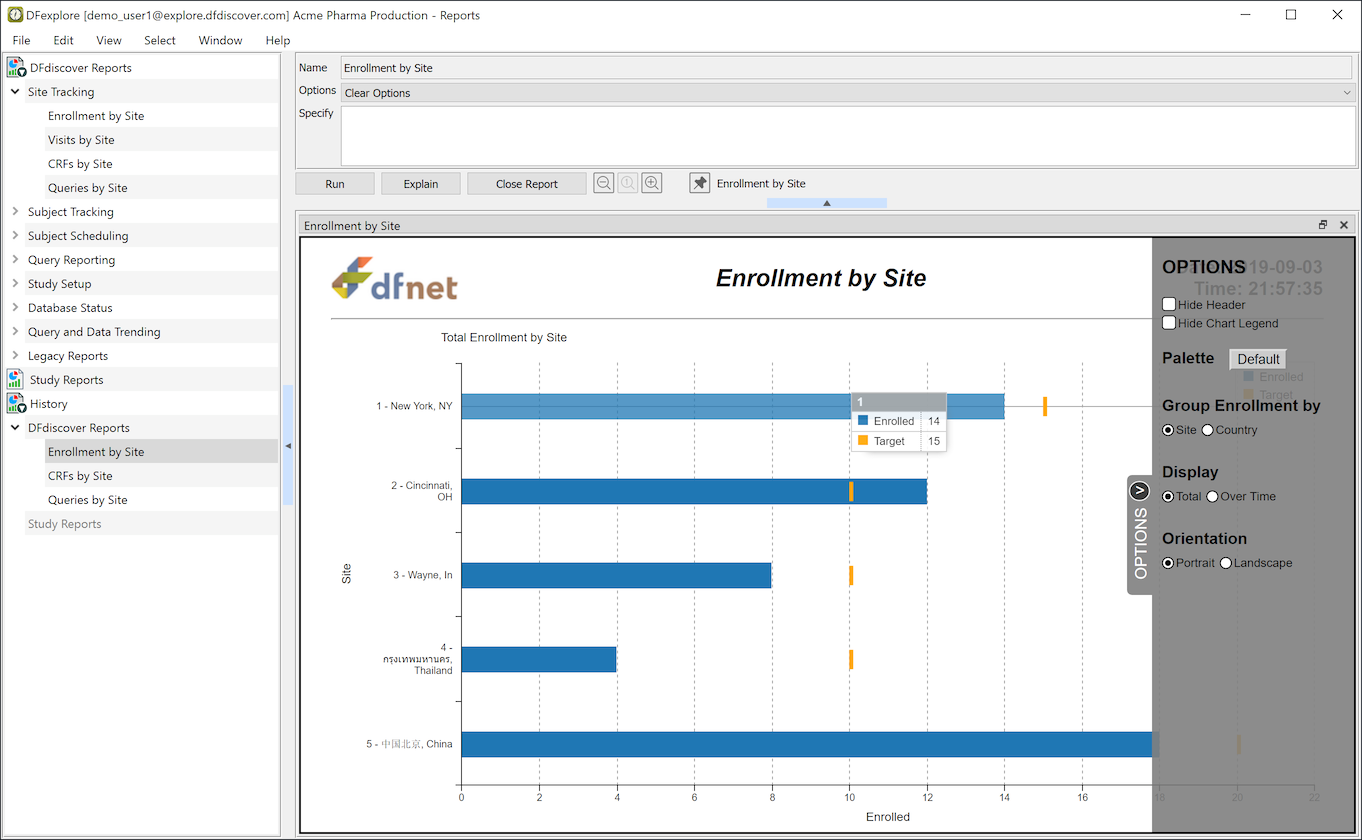
Display/hide elements. The visibility of elements in a graph can be toggled by clicking the corresponding element in the graph legend. Clicking an element once turns off visibility and clicking it again turns on visibility.
Display graph values. By hovering the mouse pointer over a graph or chart element, it is possible to inspect the data value(s) in that element.
Report sub-views. More info for a report is available by clicking a chart or graph element. In some cases, this action creates a sub-view of the current report, switching the displayed content. From the sub-view, you can return to the main report window by clicking the return arrow (
 ).
).
Zoom contents. The contents of any docked report can be zoomed using the zoom controls (
 ).
From left-to-right, the actions are zoom out, return to normal (no zoom)
and zoom in.
For undocked reports, keyboard shortcuts are available. They are
Ctrl+- (zoom out), Ctrl+0 (no zoom) and Ctrl++ (zoom in).
On macOS, as with all keyboard shortcuts, replace Ctrl with Command.
These keyboard shortcuts are also available for docked reports.
).
From left-to-right, the actions are zoom out, return to normal (no zoom)
and zoom in.
For undocked reports, keyboard shortcuts are available. They are
Ctrl+- (zoom out), Ctrl+0 (no zoom) and Ctrl++ (zoom in).
On macOS, as with all keyboard shortcuts, replace Ctrl with Command.
These keyboard shortcuts are also available for docked reports.
Many legacy (and a few DFdiscover) reports include options that can be used to alter what the report produces. For example, DF_PTcrfs (which displays a summary of CRF status for subjects) includes options to specify which subjects, visits and CRF pages are to be included. Report output also depends on your database permissions, and includes only information based on data records you have permission to read.
Selecting the Options widget displays the entire options list. Selecting an option from the list copies it to the Specify window with the part you need to change highlighted. For example, the DF_PTcrfs option used to limit the output a subset of subjects is: -i <#, #-#>.

When this option is selected it is copied to the Specify window with <#, #-#> highlighted.

Changing this to 99010-99020 yields the option -i 99010-99020, which limits the output to those Subject IDs.
Click to run the report with the current options and display the results in the main (output) window. If the preference Each report run opens in a new tab is selected, a new tab is created and the report output is presented in that new tab. Otherwise, the output from each report run replaces the output from the previous report.
By switching to the History list you can select and review the output from all reports you have run since login. The run history is not saved between logins. Use > to create a list of commonly used reports that is available across logins (see Saving Report Lists).
The current output in the report window can be printed or saved, in PDF, HTML, Excel or text format, by selecting any of these options from the menu.
Reports can also be run outside of DFexplore.
For example, the report can be manually executed from a command line or a script,
or scheduled to run at a defined time via a scheduling facility like
crontab.
Select > to
display the complete report command.
Copy the command and paste as needed.
Remember to supply the user password in the report argument
-C xxx, or
use DFpass to store the user password for subsequent
lookup.
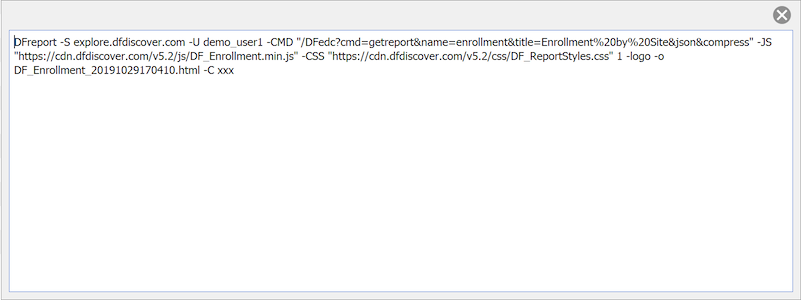
DFexplore includes a convenient "pin" action that adds the report with current focus to the Dashboard View.
Any report can be added to the Dashboard View ("pinned") by running it first
(or selecting it's tab so that it has the focus)
and then clicking the pin button
(  )
which appears to the right in the row of report action buttons.
)
which appears to the right in the row of report action buttons.

Using this feature, it is easy to customize the default appearance of the Dashboard View. Which reports have been pinned is remembered across invocations of DFexplore so these reports also appear in Dashoard View when DFexplore is restarted in the future.
If the report has previously been pinned or is already included in the
Dashboard View as a result of view customization, the button appearance is
inverted
(  ),
showing that the report is already pinned.
When this is true, the report cannot be pinned again.
To update the report in the Dashboard View (perhaps because options have
been changed), first remove the report from the Dashboard View, run it again
and then pin it.
),
showing that the report is already pinned.
When this is true, the report cannot be pinned again.
To update the report in the Dashboard View (perhaps because options have
been changed), first remove the report from the Dashboard View, run it again
and then pin it.
A list of commonly executed reports can be saved for later execution by specified users and/or users with specified roles. You can also specify the user and roles that are permitted to own and thus modify each report list you define. The permissions granted at this level do not over-ride the permissions defined in user roles. If a user lacks permission for any report in a report list, the entire list is unavailable in DFexplore.
A report list is defined using > to access the dialog. Previously defined report lists can be accessed by selecting > . Reports and report options may be added to a report list manually, or the current History list can be used as a starting point and then modified.
To access a previously defined report list, use Select-Report List and select the desired report list.
All reports can be executed in the order they appear in the list by choosing all reports and then clicking . The output from each report is added to the current History list.
Reports can also be executed one at a time by choosing the selected report option, selecting a report from the list, and then clicking .
Select > to write the report output to a file. Different formats are available.
HTML. The report window output is in standard HTML format and contains external references to CSS and JS resources. The saved HTML can be shared and the interactivity of the content is preserved so long as the viewer has an internet connection. Without an internet connection, the report HTML appears as a blank window.
Archive HTML. The report window output is in standard HTML format and has all of CSS and JS resources contained within the file. The saved HTML can be shared and the interactivity of the content is preserved. No internet connection is needed to view the HTML. This option is not available for legacy reports.
PDF. The HTML content of the report output window is saved as a PDF. There is no interactivity in this format.
Excel. Standard DFdiscover reports can save their raw data to an Excel file. There is no visualization applied to the data - the data itself is saved. This option is not available for legacy reports.
Text. Save the output from report in a plain text format. For standard reports, the raw data is saved; for legacy reports, the "formatted" text output of the report is saved.
Table of Contents
DFdiscover is able to calculate and report the current schedule for any subject in the study. This greatly simplifies the task of monitoring individual subject data for missing pages and overdue visits.
The primary interface is Schedule View.
This chapter does not describe how scheduling is defined in DFdiscover. If you are not familiar with scheduling terminology, or scheduling in general, an excellent reference can be found here, Study Setup User Guide, Subject Visit Scheduling.
Schedule View displays all schedule information for permitted sites or subjects. The information is shown in several different schedule and query lists, namely:
Subject Schedule. Display an overall summary of the schedule, one record per subject. Per subject, the summary reports the number of outstanding queries, and the dates of entry visit, last follow-up visit and the next follow-up visit, if any.
Visit Schedule Info. Display a detailed summary of the schedule, one record per subject visit. For each subject, each scheduled visit is reported, including completed and not yet completed visits.
Cycles. Display a summary of the schedule, one record per subject cycle. Each cycle is reported with the cycle status, when it completed and what condition, if any, caused the cycle to become required.
Cycle Visits. Display a detailed summary of the schedule, one record per subject visit cycle. Where cycles occur, report the status of the visits within each such cycle.
Missing and Overdue. Display a list of all pages that are required yet missing, as well as all scheduled visits that have not occurred and are identified as overdue.
Unexpected Visits and Plates. Display a list of all CRFs and visits that have been completed but based upon the schedule are not expected.
Correction and Clarification Queries. Display a list of all outstanding queries, separated in two lists based upon their correction or clarification property.
The Schedule View is interactive.
Double-click a row in any list to switch to Data View. The subject, visit and plate identifiers are used to select the matching record in the database, making it current. Further review or editing of the visible record is then possible, as permitted by the role definition. Click the schedule view icon,
 ,
to return to Schedule View.
,
to return to Schedule View.
By default, the contents of each list are sorted in increasing order of Subject ID. To change the sort order, click on the heading of the column used as the sort key. Each click reverses the previous sort order.
To control which lists are displayed, and updated, use the list control:
Within any list, click the list window control,
 ,
to expand the contents by detaching the list from the main window.
Click the control again to restore the list to the main window.
,
to expand the contents by detaching the list from the main window.
Click the control again to restore the list to the main window.
The contents of Schedule View are aware of the current subject. If a subject binder is open and > is selected, the schedule and query lists are automatically refreshed using the ID of the current subject. If no subject binder is open, the view opens to show the previous schedule, if there was one, or is blank.
To control the contents of Schedule View, use the filter panel.

With no filtering specified, as shown, all permitted subjects and external queries are included. Click to view the results.
To focus on a specific subject, enter the subject ID in the input field and click . To focus on a specific site, choose from the dropdown, enter the site ID or select it from the dialog, and click . By default only queries identified for external use are included. For users that have permission to view internal use queries, mark include internal queries and click . [5]
Schedule View is quite similar to DF_QCupdate in its goals. Both report the visit schedule information for study subjects and identify missing pages and overdue visits. The schedule information presented by both is the same. However, the manner in which the information is generated and maintained differs in several important ways:
The results calculated by DF_QCupdate are static - they are correct at the time that the report is run and then slowly age until refreshed when DF_QCupdate is run again. The results in Schedule View are always up-to-date each time that the Schedule View is presented.
To reflect the results calculated by DF_QCupdate, missing page and overdue visit queries are maintained in the study database. Schedule View does not create missing page or overdue visit queries.
DF_QCupdate requires a user with full database permission to run the report, including the permission to add queries. The results are calculated for the entire study every time. Schedule View can be narrowed down to an individual site, or even an individual subject. The Schedule View does not need query write permission and can also be calculated from a read-only database.
The output from DF_QCupdate is easily shared with external parties, who have no access to the study database, by emailing a PDF generated by DF_QCreports. Schedule View requires that the user has access to DFexplore and at least read access to their site or subject data.
[5] If the user does not have any permission to view internal queries, this option is not present in the filter panel.
Table of Contents
Status View provides an overview of the status of the study database and shows the list of users who are currently working on the study. It can also be used to quickly assemble a set of records to perform a task by double-clicking any cell in the tables.
The Status View displays the number of data records, queries and reasons in the study database categorized by their workflow level and status. Workflow labels in Status View have been previously defined in DFsetup, > . Each label is followed by the level number that the label represents. If a workflow label is blank and there are no records at this level, the unused level does not appear in the table. If a workflow label is blank and there are records, only the level number appears.
When Status View is selected it displays the status of the entire study database.
The results displayed in the tables and graphs can be filtered by study site, subject ID, visit and plate. The to the right of each entry widget is used to display and select valid entries for each specification. A list of values and ranges can be entered, e.g. Site: 1-9,21,30-44,81,82. Select to apply the current filter and to remove all filter specifications. After clicking , any filter specifications remain in effect for the duration of your login session.
Click to the right of Subject to open another dialog for Selecting Subjects based on Criteria. This dialog facilitates subject selection based on multiple criteria across multiple plates.
To return to the status for the entire study database select and then .
You can jump to the records displayed in any cell of the table, including row and column totals, by double-clicking the cell.
Double-clicking a cell in the Data Records table creates a task set containing the records defined by the criteria for that cell and opens them in Data View. Double-clicking cells in the Queries table allows you to choose to open the task set in either Queries View or Data View, and double-clicking cells in the Reasons table allows you to choose to open the task set in either Reasons View or Data View. These task selections are successful only if you have permission to use these views.
The information displayed in Status View depends on user permissions. The tables and graphs include only records you have permission to see, and only the counts shown for records available in the Image Router and the Image Queue are displayed if you have permission to use Image View and Image Router.
Status View displays the number of study CRF pages that have arrived and are waiting to be reviewed and entered into the study database. These records are not counted in the Data table. This count is only visible to users who have permission to use Image View to review and enter these pages. Double-clicking the cell opens Image View for such users.
Status View also displays the number of CRF pages that have arrived but could not be routed to any of the current DFdiscover studies because the study number could not be identified. These pages need to be reviewed manually and routed to the appropriate study if they are study CRFs. This count is only visible to users who have permission to use Image Router. Double-clicking the cell opens Image Router.
Edit checks are defined during study setup. They execute interactively during data entry and data review, and can also be programmed to execute unattended, in batch mode.
The Batch Edits View is the interface for controlling this latter, unattended mode.
Batch Edits View provides a visual interface to the DFbatch facility described in Programmer Guide, Batch Edit checks.
Batch Edits View is divided into 3 separate but related panels:
Batch Control. A batch control file groups together one or more batch definitions. If multiple batch definitions must always execute together, they should all be referenced in the same batch control file.
Batch Definition. A batch definition specifies the records to be included in the batch run and the actions to be applied.
Batch Results. The batch results typically include log messages of the actions taken and their results. There is nothing further for you to specify here.
Click and select to start a new batch control file. To open a previously defined batch control file, click and select .
Batch control files can reside on the server (if they are meant to be shared by study personnel), or locally on your computer. Choose the location of the new, or existing, batch control file and click .
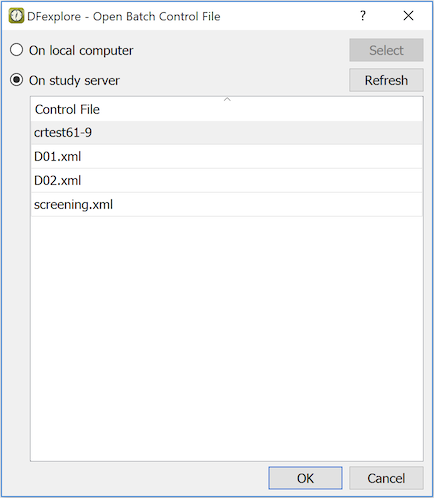
After opening, the batch control file properties are displayed in the Name, Moveto and Reason fields and the names of the batch definitions are displayed in the BATCHLIST list. The meaning of the Moveto and Reason directives are described in Programmer Guide, MOVETO and Programmer Guide, REASON.
To review or modify a batch definition before executing it, select it from BATCHLIST and click . The definition of the selected batch updates the second panel, the Batch Definition panel. If the batch was previously executed, the third panel, Batch Results, is also updated to show those previous results.
To execute one or more batches, select them from BATCHLIST and click .
Review the information presented in the confirmation dialog. If no changes are needed, click . If changes are needed, click and update the batch definition and/or selections from BATCHLIST.
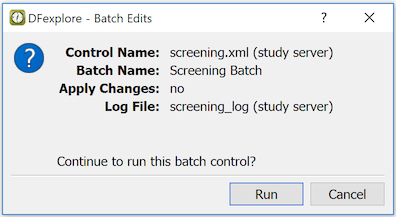
The Batch Definition panel is displayed by clicking in the Batch Control panel.
This panel is a visual editor for a batch definition. A batch definition is divided into a descriptive section (BATCH), action sections (APPLY, LOG, and ODRF) and a selection section (CRITERIA). Each section corresponds to tags in the batch definition file. These tags and their meaning are explained in Programmer Guide, Batch Edit checks.
If changes are made to the batch definition, including start a new batch control file, remember to click to save the changes.
The output from the execution of a batch is presented in the third, Batch Results, panel. The default visualization is an HTML spreadsheet. The underlying XML can also be viewed by choosing xml.
There are several options for controlling the presentation of the results.
In the Execution History table, the current execution appears first. Double-click one of the rows to view the results for a specific execution.
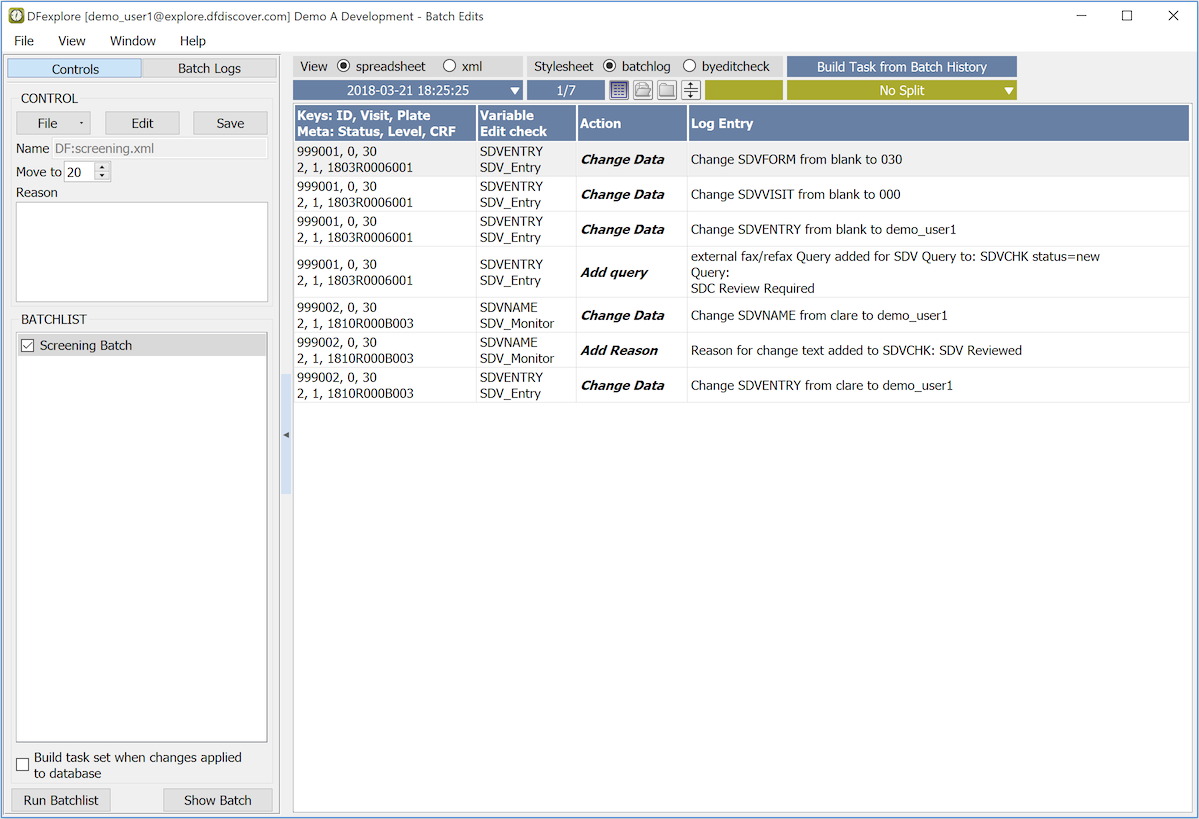
In this results view, double-clicking any entry takes you directly to the specific record and field in Data View. This allows you to easily navigate between the results of a batch run and the individual records involved.
Table of Contents
When DFdiscover receives pages which it cannot recognize, it stores them in a special folder where they can be reviewed using the Image Router functionality in DFexplore. One or more users must be assigned this regular task.
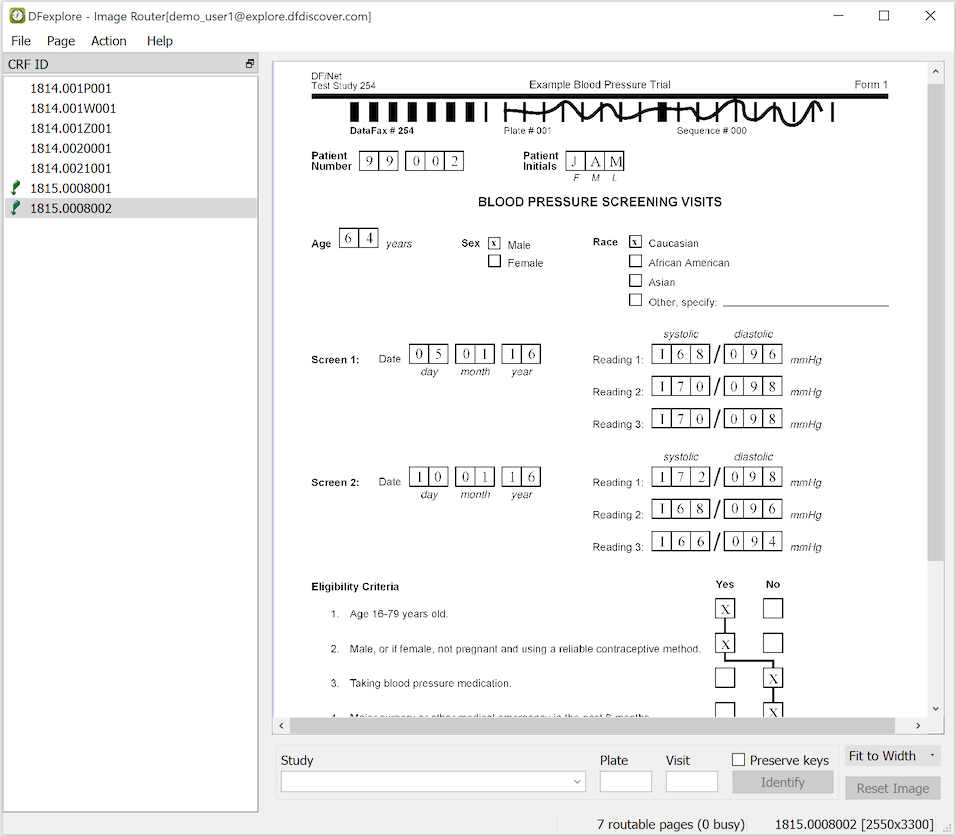
DFdiscover will fail to recognize pages when there is no barcode (e.g. memos, letters, cover pages), or when the barcode is obscured (e.g. by fax noise, a coffee stain, something printed over it).
Without a readable barcode, DFdiscover cannot automatically identify the study. Thus all unidentified pages are stored in this same special folder. If several studies are running concurrently, the individuals who review and identify pages using the Image Router must be sufficiently familiar with all studies to correctly route each page. Unidentified pages can be received by fax, through DFsend or as email attachments.
Study CRFs are not difficult to identify correctly unless the barcode is missing altogether. In such cases the contents and design of the CRF may be enough to correctly identify it. If not, selecting > provides information about the sender, which may assist in determining the destination study for the page.
DFdiscover creates missing plate and overdue visit queries for required CRFs and visits that have not arrived (as specified in the study visit map). Thus queries may be generated for pages that have been transmitted by the sites but are currently awaiting identification in the Image Router folder. A recommended procedure is to always ensure that no CRFs are awaiting Image Router identification before DF_QCupdate is scheduled to run.
The Image Router is used to:
Review all unidentified pages.
Get context (determine when the document arrived and where it came from).
Delete pages that are not needed (e.g. fax cover sheets, blank pages).
Print non-CRF pages or save them to a PDF file.
Fix any document transmission problems (e.g. flip, rotate, truncate, cut pages).
Identify CRFs and other subject documents and forward them to the correct study database.
Three factors determine what a user can do in the Image Router:
Router Permission. Permission to use Image Router is typically granted to a small number of users at the DFdiscover server site. Users with router permission can start the router and view, print, delete and check the context of all unidentified pages that arrive to the DFdiscover server. They can also identify and send pages to any study on the server, even if they have no other study permissions.
Study Status. DFdiscover and study administrators can place temporary or permanent restrictions on a study by changing it's status to: disabled, read-only, restricted, or both restricted and read-only. CRFs cannot be sent to studies that are disabled or in read-only mode.
DFdiscover and Study Administrators. Only DFdiscover and study administrators can send pages to a restricted study. If a study is also in read-only mode, or is disabled, not even administrators can send pages to the study.
To start Image Router, click in the study selection dialog. This button is visible only if you have permission to use the Image Router.
Each page, shown in the CRF ID page list,
is identified by a unique image name (the CRF ID).
This image name has the format yyww.ffffppp,
where yy is the year, ww is the week,
ffff is a sequential document transmission ID,
and ppp is the page number within the transmission.
Image Router can be used concurrently by multiple users.
Pages are locked and released as each user traverses the page list.
When a page is selected it, and all other pages in the same document transmission,
are locked - this prevents other users from processing pages from the same document.
Small icons reflect the current status of each page in the page list. An exclamation mark signifies a page that is locked by the current user, a lock icon identifies a page that is currently locked by another user, and a red X icon indicates a page that has been processed (routed to a study, deleted, or saved). The user's login name and the DFdiscover server name are shown in the title, and a message at the bottom of the screen tracks the number of pages to be routed, the number of pages locked by other users (busy), and the current image name and size in pixels (width x height).
Image Router workflow typically proceeds in three simple steps:
select a page,
perform image processing (e.g. rotation, flip, etc.) on that page, and
identify the "keys" (study, plate and visit) for the page, using the input fields and controls at the bottom of the screen.
For pages that are not study CRFs, it is also possible to print or discard them.
Pages without barcodes may also be identified, provided you are able to determine the study, plate and visit numbers using other features. As an aid to identification the image can be resized from 50-200% using the Zoom option. This has no effect on the size of the image stored in the study database.
If most pages have similar keys the Preserve keys check box can be used to prevent the key fields (study, plate and visit) from being cleared after each new page is identified.
If a set of pages all have the same keys and do not require image processing, they can be identified together in one step by making multiple selections from the page list before clicking .
Image Router sends all identified pages to the new record queue for the respective study where they join other pages that were identified automatically from their barcodes.
Use the menu to access generic Image Router functions. Remember that Image Router is a sub-window of DFexplore. You can move to and from DFexplore using menu items from the menu.
Select to refresh the page list with any unidentified pages that may have arrived since the current session began. Image Router does not automatically update the list of CRF IDs in the page list.
Select to open the study selection dialog and select a study for concurrent access in another instance of DFexplore, while keeping the Image Router window active.
This menu accesses the functions that allow you to manipulate pages (rotate, shift, flip, cut, truncate, and reset) before sending them to the study database.
For DFdiscover to properly identify and read a CRF, the signature line (horizontal line at the top of the CRF) first has to be located and placed in a standard, expected position. Without this standard positioning, DFdiscover will have difficulty locating, and reading, the data fields positioned on the remainder of the CRF. Under normal circumstances, DFdiscover does all of this automatically. For CRFs that cannot be automatically identified, user intervention using the functions in this menu is needed.
This menu also contains functions for navigating to other pages, printing pages and determining where each page came from (context).
Select to correct page rotation. This is needed if the page signature line at the top of a study CRF is not horizontal. Page rotation usually results from failure, at the transmitting site, to adjust the page guides snugly against the sides of the CRF pages when they are being scanned by the fax machine.
Instructions for this operation appear in the status line at the bottom of Image Router window. Click the left mousebutton on the top-left end of the horizontal signature line and then click again on the top-right end of this line (or click the right mousebutton to cancel this operation). When the operation is complete, the screen updates to show the realigned image. Click to undo this operation, and try again.
Use when the page does not need to be rotated, but instead only needs to be shifted vertically. Shift is used to register the upper-left corner of the page signature line.
To shift a page click the left mousebutton anywhere on the top edge of the horizontal signature line (or click the right mousebutton to cancel this operation). The vertical location of the mouse pointer is important - the horizontal position is ignored. After clicking the left mousebutton once, the screen updates with the shifted image. Click to undo the shift and try again.
Selecting turns the page upside down, by rotating it 180°. Selecting it a second time returns the page to its original position.
Occasionally a page may be received that is really 2 pages (or more) joined together. This can occur if the transmitting scanner is slipping while pulling consecutive pages through the document feeder. In the Image Router window this is evident because the page length is much greater than the length of a single page. In such cases, it is necessary to cut the long page into individual pages at the appropriate page boundaries.
![[Warning]](../../imagedata/warning.png) | Warning |
|---|---|
The Cut action cannot be undone. |
Selecting overlays a horizontal line on the page. Move this line to the desired cut position (representing the bottom of the first page) and click the left mousebutton to register the cut point, or click the right mousebutton to cancel.
After the cut point is registered a confirmation dialog appears. A page cut operation cannot be reversed. Click to confirm the page cut or to abort the action.
On rare circumstances, the original page may contain more than 2 consecutive pages. In this case, simply select the second page (the bottom portion of the original page) and repeat this procedure to cut again (and maybe again).
The size of the page (width x length, in pixels) is shown in square brackets at the bottom of the screen. After a CRF has been shifted to the top of the page signature line it should not be longer than 1050 pixels in standard definition (approximately 1120 pixels if the source document was A4 size), or 3150 pixels in high definition. Any other length suggests that there are either multiple concatenated pages (in which case the page should be cut) or there is "noise" (unneeded content) at the end of the page. In such cases, examine the bottom of the page to see if it contains noise. If it does, select to remove the excess length.
Click to undo the operation and restore the original page length.
Fax machines that can accommodate pages wider than 8.5 inches require their paper guides set to 8.5 inches for proper scanning of letter-size pages into DFdiscover. If the guides are set too wide, the paper can tilt or shift, resulting in skewed or abnormally wide images. When pages like this are received, they generally appear in the router because they are wider than the width of a US letter-size page. To route a wide page, trim the width of a page by selecting . Two dashed vertical lines appear over the document spaced 8.5 inches apart. Using the mouse, position the lines over the area of the page to preserve. Click the left mousebutton to keep the area between the lines, and discard the page area that lies outside these two lines, or click the right mousebutton to cancel the operation. Click to undo the operation.
To rotate a page 90° clockwise select , or counter-clockwise by selecting . Each time the option is selected, the current page is rotated 90° in the specified direction. This is useful when a sender sends a page in landscape orientation and it needs to be put into portrait orientation. Click to undo all operations on the page, or rotate the page in the opposite direction to return it to it's previous orientation.
It is possible to process landscape pages by rotating them into portrait orientation and scaling them to fit the width of a portrait page. This is performed using or . Select the appropriate menu item to apply the needed rotation. The page is rotated and then scaled to fit the width of a portrait US letter page.
To print one or more pages, highlight the page or pages from the page list and select . The operating system print dialog is displayed. Change the necessary print settings before printing.
To export one or more pages in a PDF file, highlight the page or pages from the page list, and select . The operating system's standard file save dialog is displayed. Specify a file name and save.
This function provides information that may aid in determining the source of an unidentified page. It provides the page number within the document, the date and time on which the document was received, and the sender identification header - which is usually the sender's fax number, an email address, or username from a DFsend user).
Select this function, or , to undo all Rotate, Scale, Shift, Flip, Trim and Truncate manipulations that have been applied to the current page; the only exception is Cut, which cannot be undone. Reset is also performed automatically when a different page is selected before identifying the current one to send it to the desired study database. Once a page has been identified, page manipulations are permanent.
This menu contains all of the functions that routes pages to a study and remove pages from the Image Router. All actions are immediate. Once committed they cannot be undone.
Most CRF pages can be aligned, identified and routed to the appropriate study database in a single step by selecting . Follow the directions at the bottom of the window to identify the CRF page signature line. The page is then rotated and shifted (if necessary) and another attempt is made to read the barcode. When this has been done, enter or correct the keys (Study, Plate and Visit) as needed and click .
If the plate is defined as having the visit number in the barcode it must be entered before clicking ; an error message appears otherwise. Alternatively, when the visit number is the first data field on the plate, the Visit key should be left blank - it is silently ignored if a value is entered.
A Right-Click mousebutton aborts the Rotate/Shift/Identify action. Once is selected, the action is committed and cannot be undone. The page is sent for ICR processing and routed to the designated study database. There is a brief pause while this is being done. Then the page is removed from the page list, and the next unidentified page is displayed (if there is one).
Select to move a page to a specified file name on the local computer. Specify the destination location for the file using the operating system's standard file dialog. Moved files are removed from the DFdiscover server and stored in PNG format on the local computer. This may be appropriate for documents of a personal, or non-study, nature.
Table of Contents
When the DFdiscover administrator created your account, they defined a user profile for you. That profile includes your name, your mailing address, your contact information and your password.
You can examine your current user profile by choosing > .
Values below the horizontal rule can be edited. It is not possible to change your Username, Full Name, or Email [6]. Edited values are saved when clicking .
You can change your password at any time by clicking . The dialog requires you to enter a new password and then re-type it to confirm the changed password.
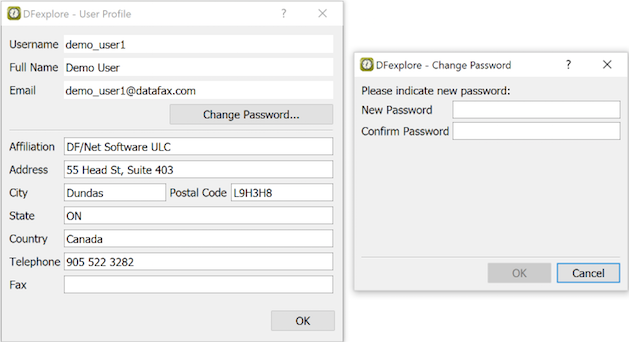
DFexplore saves several attributes of your current session so that those attributes can be automatically applied when you login again. Session settings are unique to a specific username, DFdiscover server and study. Further they are stored on the local computer. This combined flexibility allows you to have different settings for different studies, different servers and different local computers.
The session attributes that are saved include:
Window layout, window size and dialog positions
Preferences
Proxy configuration settings
The appearance and behavior of many features and dialogs within DFexplore can be customized with application preferences. Select > to access these preferences.
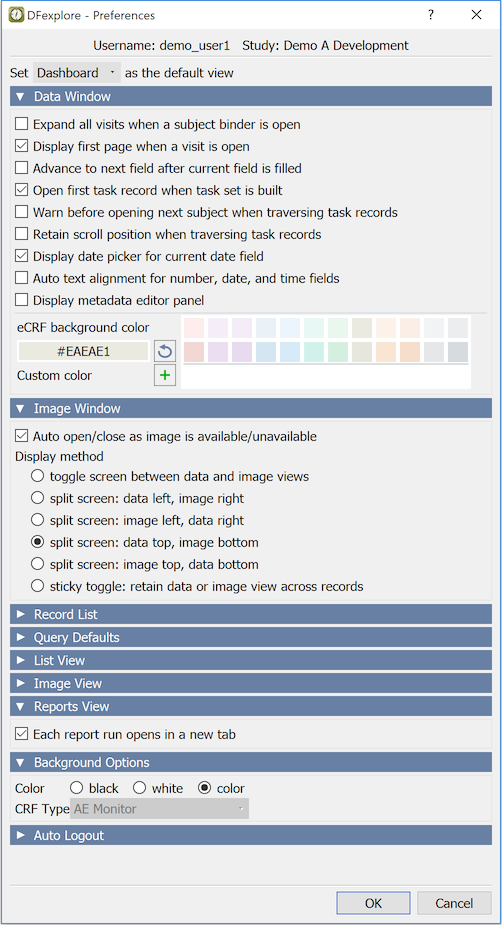
Preferences are user and study specific. Changes are applied immediately and are preserved across sessions. Some preferences may refer to parts of DFexplore for which you do not have permission, and will thus be irrelevant.
A description of each of the preference settings follows.
There are several Views in DFexplore. From the drop-down list, choose the view that you would like to open by default each time you start DFexplore.
The data window is visible in Image View as well as Data View.
-
Expand all visits when a subject binder is open: If this preference is checked all visits are also opened to show the CRF pages they contain. Otherwise, subject binders open to show all study visits but all visits are closed.
-
Display first page when a visit is open: If this preference is checked, the data screen is automatically loaded with the first page of the visit when a new visit is opened.
-
Advance to next field after current field is filled: By default, the focus remains on each field until you press the Tab or Return to advance to the next data field. Enable this preference to automatically advance to the next data field when the response for the current field is filled.
-
Open first task record when task set is built: If this preference is selected the first data record is opened automatically when a new task is selected; otherwise, you must open the first task record manually by selecting the desired subject binder.
-
Warn before opening next subject when traversing task records: This preference is relevant if you have access to record selection tasks and is used to ensure that you are aware of transitions from records for one subject to records for a different subject.
-
Retain scroll position when traversing task records: This preference is relevant to users who have access to record selection tasks. It is useful when the task involves a review a fields near the middle or bottom of each page, as it prevents the normal scroll to the top of each new page.
-
Display date picker for current date field: For fields that require a date value, enabling this preference displays a calendar widget next to the field when it gets the focus. Date values can be entered by selecting them from the calendar widget or via normal data entry.
-
Auto text alignment for number, date and time fields: The font used for data entry may not exactly fill the space available in the data entry field. Checking this preference causes the data value to re-draw after entry so that it "fills" the data entry field. This is purely a visual preference and has no impact on the data values.
-
Display metadata editor panel: The metadata editor panel is an optional view of the Query, Reason, Metadata and Help windows. Enabling this preference displays the metadata editor panel and hides the separate Query, Reason and Metadata panels, expanding the subject binder list.
-
eCRF background color: For an eCRF data entry page, choose the color pair that is used to background fill the alternating rows of data entry fields. Commonly used color pairs are presented or you can specify a custom color.
The image window is visible in Image View as well as Data View.
-
Auto open/close as image is available/unavailable: If checked, images/documents are automatically displayed when a page having such images is selected. When this preference is selected the presentation of the data and image window is further refined by the Display method choice:
-
toggle screen between data and image views: Switching between data and image views is performed using the blue image button in the bottom-right corner of the screen, but the data view will always appear on switching to a new page in the subject binder.
-
split screen: data left, image right: If an image is attached to the current data record, split the screen horizontally and display the data window to the left and the image window to the right.
-
split screen: image left, data right: If an image is attached to the current data record, split the screen horizontally and display the image window to the left and the data window to the right.
-
split screen: data top, image bottom: If an image is attached to the current data record, split the screen vertically and display the data window on the top and the image window on the bottom.
-
split screen: image top, data bottom If an image is attached to the current data record, split the screen vertically and display the image window on the top and the data window on the bottom.
-
sticky toggle: retain data or image view across records: Switching between data and image views is performed using the blue image button in the bottom-right corner of the screen, and the last setting remains in effect when switching to a new page in the subject binder.
-
The Record List appears to the left of the main window. It's primary purpose is to aid navigation of sites, subjects, visits and plates.
-
Display visit as number:label, number, label: Each subject visit has both a number and a descriptive label. This preference determines how a visit is identified when a subject binder is opened.
-
Display plate as number:label, number, label: Each plate has both a number and a descriptive label. This preference determines how the pages within subject visits are identified when a visit is opened.
-
Display site as number:label, number, label: Each site has both a number and a descriptive label. This preference determines how sites appear in the record list.
Record navigation: This preference determines whether the contents of the list wille be displayed as nested sites, subjects, visits, and plates, or as a linear list.
-
Use external or internal: This preference is relevant to users who are allowed to create new queries and determines the default usage type in the query creation dialog. External queries are directed to clinical sites, while internal queries are not.
-
Type clarification or correction: This preference is relevant to users who are allowed to create new queries and determines the default response type in the query creation dialog. Clarification queries are used to request a reply to a question, while correction queries are used to request a correction to one or more data fields.
-
Display field name as description, name or alias, and optionally prepended with the field number: Specify column labels for the list view data table. These labels can display the field description, field name or field alias, and may optionally include the field's data entry tab order number.
-
Display coded field as code or label: For fields that have codes and labels, e.g. 1=male, 2=female, this preference determines whether the code or label is displayed.
-
Display date field as default, calendar, julian, and apply imputation rule: Dates may be shown exactly as entered into the study database (default), in calendar format (with 4 digit years), or as a julian number. In addition any imputation rules that have been specified for partial dates may be applied if the calendar or julian format is selected.
-
Fill cell with field color: Each cell in the data table can be presented with the same color used in Data View and Image View.
-
Expand text fields: If cells in the data table are too small to display the entire data field, enabling this preference expands the cell when it has the focus so that it can display all of its contents.
When a CRF page is re-submitted users perform duplicate resolution by loading the existing data record, comparing it with the new image, and correcting any data fields that need to be updated. During this process users can select the image count button at the bottom of the screen to review the previous and new CRF images. Alternatively either or both of the following preferences can be used to display the image review dialog automatically:
-
When the existing record is loaded: Check this option if you want to compare the old and new CRF images before reviewing and correcting any data fields.
-
When the revised record is saved: Check this option if you want to delay image comparison until after reviewing, correcting and saving the data record.
-
Each report run opens in a new tab: Check this option to have the output from each report run, or explain, appear in a new tab. If this option is not checked, the output from each report run, or explain, appears in the same tab, overwriting any previous output.
-
Color black, white or color: Are data fields displayed on a black, white or color background? Color is useful if color CRFs have been imported in DFsetup to create the data screen backgrounds.
-
CRF Type: Different versions of some or all of the CRF pages can be imported during study setup. This preference allows you to select the version of the CRFs to be used for both the data entry screens and when printing CRFs or creating PDFs.
-
Exit after XX minutes of inactivity: An automatic timeout, after a period of inactivity, is required to meet regulatory requirements and protect subject confidentiality. Study administrators specify a default and maximum time period for each study. You can change this default to any value up to the maximum.
Table of Contents
- A.1. Terminology
- A.2. DFexplore Keyboard Shortcuts
- A.3. Common Error and Warning Messages
- A.4. Programs
- A.5. Selecting Subjects based on Criteria
- A.6. CDISC ODM Export
- A.7. External Software Copyrights
- A.7.1. DCMTK software package
- A.7.2. Jansson License
- A.7.3. Mimencode
- A.7.4. RSA Data Security, Inc., MD5 message-digest algorithm
- A.7.5. mpack/munpack
- A.7.6. TIFF
- A.7.7. PostgreSQL
- A.7.8. OpenSSL License
- A.7.9. Original SSLeay License
- A.7.10. gawk
- A.7.11. Ghostscript
- A.7.12. MariaDB and FreeTDS
- A.7.13. QtAV
- A.7.14. FFmpeg
- A.7.15. c3.js
- A.7.16. d3.js
This section explains some of the terminology used in this guide.
CDISC |
CDISC is a global, open, multidisciplinary, non-profit organization that has established standards to support the acquisition, exchange, submission and archive of clinical research data and metadata. The CDISC mission is to develop and support global, platform-independent data standards that enable information system interoperability to improve medical research and related areas of healthcare. CDISC standards are vendor-neutral, platform-independent and freely available via the CDISC website. |
Electronic Signature |
Your electronic signature has two parts - your login name and your password. You must specify both parts when you log into the study's DFdiscover server. All data collected is recorded under your electronic signature and can be traced in DFdiscover audit trail reports. |
Final |
Final is a record status. A page can be saved with status Final if there are no illegal values or unanswered queries from the study coordinating site. DFexplore marks Final pages with a green shaded rectangle (see also Incomplete and Pending). |
Incomplete |
Incomplete is a record status. A page can be saved with status Incomplete if it has one or more fields which are incomplete or illegal, or outstanding queries. DFexplore marks Incomplete pages with a red partially shaded rectangle (see also Final and Pending). |
ODM |
The CDISC Operational Data Model (ODM), which is maintained by the CDISC XML Technologies Team, is designed to facilitate the regulatory-compliant acquisition, archive and interchange of metadata and data for clinical research studies. ODM is a vendor neutral, platform-independent format for interchange and archive of clinical study data. The model includes the clinical data along with its associated metadata, administrative data, reference data and audit information. All of the information that needs to be shared among different software systems during the study setup, operation, analysis, submission or for long-term retention as part of an archive is included in the model. |
Page or Plate |
Page and plate are 2 terms used interchangeably to refer to a logical grouping of data items (aka data fields) presented with a layout determined by the study sponsor, to fit on a single sheet of paper, or single screen. Each page may stand alone, or pages may be grouped into multi-page forms. A collection of pages (or forms) constitute a visit, and a collection of visits constitute the subject binder which holds all study data for an individual subject. In a paper-based approach to data collection, these pages are printed, completed and sent to the DFdiscover system. When using an EDC approach, the same pages are completed using DFexplore. |
Pending |
Pending is a record status. During new data entry a page can be saved with status Pending to indicate that you are not finished with it and plan to return to it shortly. These pages are saved at workflow level 0 and do not move to higher levels until they are saved with status Final or Incomplete. Typically pending pages at level 0 will not be reviewed by the study coordinating site until they progress to level 1 or higher. Pages which have progressed beyond level 0 cannot return to level 0, but they can be reset to status Pending to indicate that there is something incorrect which needs to be corrected before the data can be used in statistical reports. The ability to demote records this way is restricted to users with Data View - with Select permission. DFexplore marks Pending pages with an orange outline rectangle (see also Final and Incomplete). |
Query |
A query is a question or comment about a data value. The study coordinating site may add a query to any data field to request a correction or clarification. DFexplore colors fields with an outstanding query blue. When a reply is provided to a query, or a reason is added to explain the field, the color changes to orange, and when the field has been corrected, or the reply or reason have been approved, the color changes to green, provided there are no other outstanding queries on the field. |
Reason |
A reason explaining a data value can be added to any data field. This is particularly useful as a way of explaining unusual values and thereby avoiding a data query from the study coordinating site. DFexplore colors fields with a new reason orange and gives them a Pending status. If the coordinating site accepts the reason, the field color changes to green and reason status changes to Accepted. If they do not accept the reason, the field color changes to blue and the reason status changes to Rejected. A reason can be modified, which starts the review process over again. |
Save |
None of the changes you make to a page are saved to the study DFdiscover server until you click one of the 3 Save buttons: Final, Incomplete, or Pending. If you leave the computer without saving your work, DFexplore will time-out after a few minutes and the changes you made will be lost. However, you will be warned that this has happened the next time you connect to the study and you can opt to return to the same page. |
Subject |
An individual participating in a research project for whom data will be collected is a subject. Subjects are identified by subject ID (a unique numeric identifier), according to conventions established by the study coordinating site. |
Subject Binder |
A subject binder contains all of the required and optional data collection forms used to collect study data for an individual subject. Within DFexplore, subject binders are displayed in a list by subject ID, with an associated icon that shows whether the binder is empty or contains recorded data, and whether that data is currently complete, incomplete or pending. |
This section is a reference for the standard keyboard shortcut keys
available in the Windows DFexplore client. Keyboard shortcuts for
the macOS DFexplore client are the same except that the
Ctrl key is replaced
with the Command key.
Table A.1. Switching Views
| Ctrl+1: | Switch to Dashboard View |
| Ctrl+I: | Switch to Image View |
| Ctrl+D: | Switch to Data View |
| Ctrl+U: | Switch to Queries View |
| Ctrl+R: | Switch to Reasons View |
| Ctrl+E: | Switch to Reports View |
| Ctrl+Shift+S: | Switch to Schedule View |
| Ctrl+S: | Switch to Status View |
| Ctrl+L: | Switch to List View |
| Ctrl+Shift+B: | Switch to Batch Edits View |
Table A.2. Data Entry Field Traversal (Data, Image Views)
| Tab, Return: | Move focus to the next field |
| Shift+Tab, Shift+Return: | Move focus to the previous field |
| Ctrl+Tab, Ctrl+Return: | Move focus to the next problem field |
| Ctrl+Shift+Tab, Ctrl+Shift+Return: | Move focus to the previous problem field |
Table A.3. Missing Value Code Assignment (Data, Image Views)
| Ctrl+M: | Repeat assignment of the same missing value code |
Table A.4. Scrolling a Fax Image (Data, Image, List Views)
| Ctrl+T: | Scroll to the top of the image |
| Ctrl+B: | Scroll to the bottom of the image |
Table A.6. Open a New Study (File-New Study menu)
| Ctrl+N: | Invoke the DFexplore login dialog to open a new study |
This section details some messages that users may encounter during their use of DFexplore.
Table A.8. DFexplore Login
| Message: | The DFdiscover server is not reachable. Confirm the server name and network connection. |
| Possible Cause: | There is no internet connection available or the server address/name entered is invalid. |
| Solution: | Confirm that your internet service is functioning properly. Confirm that you have correctly entered the DFdiscover Server in the login dialog. Otherwise, contact your Study Coordinator or DFdiscover Administrator. |
| Message: | Unable to connect to the DFdiscover server. Confirm that DFdiscover is available. |
| Possible Cause: | DFdiscover is not running on the specified server. |
| Solution: | Contact your Study Coordinator or DFdiscover Administrator and confirm that the DFdiscover server is available and running properly. |
| Message: | Unable to get a list of studies from the server. |
| Possible Cause: | The user has not been given access to any studies or the DFdiscover server is not running. |
| Solution: | Contact your Study Coordinator or DFdiscover Administrator. |
| Message: | Error: Unable to load study setup file |
| Possible Cause: | The study Setup file does not exist or is empty. |
| Solution: | Contact your Study Coordinator or DFdiscover Administrator. |
| Message: | Unable to load subjects. |
| Possible Cause: | The sites database does not exist or is empty, or you do not have permission to access subject IDs due to restrictions defined by the Study Coordinator or DFdiscover administrator. |
| Solution: | Contact the Study Coordinator or DFdiscover Administrator. |
| Message: | Unable to load visits. |
| Possible Cause: | The DFdiscover study DFvisit_map does not exist or is empty, or the user may not have permissions to access the necessary visits and/or plates due to restrictions defined in their study role. |
| Solution: | Contact the Study Coordinator or DFdiscover Administrator. |
| Message: | It appears that the local computer's date and time are incorrect. DFexplore has been set to view only mode until the date and time are fixed, and then login again. |
| Possible Cause: | Either DFexplore cannot obtain a valid date and time from the local computer, or the value obtained is more than 48 hours ahead or behind the value obtained from the study database server. |
| Solution: | Update the date and/or time on the local computer. |
Table A.9. Data Entry
| Message: | Due to inactivity, the connection has been logged out. |
| Possible Cause: | Your DFexplore session has been inactive for the number of minutes specified by the Auto Logout setting. |
| Solution: | You can customize the number of minutes after which the DFexplore auto logout takes effect. The default Auto Logout setting may be changed by logging into DFexplore, selecting > and changing the Auto Logout preference. |
| Message: | The definition of this page has changed. This page needs to be reviewed centrally before you can access it again. Please notify your study coordinator. |
| Possible Cause: | This message arises when the number of fields on a page has been changed so that its definition no longer matches the data already existing in the database. |
| Solution: | The data records for the page will need to be reformatted before you can access them. Contact your Study Coordinator or DFdiscover Administrator. |
| Message: | This page cannot be saved with status Final because of problems identified by edit checks. |
| Possible Cause: | Edit checks that are set to execute upon saving the page may cause certain data fields to be marked with an outstanding query or an illegal data value. If either or both exist, it will not be possible to save the page with status Final. |
| Solution: |
Review the page for any outstanding queries (blue fields) and/or
illegal data values (red fields). Correct those problems
or save the page using Pending or
Incomplete status.
|
| Message: | Error in saving record changes. Cause: A valid date/time stamp could not be created. |
| Possible Cause: | DFexplore cannot obtain a valid date and time from the local computer, or the value obtained is more than 48 hours ahead or behind the value obtained from the study database server. |
| Solution: | Update the date and/or time on the local computer. |
| Message: | Field field_name: storing value field_value (which contains illegal/extra characters) into variable has altered the value. |
| Possible Cause: | The field value stored in the study database is different from the value displayed in the field widget on screen. The database value may not match the field format, or may be larger than the current field store length. The study setup specifications may have been changed to make previously entered values incompatible with the current field specifications. |
| Solution: | Re-enter the specified fields with values compatible with the current field properties and save the record to the study database. |
This section describes the standard DFdiscover programs available for both adhoc record selection and task definition.
Program DFmkdrf.jnl processes the study journal files and can be used to identify records entered by specified users during specified times with specified criteria. Its output includes all records that match the specified criteria, but any given user will only see those records they have permission to get. The program usage message follows.
DFmkdrf.jnl - make or load a DFdiscover Retrieval File
USAGE: DFmkdrf.jnl [ DFNUM ] [-t date1-date2 | -days #]
[-u include_users] [-xu exclude_users]
[-v levels] [-s statuses] [-I IDs] [-S SEQs] [-P plates]
[-image yes|no] [-d 1|2] [-cv levels] [-cs statuses]
[-records #] [-cases #] [-put drfname] [-h header]
[-get drfname] [-test]
OPTIONS:
DFNUM ... DFdiscover study number may be 1st argument or set in
-t yymmdd-yymmdd ... selection period: dates during which records were saved
-days # ... select records saved in the past # days
-u list of users ... select records saved by specified users
-xu list of users ... exclude records saved by specified users
-v # #-# ... select records saved at specified validation levels (0-7)
-s status ... select statuses: final,incomplete,pending,missed
-I # #-# ... select subject IDs
-S # #-# ... select visit numbers
-P # #-# ... select plate numbers
-image yes|no ... select records with images only, or without images only
-d 1 ... deselect if criteria no longer apply at end of selection period
-d 2 ... deselect if criteria no longer apply now (journal's end)
-cv # #-# ... deselect records not currently at specified validation levels (0-7)
-cs status ... deselect records not currently at the specified statuses
-records # ... maximum number of data records to be included in the drf file
-cases # ... maximum number of subjects to be included in the drf file
-put drfname ... write output to a specified drf file in the study drf folder
-h header ... include a descriptive header/title for the drf file
-get drfname ... load an existing drf file from the study drf folder
-test ... check and display record selection options then quit
NOTES:
1. DFNUM does not need to be specified when running DFmkdrf.jnl in DFexplore; or if
environment variable DFNUM is set to the study number when running shell scripts.
2. Input: DFmkdrf.jnl reads the study journal files and thus will not generate correct
output if any of the journals have been removed or truncated.
3. Output: a DRF record is created for journal records that meet all selection options
at some point in the specified time period:
a) -d 0: even if these records no longer meet the selection options (default), or
b) -d 1: if they still meet the selection options at the end of the time period, or
c) -d 2: if they still meet the selection options now.
4. A DRF record is not created for any record deleted after meeting the selection
criteria because a deleted record cannot be retrieved from the study database.
5. If the keys (ID,Visit,Plate) are changed after a record meets the selection criteria,
a DRF record will be created for both the old keys and the new keys if they both
correspond to a current data record.
6. The record selection period may be specified using:
yymmdd-yymmdd or yymmdd-today ... a date range, or
yymmdd or today ... a single date
7. If the -drf option is not specified output is written to standard out.
8. If the -cases and -records options are both specified, -cases has priority
9. When running DFmkdrf.ec from the command line, you need to set the following
environment variables: DFSERVER, DFUSER, DFPASSWD and DFNUM to the values
you would use if you were logging into DFexplore via the login dialog.
DFNUM can also be passed as the first argument to DFmkdrf.jnl on the command
line as shown in the examples below.
EXAMPLES:
Output DRF records for data records in study 253 that were saved with associated
images by jack or dianne at level 1 in Nov. 2017, regardless of whether these
records were subsequently saved by someone else or at different levels or without
an associated image.
DFmkdrf.jnl 253 -image yes -u jack,dianne -v 1 -t 171101-171130
Repeat the above but only create DRF records if the selection criteria remain in
effect now, i.e. deselect any records that no longer meet the selection criteria at
the end of the audit trail.
DFmkdrf.jnl 253 -image yes -u jack,dianne -v 1 -t 171101-171130 -d 2
Get records saved at level 3 by jack which are currently back at level 1
DFmkdrf.jnl 253 -u jack -v 3 -cv 1
Create a DRF file named myTest.drf for data records in study 253 which were saved
in the past 10 days with visit numbers 1,2 or 50-59 and record status = incomplete
by someone other than the current user.
DFmkdrf.jnl 253 -days 10 -S 1,2,50-59 -s incomplete -xu whoami -put myTest.drf
Load DFunexpected.drf, a DRF file created by DF_QCupdate and stored in the study drf folder.
DFmkdrf.jnl 253 -get DFunexpected.drf
Program DFmkdrf.ec creates a DFbatch file and runs it to identify records with edit checks that would display a message, create or edit a query or modify a data field were they to be run interactively. No changes are made to data or metadata. The output is a data retrieval file listing the records that met the specified criteria. Any given user will only see those records they have permission to get. The program usage message follows.
DFmkdrf.ec - make DRF records by running DFbatch to execute specified edit checks
USAGE: DFmkdrf.ec [ DFNUM ] -P plates -E editchecks [-v levels -s statuses -I IDs -S SEQs]
[-P another batch specification] [-which] [-warn]
OPTIONS:
DFNUM ... DFdiscover study number
-P Plates ... plate specification starts each new batch specification
-E Edit checks ... edit check names to be executed on the specified plates
-v # #-# ... select records by specified validation levels (0-7)
-s status ... select records by record status final,incomplete,pending,missed
-I # #-# ... select records by subject IDs
-S # #-# ... select records by visit numbers
-which msg qc data ... determines EC events that trigger creation of a DRF record
-warn ... display any warning messages generated by DFbatch
-u ... print this usage message and quit
NOTES:
1. DFexplore uses environment variable DFNUM which is set to the current study number.
Only specify DFNUM on the command line when running DFmkdrf.ec from a shell script
or terminal session where DFNUM is not set.
2. Each batch specification must begin with the -P and -E options, in that order.
3. Use -E ALL or -E all to include all edit checks on the specified plates.
4. The -which option determines the conditions under which a DRF record is created.
Edit checks are executed with APPLY=none so no changes are made to the database.
Instead a DRF record is created for the current page if the edit check would do
the following with APPLY turned on:
msg - execute a message function: dferror, dfwarning, dfmessage
qc - create a new query or edit an existing one
data - modify a data field
The default value for the -which option is msg qc data, i.e. all 3 triggers apply.
5. The -which option applies to all batches. Only 1 -which option can be specified.
6. Temporary files are created in the study work directory and then removed.
7. User permissions are applied.
8. When running DFmkdrf.ec from the command line, you need to set the following
environment variables: DFSERVER, DFUSER and DFPASSWD to the values you
would use if you were logging into DFexplore via the login dialog.
EXAMPLES:
Write DRF records to standard out for study 253 if edit check test1 or test2 on plates
1-3 would display a message, add or modify a query or make any changes to a data field.
DFmkdrf.ec 253 -P 1-3 -E test1,test2
Same as the first example but only trigger these edit checks on plate 1 and only for
data records that have status final and are at validation levels 3-6.
DFmkdrf.ec 253 -P 1 -E test1,test2 -s final -v 3-6
Same as previous example but trigger test1 on all plate 1 records and test2 on plate 2-3
records that have status final and are at validation levels 3-6.
DFmkdrf.ec 253 -P 1 -E test1 -P 2-3 -E test2 -s final -v 3-6
Same as the previous example but edit checks test1 and test2 only generate a DRF record
if they would have created a new query or modified an existing query.
DFmkdrf.ec 253 -P 1 -E test1 -P 2-3 -E test2 -s final -v 3-6 -which qc
Create DRF records for any edit check that would change a data field.
DFmkdrf.ec 253 -P 1-499 -E ALL -which data
DFexplore supports retrieval of subject records based on cross plate criteria. When you click next to the subject ID in a record selection dialog, the subject selection dialog is displayed containing the first subject selection criterion.
To add other criterion, click . To remove a selected criterion, click . To see how many subjects match a criterion, click . To create an intersection of each set of subjects matching a given criterion, set the selection mode to match ALL of these criteria. To create a union of each set of subjects matching a given criterion, set the selection mode to match ANY of these criteria. In either case, the number of subjects in the set is displayed at the bottom of the subject selection dialog.
In this example, 2 subjects matched criterion 1, 5 subjects matched criterion 2, and 6 subjects matched either criteria. Click to return to the record selection dialog.
Data can be exported in CDISC ODM format. Select > to display the specification dialog.
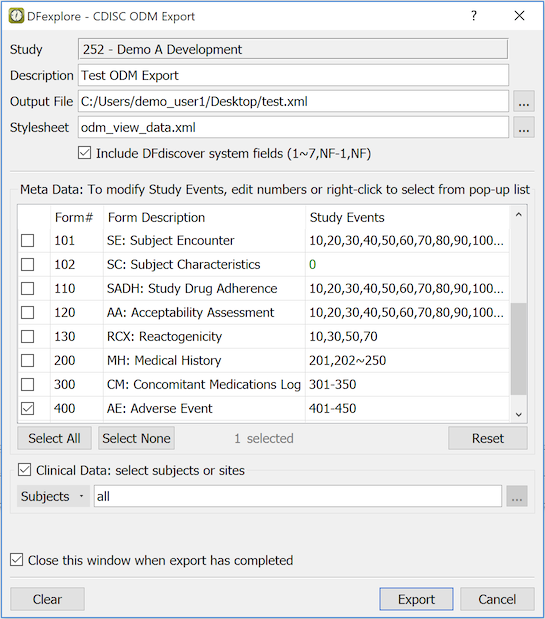
In the dialog, an Output File and at least one visit and plate are required. All plates for which you have permission are listed in the spreadsheet table. If a visit record defined in DFvisit_map is a single visit, the visit number in the Study Events column will be green. This green visit number cell is not selectable nor editable. A tool tip will show the visit description. For a range of visits, the visit cells are black and can be modified by typing visit numbers or selecting from the popup list by right-clicking it. If the visit list range is invalid the value becomes red.
Check Include DFdiscover system fields to include
a module named DFSYSTEM as the first module in each plate.
Metadata can be exported alone (do not check Clinical Data) or with plate data (check Clinical Data).
The output of Metadata will be in the order defined in DFvisit_map.
The plate data will contain completed data only. Fields that are blank, or contain missing value codes, or check/choice fields with the Not Checked code will not be written to the output.
DFdiscover field types will map to ODM types as follows: Number to integer/float, VAS to integer/float, Check/Choice to integer, Date/Time to text, String to text.
DFdiscover software uses several third-party software components as part of its server side and/or client tools.
The copyright information for each is provided below. If you would like to receive source codes of these third-party components, please send us your request at <support@datafax.com>.
Copyright Copyright © 1994-2011, OFFIS e.V. All rights reserved.
This software and supporting documentation were developed by
OFFIS e.V.
R&D Division Health
Eschereg 2
26121 Oldenburg, Germany
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
Neither the name of OFFIS nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Copyright Copyright © 2009-2014 Petri Lehtinen <petri&digip.org>
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Copyright Copyright © 1991 Bell Communications Research, Inc. (Bellcore)
Permission to use, copy, modify, and distribute this material for any purpose and without fee is hereby granted, provided that the above copyright notice and this permission notice appear in all copies, and that the name of Bellcore not be used in advertising or publicity pertaining to this material without the specific, prior written permission of an authorized representative of Bellcore. BELLCORE MAKES NO REPRESENTATIONS ABOUT THE ACCURACY OR SUITABILITY OF THIS MATERIAL FOR ANY PURPOSE. IT IS PROVIDED “AS IS”, WITHOUT ANY EXPRESS OR IMPLIED WARRANTIES.
Copyright Copyright © 1991-2, RSA Data Security, Inc. Created 1991. All rights reserved. License to copy and use this software is granted provided that it is identified as the “RSA Data Security, Inc. MD5 Message-Digest Algorithm” in all material mentioning or referencing this software or this function. License is also granted to make and use derivative works provided that such works are identified as “derived from the RSA Data Security, Inc. MD5 Message-Digest Algorithm” in all material mentioning or referencing the derived work. RSA Data Security, Inc. makes no representations concerning either the merchantability of this software or the suitability of this software for any particular purpose. It is provided “as is” without express or implied warranty of any kind. These notices must be retained in any copies of any part of this documentation and/or software.
Copyright © Copyright 1993,1994 by Carnegie Mellon University All Rights Reserved.
Permission to use, copy, modify, distribute, and sell this software and its documentation for any purpose is hereby granted without fee, provided that the above copyright notice appear in all copies and that both that copyright notice and this permission notice appear in supporting documentation, and that the name of Carnegie Mellon University not be used in advertising or publicity pertaining to distribution of the software without specific, written prior permission. Carnegie Mellon University makes no representations about the suitability of this software for any purpose. It is provided “as is” without express or implied warranty.
CARNEGIE MELLON UNIVERSITY DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS, IN NO EVENT SHALL CARNEGIE MELLON UNIVERSITY BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
Copyright Copyright © 1988-1997 Sam Leffler Copyright Copyright © 1991-1997 Silicon Graphics, Inc.
Permission to use, copy, modify, distribute, and sell this software and its documentation for any purpose is hereby granted without fee, provided that (i) the above copyright notices and this permission notice appear in all copies of the software and related documentation, and (ii) the names of Sam Leffler and Silicon Graphics may not be used in any advertising or publicity relating to the software without the specific, prior written permission of Sam Leffler and Silicon Graphics.
THE SOFTWARE IS PROVIDED “AS-IS” AND WITHOUT WARRANTY OF ANY KIND, EXPRESS, IMPLIED OR OTHERWISE, INCLUDING WITHOUT LIMITATION, ANY WARRANTY OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. IN NO EVENT SHALL SAM LEFFLER OR SILICON GRAPHICS BE LIABLE FOR ANY SPECIAL, INCIDENTAL, INDIRECT OR CONSEQUENTIAL DAMAGES OF ANY KIND, OR ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER OR NOT ADVISED OF THE POSSIBILITY OF DAMAGE, AND ON ANY THEORY OF LIABILITY, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
Portions Copyright © 1996-2019, PostgreSQL Global Development Group Portions Copyright © 1994, The Regents of the University of California
Permission to use, copy, modify, and distribute this software and its documentation for any purpose, without fee, and without a written agreement is hereby granted, provided that the above copyright notice and this paragraph and the following two paragraphs appear in all copies.
IN NO EVENT SHALL THE UNIVERSITY OF CALIFORNIA BE LIABLE TO ANY PARTY FOR DIRECT, INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, INCLUDING LOST PROFITS, ARISING OUT OF THE USE OF THIS SOFTWARE AND ITS DOCUMENTATION, EVEN IF THE UNIVERSITY OF CALIFORNIA HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
THE UNIVERSITY OF CALIFORNIA SPECIFICALLY DISCLAIMS ANY WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE SOFTWARE PROVIDED HEREUNDER IS ON AN "AS IS" BASIS, AND THE UNIVERSITY OF CALIFORNIA HAS NO OBLIGATIONS TO PROVIDE MAINTENANCE, SUPPORT, UPDATES, ENHANCEMENTS, OR MODIFICATIONS.
Copyright Copyright © 1998-2019 The OpenSSL Project. All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
All advertising materials mentioning features or use of this software must display the following acknowledgment: “This product includes software developed by the OpenSSL Project for use in .the OpenSSL Toolkit.” (http://www.openssl.org/)
The names “OpenSSL Toolkit” and "OpenSSL Project" must not be used to endorse or promote products derived from this software without prior written permission. For written permission, please contact openssl-core@openssl.org.
Products derived from this software may not be called “OpenSSL” nor may “OpenSSL” appear in their names without prior written permission of the OpenSSL Project.
Redistributions of any form whatsoever must retain the following acknowledgment: “This product includes software developed by the OpenSSL Project for use in the OpenSSL Toolkit. (http://www.openssl.org)”
THIS SOFTWARE IS PROVIDED BY THE OpenSSL PROJECT “AS IS” AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE OpenSSL PROJECT OR ITS CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
This product includes cryptographic software written by Eric Young (<eay@cryptsoft.com>). This product includes software written by Tim Hudson (<tjh@cryptsoft.com>).
Copyright Copyright © 1995-1998 Eric Young (<eay@cryptsoft.com>)
All rights reserved.
This package is an SSL implementation written
by Eric Young (<eay@cryptsoft.com>).
The implementation was written so as to conform with Netscapes SSL.
This library is free for commercial and non-commercial use as long as
the following conditions are aheared to. The following conditions
apply to all code found in this distribution, be it the RC4, RSA,
lhash, DES, etc., code; not just the SSL code. The SSL documentation
included with this distribution is covered by the same copyright terms
except that the holder is Tim Hudson (<tjh@cryptsoft.com>).
Copyright remains Eric Young's, and as such any Copyright notices in the code are not to be removed. If this package is used in a product, Eric Young should be given attribution as the author of the parts of the library used. This can be in the form of a textual message at program startup or in documentation (online or textual) provided with the package.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
-
Redistributions of source code must retain the copyright notice, this list of conditions and the following disclaimer.
Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
All advertising materials mentioning features or use of this software must display the following acknowledgement: “This product includes cryptographic software written by Eric Young (
<eay@cryptsoft.com>)” The word “cryptographic” can be left out if the rouines from the library being used are not cryptographic related :-).If you include any Windows specific code (or a derivative thereof) from the apps directory (application code) you must include an acknowledgement: “This product includes software written by Tim Hudson (
<tjh@cryptsoft.com>)”
THIS SOFTWARE IS PROVIDED BY ERIC YOUNG “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE AUTHOR OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
The licence and distribution terms for any publically available version or derivative of this code cannot be changed. i.e. this code cannot simply be copied and put under another distribution licence [including the GNU Public Licence.]
GNU GENERAL PUBLIC LICENSE Version 2, June 1991
http://www.gnu.org/licenses/gpl-2.0.html
Copyright Copyright © 1989, 1991 Free Software Foundation, Inc.
51 Franklin Street, Fifth Floor,
Boston, MA 02110-1301, USA
Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
The licenses for most software are designed to take away your freedom to share and change it. By contrast, the GNU General Public License is intended to guarantee your freedom to share and change free software--to make sure the software is free for all its users. This General Public License applies to most of the Free Software Foundation's software and to any other program whose authors commit to using it. (Some other Free Software Foundation software is covered by the GNU Lesser General Public License instead.) You can apply it to your programs, too.
When we speak of free software, we are referring to freedom, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for this service if you wish), that you receive source code or can get it if you want it, that you can change the software or use pieces of it in new free programs; and that you know you can do these things.
To protect your rights, we need to make restrictions that forbid anyone to deny you these rights or to ask you to surrender the rights. These restrictions translate to certain responsibilities for you if you distribute copies of the software, or if you modify it.
For example, if you distribute copies of such a program, whether gratis or for a fee, you must give the recipients all the rights that you have. You must make sure that they, too, receive or can get the source code. And you must show them these terms so they know their rights.
We protect your rights with two steps: (1) copyright the software, and (2) offer you this license which gives you legal permission to copy, distribute and/or modify the software.
Also, for each author's protection and ours, we want to make certain that everyone understands that there is no warranty for this free software. If the software is modified by someone else and passed on, we want its recipients to know that what they have is not the original, so that any problems introduced by others will not reflect on the original authors' reputations.
Finally, any free program is threatened constantly by software patents. We wish to avoid the danger that redistributors of a free program will individually obtain patent licenses, in effect making the program proprietary. To prevent this, we have made it clear that any patent must be licensed for everyone's free use or not licensed at all.
The precise terms and conditions for copying, distribution and modification follow.
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
This License applies to any program or other work which contains a notice placed by the copyright holder saying it may be distributed under the terms of this General Public License. The “Program”, below, refers to any such program or work, and a “work based on the Program” means either the Program or any derivative work under copyright law: that is to say, a work containing the Program or a portion of it, either verbatim or with modifications and/or translated into another language. (Hereinafter, translation is included without limitation in the term “modification”.) Each licensee is addressed as “you”.
Activities other than copying, distribution and modification are not covered by this License; they are outside its scope. The act of running the Program is not restricted, and the output from the Program is covered only if its contents constitute a work based on the Program (independent of having been made by running the Program). Whether that is true depends on what the Program does.
You may copy and distribute verbatim copies of the Program's source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice and disclaimer of warranty; keep intact all the notices that refer to this License and to the absence of any warranty; and give any other recipients of the Program a copy of this License along with the Program.
You may charge a fee for the physical act of transferring a copy, and you may at your option offer warranty protection in exchange for a fee.
You may modify your copy or copies of the Program or any portion of it, thus forming a work based on the Program, and copy and distribute such modifications or work under the terms of Section 1 above, provided that you also meet all of these conditions:
You must cause the modified files to carry prominent notices stating that you changed the files and the date of any change.
-
You must cause any work that you distribute or publish, that in whole or in part contains or is derived from the Program or any part thereof, to be licensed as a whole at no charge to all third parties under the terms of this License.
If the modified program normally reads commands interactively when run, you must cause it, when started running for such interactive use in the most ordinary way, to print or display an announcement including an appropriate copyright notice and a notice that there is no warranty (or else, saying that you provide a warranty) and that users may redistribute the program under these conditions, and telling the user how to view a copy of this License. (Exception: if the Program itself is interactive but does not normally print such an announcement, your work based on the Program is not required to print an announcement.) These requirements apply to the modified work as a whole. If identifiable sections of that work are not derived from the Program, and can be reasonably considered independent and separate works in themselves, then this License, and its terms, do not apply to those sections when you distribute them as separate works. But when you distribute the same sections as part of a whole which is a work based on the Program, the distribution of the whole must be on the terms of this License, whose permissions for other licensees extend to the entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest your rights to work written entirely by you; rather, the intent is to exercise the right to control the distribution of derivative or collective works based on the Program.
In addition, mere aggregation of another work not based on the Program with the Program (or with a work based on the Program) on a volume of a storage or distribution medium does not bring the other work under the scope of this License.
You may copy and distribute the Program (or a work based on it, under Section 2) in object code or executable form under the terms of Sections 1 and 2 above provided that you also do one of the following:
Accompany it with the complete corresponding machine-readable source code, which must be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
-
Accompany it with a written offer, valid for at least three years, to give any third party, for a charge no more than your cost of physically performing source distribution, a complete machine-readable copy of the corresponding source code, to be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange; or,
-
Accompany it with the information you received as to the offer to distribute corresponding source code. (This alternative is allowed only for noncommercial distribution and only if you received the program in object code or executable form with such an offer, in accord with Subsection b above.) The source code for a work means the preferred form of the work for making modifications to it. For an executable work, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the executable. However, as a special exception, the source code distributed need not include anything that is normally distributed (in either source or binary form) with the major components (compiler, kernel, and so on) of the operating system on which the executable runs, unless that component itself accompanies the executable.
If distribution of executable or object code is made by offering access to copy from a designated place, then offering equivalent access to copy the source code from the same place counts as distribution of the source code, even though third parties are not compelled to copy the source along with the object code.
You may not copy, modify, sublicense, or distribute the Program except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense or distribute the Program is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
You are not required to accept this License, since you have not signed it. However, nothing else grants you permission to modify or distribute the Program or its derivative works. These actions are prohibited by law if you do not accept this License. Therefore, by modifying or distributing the Program (or any work based on the Program), you indicate your acceptance of this License to do so, and all its terms and conditions for copying, distributing or modifying the Program or works based on it.
Each time you redistribute the Program (or any work based on the Program), the recipient automatically receives a license from the original licensor to copy, distribute or modify the Program subject to these terms and conditions. You may not impose any further restrictions on the recipients' exercise of the rights granted herein. You are not responsible for enforcing compliance by third parties to this License.
-
If, as a consequence of a court judgment or allegation of patent infringement or for any other reason (not limited to patent issues), conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot distribute so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not distribute the Program at all. For example, if a patent license would not permit royalty-free redistribution of the Program by all those who receive copies directly or indirectly through you, then the only way you could satisfy both it and this License would be to refrain entirely from distribution of the Program.
If any portion of this section is held invalid or unenforceable under any particular circumstance, the balance of the section is intended to apply and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any patents or other property right claims or to contest validity of any such claims; this section has the sole purpose of protecting the integrity of the free software distribution system, which is implemented by public license practices. Many people have made generous contributions to the wide range of software distributed through that system in reliance on consistent application of that system; it is up to the author/donor to decide if he or she is willing to distribute software through any other system and a licensee cannot impose that choice.
This section is intended to make thoroughly clear what is believed to be a consequence of the rest of this License.
If the distribution and/or use of the Program is restricted in certain countries either by patents or by copyrighted interfaces, the original copyright holder who places the Program under this License may add an explicit geographical distribution limitation excluding those countries, so that distribution is permitted only in or among countries not thus excluded. In such case, this License incorporates the limitation as if written in the body of this License.
The Free Software Foundation may publish revised and/or new versions of the General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Program specifies a version number of this License which applies to it and "any later version", you have the option of following the terms and conditions either of that version or of any later version published by the Free Software Foundation. If the Program does not specify a version number of this License, you may choose any version ever published by the Free Software Foundation.
If you wish to incorporate parts of the Program into other free programs whose distribution conditions are different, write to the author to ask for permission. For software which is copyrighted by the Free Software Foundation, write to the Free Software Foundation; we sometimes make exceptions for this. Our decision will be guided by the two goals of preserving the free status of all derivatives of our free software and of promoting the sharing and reuse of software generally. NO WARRANTY
BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE PROGRAM “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
-
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
The files in the base, psi, lib, toolbin, examples, doc and man directories (folders) and any subdirectories (sub-folders) thereof are part of GPL Ghostscript.
The files in the Resource directory and any subdirectories thereof are also part of GPL Ghostscript, with the explicit exception of the files in the CMap subdirectory (except “Identity-UTF16-H”, which is part of GPL Ghostscript). The CMap files are copyright Adobe Systems Incorporated and covered by a separate, GPL compatible license.
The files under the jpegxr directory and any subdirectories thereof are distributed under a no cost, open source license granted by the ITU/ISO/IEC but it is not GPL compatible - see jpegxr/COPYRIGHT.txt for details.
GPL Ghostscript is free software; you can redistribute it and/or modify it under the terms the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
GPL Ghostscript is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program so you can know your rights and responsibilities. It should be in a file named doc/COPYING. If not, write to the
Free Software Foundation, Inc., 59 Temple Place Suite 330, Boston, MA
02111-1307, USA.
GPL Ghostscript contains an implementation of techniques covered by US Patents 5,055,942 and 5,917,614, and corresponding international patents. These patents are licensed for use with GPL Ghostscript under the following grant:
Whereas, Raph Levien (hereinafter “Inventor”) has obtained patent protection for related technology (hereinafter “Patented Technology”), Inventor wishes to aid the the GNU free software project in achieving its goals, and Inventor also wishes to increase public awareness of Patented Technology, Inventor hereby grants a fully paid up, nonexclusive, royalty free license to practice the patents listed below (“the Patents”) if and only if practiced in conjunction with software distributed under the terms of any version of the GNU General Public License as published by the
Free Software Foundation, 59 Temple Place, Suite
330, Boston, MA 02111.
Inventor reserves all other rights, including without limitation, licensing for software not distributed under the GNU General Public License.
5055942 Photographic image reproduction device using digital halftoning to para images allowing adjustable coarseness 5917614 Method and apparatus for error diffusion paraing of images with improved smoothness in highlight and shadow regions
GNU LESSER GENERAL PUBLIC LICENSE Version 2.1, February 1999 http://www.gnu.org/licenses/lgpl-2.1.html
Copyright Copyright © 1991, 1999
Free Software Foundation, Inc.
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
[This is the first released version of the Lesser GPL. It also counts as the successor of the GNU Library Public License, version 2, hence the version number 2.1.]
Preamble The licenses for most software are designed to take away your freedom to share and change it. By contrast, the GNU General Public Licenses are intended to guarantee your freedom to share and change free software--to make sure the software is free for all its users.
This license, the Lesser General Public License, applies to some specially designated software packages--typically libraries--of the Free Software Foundation and other authors who decide to use it. You can use it too, but we suggest you first think carefully about whether this license or the ordinary General Public License is the better strategy to use in any particular case, based on the explanations below.
When we speak of free software, we are referring to freedom of use, not price. Our General Public Licenses are designed to make sure that you have the freedom to distribute copies of free software (and charge for this service if you wish); that you receive source code or can get it if you want it; that you can change the software and use pieces of it in new free programs; and that you are informed that you can do these things.
To protect your rights, we need to make restrictions that forbid distributors to deny you these rights or to ask you to surrender these rights. These restrictions translate to certain responsibilities for you if you distribute copies of the library or if you modify it.
For example, if you distribute copies of the library, whether gratis or for a fee, you must give the recipients all the rights that we gave you. You must make sure that they, too, receive or can get the source code. If you link other code with the library, you must provide complete object files to the recipients, so that they can relink them with the library after making changes to the library and recompiling it. And you must show them these terms so they know their rights.
We protect your rights with a two-step method:
we copyright the library, and
-
we offer you this license, which gives you legal permission to copy, distribute and/or modify the library.
To protect each distributor, we want to make it very clear that there is no warranty for the free library. Also, if the library is modified by someone else and passed on, the recipients should know that what they have is not the original version, so that the original author's reputation will not be affected by problems that might be introduced by others.
Finally, software patents pose a constant threat to the existence of any free program. We wish to make sure that a company cannot effectively restrict the users of a free program by obtaining a restrictive license from a patent holder. Therefore, we insist that any patent license obtained for a version of the library must be consistent with the full freedom of use specified in this license.
Most GNU software, including some libraries, is covered by the ordinary GNU General Public License. This license, the GNU Lesser General Public License, applies to certain designated libraries, and is quite different from the ordinary General Public License. We use this license for certain libraries in order to permit linking those libraries into non-free programs.
When a program is linked with a library, whether statically or using a shared library, the combination of the two is legally speaking a combined work, a derivative of the original library. The ordinary General Public License therefore permits such linking only if the entire combination fits its criteria of freedom. The Lesser General Public License permits more lax criteria for linking other code with the library.
We call this license the "Lesser" General Public License because it does Less to protect the user's freedom than the ordinary General Public License. It also provides other free software developers Less of an advantage over competing non-free programs. These disadvantages are the reason we use the ordinary General Public License for many libraries. However, the Lesser license provides advantages in certain special circumstances.
For example, on rare occasions, there may be a special need to encourage the widest possible use of a certain library, so that it becomes a de-facto standard. To achieve this, non-free programs must be allowed to use the library. A more frequent case is that a free library does the same job as widely used non-free libraries. In this case, there is little to gain by limiting the free library to free software only, so we use the Lesser General Public License.
In other cases, permission to use a particular library in non-free programs enables a greater number of people to use a large body of free software. For example, permission to use the GNU C Library in non-free programs enables many more people to use the whole GNU operating system, as well as its variant, the GNU/Linux operating system.
Although the Lesser General Public License is Less protective of the users' freedom, it does ensure that the user of a program that is linked with the Library has the freedom and the wherewithal to run that program using a modified version of the Library.
The precise terms and conditions for copying, distribution and modification follow. Pay close attention to the difference between a “work based on the library” and a “work that uses the library”. The former contains code derived from the library, whereas the latter must be combined with the library in order to run.
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
-
This License Agreement applies to any software library or other program which contains a notice placed by the copyright holder or other authorized party saying it may be distributed under the terms of this Lesser General Public License (also called “this License”). Each licensee is addressed as “you”.
A “library” means a collection of software functions and/or data prepared so as to be conveniently linked with application programs (which use some of those functions and data) to form executables.
The “Library”, below, refers to any such software library or work which has been distributed under these terms. A “work based on the Library” means either the Library or any derivative work under copyright law: that is to say, a work containing the Library or a portion of it, either verbatim or with modifications and/or translated straightforwardly into another language. (Hereinafter, translation is included without limitation in the term “modification”.)
“Source code” for a work means the preferred form of the work for making modifications to it. For a library, complete source code means all the source code for all modules it contains, plus any associated interface definition files, plus the scripts used to control compilation and installation of the library.
Activities other than copying, distribution and modification are not covered by this License; they are outside its scope. The act of running a program using the Library is not restricted, and output from such a program is covered only if its contents constitute a work based on the Library (independent of the use of the Library in a tool for writing it). Whether that is true depends on what the Library does and what the program that uses the Library does.
You may copy and distribute verbatim copies of the Library's complete source code as you receive it, in any medium, provided that you conspicuously and appropriately publish on each copy an appropriate copyright notice and disclaimer of warranty; keep intact all the notices that refer to this License and to the absence of any warranty; and distribute a copy of this License along with the Library.
You may charge a fee for the physical act of transferring a copy, and you may at your option offer warranty protection in exchange for a fee.
You may modify your copy or copies of the Library or any portion of it, thus forming a work based on the Library, and copy and distribute such modifications or work under the terms of Section 1 above, provided that you also meet all of these conditions:
The modified work must itself be a software library.
You must cause the files modified to carry prominent notices stating that you changed the files and the date of any change.
You must cause the whole of the work to be licensed at no charge to all third parties under the terms of this License.
If a facility in the modified Library refers to a function or a table of data to be supplied by an application program that uses the facility, other than as an argument passed when the facility is invoked, then you must make a good faith effort to ensure that, in the event an application does not supply such function or table, the facility still operates, and performs whatever part of its purpose remains meaningful. (For example, a function in a library to compute square roots has a purpose that is entirely well-defined independent of the application. Therefore, Subsection 2d requires that any application-supplied function or table used by this function must be optional: if the application does not supply it, the square root function must still compute square roots.)
These requirements apply to the modified work as a whole. If identifiable sections of that work are not derived from the Library, and can be reasonably considered independent and separate works in themselves, then this License, and its terms, do not apply to those sections when you distribute them as separate works. But when you distribute the same sections as part of a whole which is a work based on the Library, the distribution of the whole must be on the terms of this License, whose permissions for other licensees extend to the entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest your rights to work written entirely by you; rather, the intent is to exercise the right to control the distribution of derivative or collective works based on the Library.
In addition, mere aggregation of another work not based on the Library with the Library (or with a work based on the Library) on a volume of a storage or distribution medium does not bring the other work under the scope of this License.
You may opt to apply the terms of the ordinary GNU General Public License instead of this License to a given copy of the Library. To do this, you must alter all the notices that refer to this License, so that they refer to the ordinary GNU General Public License, version 2, instead of to this License. (If a newer version than version 2 of the ordinary GNU General Public License has appeared, then you can specify that version instead if you wish.) Do not make any other change in these notices.
Once this change is made in a given copy, it is irreversible for that copy, so the ordinary GNU General Public License applies to all subsequent copies and derivative works made from that copy.
This option is useful when you wish to copy part of the code of the Library into a program that is not a library.
You may copy and distribute the Library (or a portion or derivative of it, under Section 2) in object code or executable form under the terms of Sections 1 and 2 above provided that you accompany it with the complete corresponding machine-readable source code, which must be distributed under the terms of Sections 1 and 2 above on a medium customarily used for software interchange.
If distribution of object code is made by offering access to copy from a designated place, then offering equivalent access to copy the source code from the same place satisfies the requirement to distribute the source code, even though third parties are not compelled to copy the source along with the object code.
A program that contains no derivative of any portion of the Library, but is designed to work with the Library by being compiled or linked with it, is called a "work that uses the Library". Such a work, in isolation, is not a derivative work of the Library, and therefore falls outside the scope of this License.
However, linking a "work that uses the Library" with the Library creates an executable that is a derivative of the Library (because it contains portions of the Library), rather than a “work that uses the library”. The executable is therefore covered by this License. Section 6 states terms for distribution of such executables.
When a “work that uses the Library” uses material from a header file that is part of the Library, the object code for the work may be a derivative work of the Library even though the source code is not. Whether this is true is especially significant if the work can be linked without the Library, or if the work is itself a library. The threshold for this to be true is not precisely defined by law.
If such an object file uses only numerical parameters, data structure layouts and accessors, and small macros and small inline functions (ten lines or less in length), then the use of the object file is unrestricted, regardless of whether it is legally a derivative work. (Executables containing this object code plus portions of the Library will still fall under Section 6.)
Otherwise, if the work is a derivative of the Library, you may distribute the object code for the work under the terms of Section 6. Any executables containing that work also fall under Section 6, whether or not they are linked directly with the Library itself.
As an exception to the Sections above, you may also combine or link a "work that uses the Library" with the Library to produce a work containing portions of the Library, and distribute that work under terms of your choice, provided that the terms permit modification of the work for the customer's own use and reverse engineering for debugging such modifications.
You must give prominent notice with each copy of the work that the Library is used in it and that the Library and its use are covered by this License. You must supply a copy of this License. If the work during execution displays copyright notices, you must include the copyright notice for the Library among them, as well as a reference directing the user to the copy of this License.
Also, you must do one of these things:
Accompany the work with the complete corresponding machine-readable source code for the Library including whatever changes were used in the work (which must be distributed under Sections 1 and 2 above); and, if the work is an executable linked with the Library, with the complete machine-readable "work that uses the Library", as object code and/or source code, so that the user can modify the Library and then relink to produce a modified executable containing the modified Library. (It is understood that the user who changes the contents of definitions files in the Library will not necessarily be able to recompile the application to use the modified definitions.)
Use a suitable shared library mechanism for linking with the Library. A suitable mechanism is one that
uses at run time a copy of the library already present on the user's computer system, rather than copying library functions into the executable, and
will operate properly with a modified version of the library, if the user installs one, as long as the modified version is interface-compatible with the version that the work was made with.
Accompany the work with a written offer, valid for at least three years, to give the same user the materials specified in Subsection 6a, above, for a charge no more than the cost of performing this distribution.
If distribution of the work is made by offering access to copy from a designated place, offer equivalent access to copy the above specified materials from the same place.
-
Verify that the user has already received a copy of these materials or that you have already sent this user a copy. For an executable, the required form of the “work that uses the Library” must include any data and utility programs needed for reproducing the executable from it. However, as a special exception, the materials to be distributed need not include anything that is normally distributed (in either source or binary form) with the major components (compiler, kernel, and so on) of the operating system on which the executable runs, unless that component itself accompanies the executable.
It may happen that this requirement contradicts the license restrictions of other proprietary libraries that do not normally accompany the operating system. Such a contradiction means you cannot use both them and the Library together in an executable that you distribute.
You may place library facilities that are a work based on the Library side-by-side in a single library together with other library facilities not covered by this License, and distribute such a combined library, provided that the separate distribution of the work based on the Library and of the other library facilities is otherwise permitted, and provided that you do these two things:
Accompany the combined library with a copy of the same work based on the Library, uncombined with any other library facilities. This must be distributed under the terms of the Sections above.
Give prominent notice with the combined library of the fact that part of it is a work based on the Library, and explaining where to find the accompanying uncombined form of the same work.
You may not copy, modify, sublicense, link with, or distribute the Library except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense, link with, or distribute the Library is void, and will automatically terminate your rights under this License. However, parties who have received copies, or rights, from you under this License will not have their licenses terminated so long as such parties remain in full compliance.
You are not required to accept this License, since you have not signed it. However, nothing else grants you permission to modify or distribute the Library or its derivative works. These actions are prohibited by law if you do not accept this License. Therefore, by modifying or distributing the Library (or any work based on the Library), you indicate your acceptance of this License to do so, and all its terms and conditions for copying, distributing or modifying the Library or works based on it.
Each time you redistribute the Library (or any work based on the Library), the recipient automatically receives a license from the original licensor to copy, distribute, link with or modify the Library subject to these terms and conditions. You may not impose any further restrictions on the recipients' exercise of the rights granted herein. You are not responsible for enforcing compliance by third parties with this License.
If, as a consequence of a court judgment or allegation of patent infringement or for any other reason (not limited to patent issues), conditions are imposed on you (whether by court order, agreement or otherwise) that contradict the conditions of this License, they do not excuse you from the conditions of this License. If you cannot distribute so as to satisfy simultaneously your obligations under this License and any other pertinent obligations, then as a consequence you may not distribute the Library at all. For example, if a patent license would not permit royalty-free redistribution of the Library by all those who receive copies directly or indirectly through you, then the only way you could satisfy both it and this License would be to refrain entirely from distribution of the Library.
If any portion of this section is held invalid or unenforceable under any particular circumstance, the balance of the section is intended to apply, and the section as a whole is intended to apply in other circumstances.
It is not the purpose of this section to induce you to infringe any patents or other property right claims or to contest validity of any such claims; this section has the sole purpose of protecting the integrity of the free software distribution system which is implemented by public license practices. Many people have made generous contributions to the wide range of software distributed through that system in reliance on consistent application of that system; it is up to the author/donor to decide if he or she is willing to distribute software through any other system and a licensee cannot impose that choice.
This section is intended to make thoroughly clear what is believed to be a consequence of the rest of this License.
-
If the distribution and/or use of the Library is restricted in certain countries either by patents or by copyrighted interfaces, the original copyright holder who places the Library under this License may add an explicit geographical distribution limitation excluding those countries, so that distribution is permitted only in or among countries not thus excluded. In such case, this License incorporates the limitation as if written in the body of this License.
-
The Free Software Foundation may publish revised and/or new versions of the Lesser General Public License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns.
Each version is given a distinguishing version number. If the Library specifies a version number of this License which applies to it and "any later version", you have the option of following the terms and conditions either of that version or of any later version published by the Free Software Foundation. If the Library does not specify a license version number, you may choose any version ever published by the Free Software Foundation.
If you wish to incorporate parts of the Library into other free programs whose distribution conditions are incompatible with these, write to the author to ask for permission. For software which is copyrighted by the Free Software Foundation, write to the Free Software Foundation; we sometimes make exceptions for this. Our decision will be guided by the two goals of preserving the free status of all derivatives of our free software and of promoting the sharing and reuse of software generally.
NO WARRANTY
BECAUSE THE LIBRARY IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY FOR THE LIBRARY, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES PROVIDE THE LIBRARY "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND PERFORMANCE OF THE LIBRARY IS WITH YOU. SHOULD THE LIBRARY PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION.
IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR REDISTRIBUTE THE LIBRARY AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE THE LIBRARY (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE LIBRARY TO OPERATE WITH ANY OTHER SOFTWARE), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
Copyright © Wang Bin <wbsecg1@gmail.com>
Shanghai University->S3 Graphics->Deepin, Shanghai, China
2013-01-21
**QtAV is free software licensed under the term of LGPL v2.1. The player example is licensed under GPL v3. If you use QtAV or its constituent libraries, you must adhere to the terms of the license in question.**
Rather than repeating the text of the LGPL v2.1, the original text can be found in GNU LESSER GENERAL PUBLIC LICENSE, Version 2.1.
Most files in FFmpeg are under the GNU Lesser General Public License version 2.1 or later (LGPL v2.1+). Read the file `COPYING.LGPLv2.1` for details. Some other files have MIT/X11/BSD-style licenses. In combination the LGPL v2.1+ applies to FFmpeg.
Rather than repeating the text of the LGPL v2.1, the original text can be found in GNU LESSER GENERAL PUBLIC LICENSE, Version 2.1.
The MIT License (MIT) Copyright © 2013 Masayuki Tanaka
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Copyright 2010-2017 Mike Bostock All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: * Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. * Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution. * Neither the name of the author nor the names of contributors may be used to endorse or promote products derived from this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS “AS IS” AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.